
- The technical journey discusses the motivations, challenges, and technical solutions employed for warehouse schematization, especially a change to the wire serialization format employed in Meta’s data platform for data interchange related to Warehouse Analytics Logging.
- Here, we discuss the engineering, scaling, and nontechnical challenges of modernizing Meta’s exabyte-scale data platform by migrating to the new Tulip format.
- Schematization of data plays an important role for a data platform of this scale. It affects performance, efficiency, reliability, and developer experience at every stage of the data flow and development.
Migrations are hard. Moreover, they become much harder at Meta because of:
- Technical debt: Systems have been built over years and have various levels of dependencies and deep integrations with other systems.
- Nontechnical (soft) aspects: Walking users through the migration process with minimum friction is a fine art that needs to be honed over time and is unique to every migration.
Why did we migrate to Tulip?
Before jumping into the details of the migration story, we’d like to take a step back and try to explain the motivation and rationale for this migration.
Over time, the data platform has morphed into various forms as the needs of the company have grown. What was a modest data platform in the early days has grown into an exabyte-scale platform. Some systems serving a smaller scale began showing signs of being insufficient for the increased demands that were placed on them. Most notably, we’ve run into some concrete reliability and efficiency issues related to data (de)serialization, which has made us rethink the way we log data and revisit the ideas from first principles to address these pressing issues.
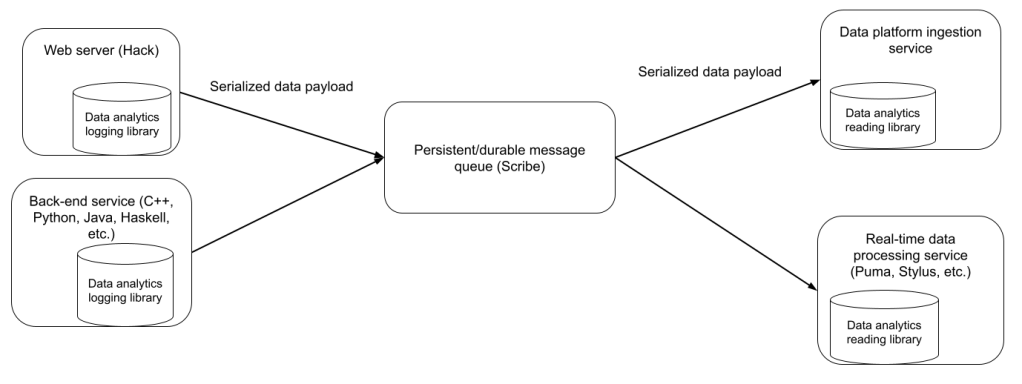
Logger is at the heart of the data platform. The system is used to log analytical and operational data to Scuba, Hive, and stream processing pipelines via Scribe. Every product and data platform team interacts with logging. The data format for logging was either Hive Text Delimited or JSON, for legacy reasons. The limitations of these formats are described in our previous article on Tulip.
Enter Tulip serialization
To address these limitations, the Tulip serialization format was developed to replace the legacy destination-specific serialization formats.
The migration outcome — charted
The charts below graphically portray the migration journey for the conversion of the serialization format to Tulip to show the progress at various stages and milestones.
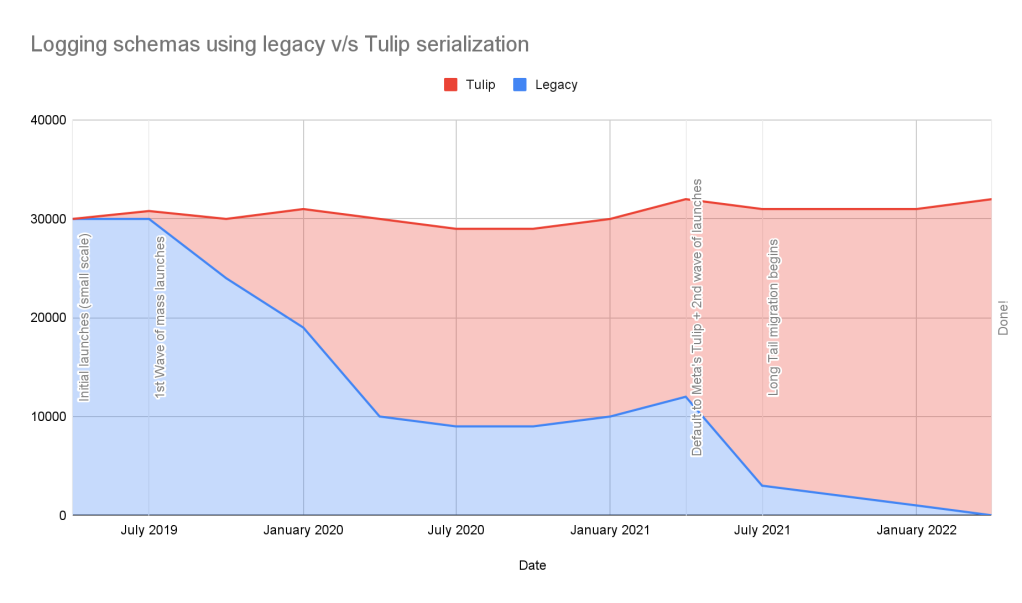
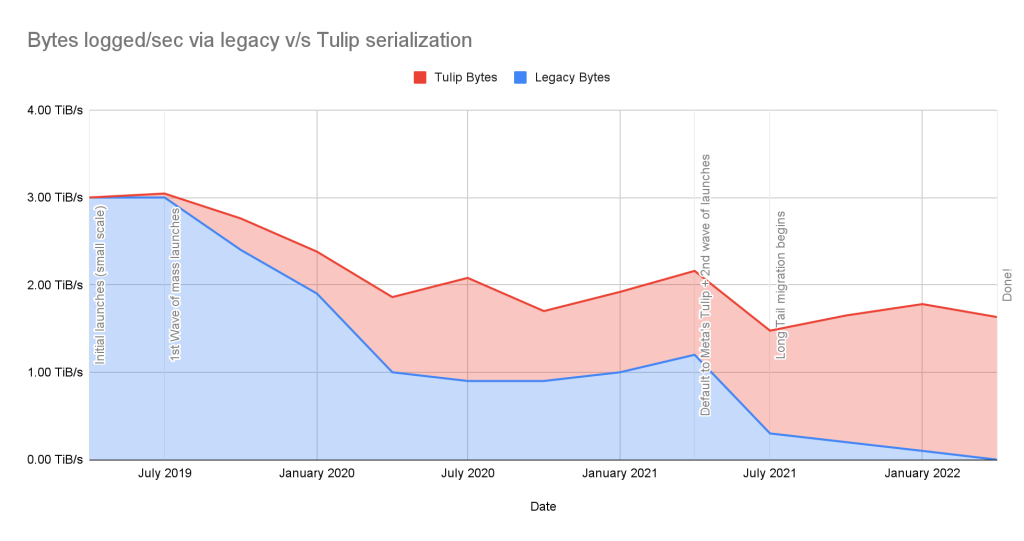
We can see that while the number of logging schemas remained roughly the same (or saw some organic growth), the bytes logged saw a significant decrease due to the change in serialization format. The details related to format specific byte savings are tabulated in the section below.
Note: The numbers in Chart 2 are extrapolated (to the overall traffic) based on the actual savings observed for the largest (by volume) five logging schemas.
The migration
Overview
We would like to present our migration journey as two distinct phases with their own perspectives.
- The planning, preparation, and experimentation phase: This phase focused on building technical solutions to help validate the migration and allow it to proceed smoothly and efficiently. Stringent automation for validation was built before any migration was performed. Data consumers had to be migrated before the producers could be migrated. A small number of white glove migrations were performed for critical teams, and these provided useful insights into what would be important in the next phase of the migration.
- The scaling phase: In this phase, the team built tooling and features based on learnings from the earlier smaller scale migration. Considering non-technical perspectives and optimizing for efficient people interactions was critical.
Planning and preparing for the migration journey
Designing the system with migration in mind helps make the migration much easier. The following engineering solutions were developed to ensure that the team was equipped with the necessary tooling and infrastructure support to switch the wire format safely and to debug issues that may arise during the migration phase in a scalable manner.
The solutions roughly fell into the following buckets:
- Wire format related: The focus for this class of solutions was to ensure minimal to zero overhead when a format switch of the serialization format is performed. This involved engineering the wire format for a smooth transition as well as arming various systems with format converters and adapters where necessary.
- Mixed mode wire format
- Data consumption
- Testing, debugging, and rollout related: This class of solutions involved building rigorous testing frameworks, debugging tools, and rollout knobs to ensure that issues could be found proactively, and when they were found in the live system, the team was equipped to stop the bleeding and to debug and/or root-cause as swiftly as possible.
- Debugging tools
- Shadow loggers
- Rate limits and partial rollout
Mixed mode wire format
Challenge: How does one ease the migration and reduce risk by not requiring the data producer(s) and consumer(s) to switch serialization formats atomically?
Solution: When flipping a single logging schema over to use the new Tulip serialization protocol to write payloads, supporting mixed mode payloads on a single scribe stream was necessary since it would be impossible to “atomically” switch all data producers over to use the new format. This also allowed the team to rate-limit the rollout of the new format serialization.
Mixed mode wire format was important for supporting the concept of shadow loggers, which were used extensively for end-to-end acceptance testing before a large-scale rollout.
The main challenge for mixed mode wire format was not being able to change the existing serialization of payloads in either Hive Text or JSON format. To work around this limitation, every Tulip serialized payload is prefixed with the 2-byte sequence 0x80 0x00, which is an invalid utf-8 sequence.
Data consumption
Challenge: In some systems, the Hive Text (or JSON) serialization format bled into the application code that ended up relying on this format for consuming payloads. This is a result of consumers breaking through the serialization format abstraction.
Solution: Two solutions addressed this challenge.
- Reader (logger counterpart for deserialization of data)
- Format conversion in consumers
Reader (logger counterpart for deserialization of data)
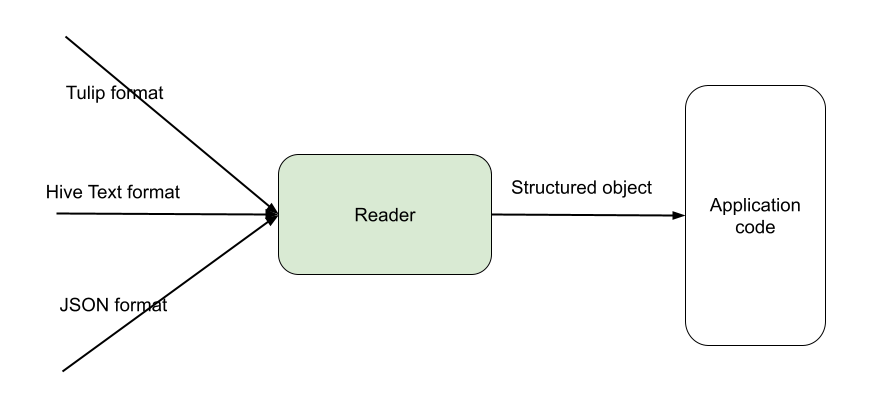
Reader is a library that converts a serialized payload into a structured object. Reader (like logger) comes in two flavors, (a) code generated and (b) generic. A reader object consumes data in any of the three formats — Tulip, Hive Text, or JSON — and produces a structured object. This allowed the team to switch consumers over to use readers before the migration commenced. Application code had to be updated to consume this structured object instead of a raw serialized line. This abstracted the wire format away from consumers of the data.
Conversion to legacy format(s) in consumers
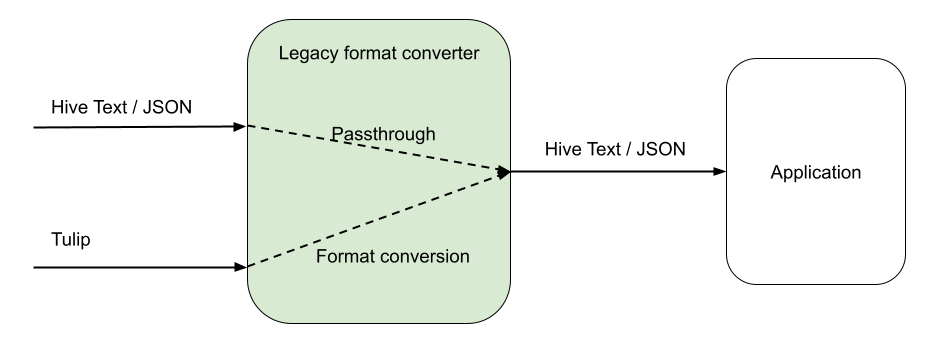
For use cases where updating the application code to consume a structured object was infeasible or too expensive (from an engineering cost point of view), we equipped the consuming system with a format converter that would consume the Tulip serialized payload and convert into a Hive Text (or JSON) serialized payload. This was inefficienct in terms of CPU utilization but allowed the team to move forward with the migration for a long tail of use cases.
Debugging tools
“Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” — Brian W. Kernighan

Challenge: Enable easy visual testing and validation data post-migration in a logging schema.
Solution: The loggertail CLI tool was developed to allow validation of data post-migration in a specific logging schema’s scribe queue. Loggertail uses a generic deserializer. It queries the serialization schema for a named logging schema and uses it to decode the input message. It then produces a human readable list of (field name, field value) pairs and prints the data as a JSON object.
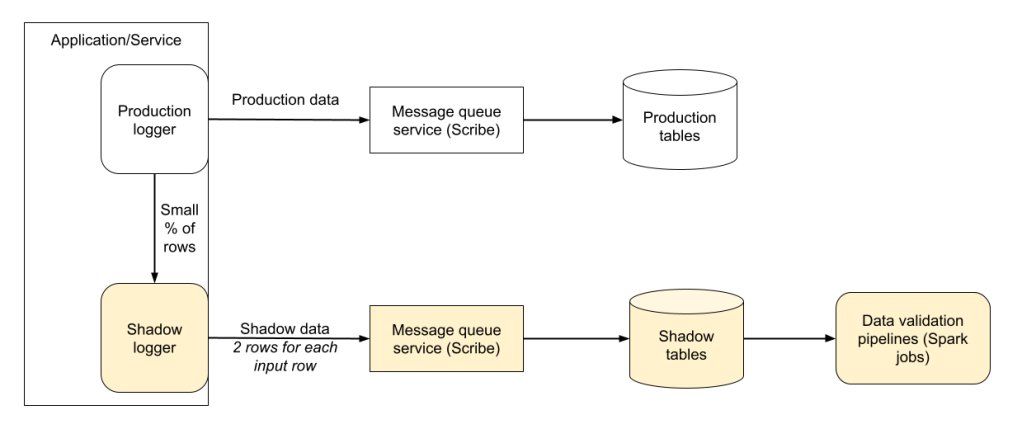
Shadow loggers
“Were you the one who went into the box or the one who came back out? We took turns. The trick is where we would swap.” — “The Prestige”
Challenge: End-to-end testing and verification of data logged via the new format.
Solution: Shadow loggers mimicked the original logging schema, except that they logged data to tables that the logger team monitored. This constituted an end-to-end acceptance test.
In addition to the user-specified columns, a shadow logging schema had two additional columns.
- Serialization format: Hive text or Tulip.
- Row ID: This is a unique identifier for the row, used to identify two identical rows that were serialized using different serialization formats.
The shadow loggers logged a small fraction of rows to a shadow table every time logging to the original logging schema was requested. A spark job was used to analyze the rows in these tables and ensure that the contents were identical for rows with the same ID, but a different serialization format. This validation provided the team with high confidence before the rollout.
Rate limits and partial rollout
Challenge: How can we quickly contain the bleeding in case of a problem during the rollout of Tulip serialization to a logging schema?
Solution: Even though validation via shadow loggers had been performed for each logging schema being migrated, we had to be prepared for unforeseen problems during the migration. We built a rate limiter to reduce the risk and enable the team to swiftly stop the bleed.
Scaling the migration
With over 30,000 logging schemas remaining, the scaling phase of the migration focused on performing the migration, with it being self-serve and using automation. Another important aspect of the scaling phase was ensuring that engineers would experience as litte friction as possible.
Automation tooling
Challenge: How does one choose the schemas to migrate based on the data consumers of the corresponding scribe stream?
Solution: Each logging schema was categorized based on the downstream consumers of the corresponding scribe stream. Only those logging schemas that had all supported downstream consumers were considered ready to consume the Tulip format.
Using this data, a tool was built so that an engineer just needed to run a script that would automatically target unmigrated logging schemas for conversion. We also built tools to detect potential data loss for the targeted logging schemas.
Eventually, this tooling was run daily by a cron-like scheduling system.
Nontechnical (soft) aspects
Challenge: There were numerous nontechnical aspects that the team had to deal with while migrating. For example, motivating end users to actually migrate and providing them support so that they can migrate safely and easily.
Solution: Since the migration varied in scale and complexity on an individual, case-by-case basis, we started out by providing lead time to engineering teams via tasks to plan for the migration. We came up with a live migration guide along with a demo video which migrated some loggers to show end users how this should be done. Instead of a migration guide that was written once and never (or rarely) updated, a decision was made to keep this guide live and constantly evolving. A support group and office hours were set up to help users if they stumbled on any blockers. These were particularly useful because users posted their experiences and how they got unblocked, which helped other users to get things moving if they encountered similar issues.
Conclusion
Making huge bets such as the transformation of serialization formats across the entire data platform is challenging in the short term, but it offers long-term benefits and leads to evolution over time.
Designing and architecting solutions that are cognizant of both the technical as well as nontechnical aspects of performing a migration at this scale are important for success. We hope that we have been able to provide a glimpse of the challenges we faced and solutions we used during this process.
Acknowledgements
We would like to thank members of the data platform team who partnered with the logger team to make this project a success. Without the cross-functional support of these teams and support from users (engineers) at Meta, this project and subsequent migration would not have been possible.








