
- Transparent memory offloading (TMO) is Meta’s data center solution for offering more memory at a fraction of the cost and power of existing technologies
- In production since 2021, TMO saves 20 percent to 32 percent of memory per server across millions of servers in our data center fleet
We are witnessing massive growth in the memory needs of emerging applications, such as machine learning, coupled with the slowdown of DRAM device scaling and large fluctuations of the DRAM cost. This has made DRAM prohibitively expensive as a sole memory capacity solution at Meta’s scale.
But alternative technologies such as NVMe-connected solid state drives (SSDs) offer higher capacity than DRAM at a fraction of the cost and power. Transparently offloading colder memory to such cheaper memory technologies via kernel or hypervisor techniques offers a promising approach to curb the appetite for DRAM. The key challenge, however, involves developing a robust data center–scale solution. Such a solution must be able to deal with diverse workloads and the large performance variance of different offload devices, such as compressed memory, SSD, and NVM.
Transparent Memory Offloading (TMO) is Meta’s solution for heterogeneous data center environments. It introduces a new Linux kernel mechanism that measures the lost work due to resource shortage across CPU, memory, and I/O in real time. Guided by this information and without any prior application knowledge, TMO automatically adjusts the amount of memory to offload to a heterogeneous device, such as compressed memory or an SSD. It does so according to the device’s performance characteristics and the application’s sensitivity to slower memory accesses. TMO holistically identifies offloading opportunities from not only the application containers but also the sidecar containers that provide infrastructure-level functions.
TMO has been running in production for more than a year, and has saved 20 percent to 32 percent of total memory across millions of servers in our expansive data center fleet. We have successfully upstreamed TMO’s OS components into the Linux kernel.
The opportunity for offloading
In recent years, a plethora of cheaper, non-DRAM memory technologies, such as NVMe SSDs, have been successfully deployed in our data centers or are on their way. Moreover, emerging non-DDR memory bus technologies such as Compute Express Link (CXL) provide memory-like access semantics and close-to-DDR performance. The memory-storage hierarchy shown in Figure 1 illustrates how various technologies stack against each other. The confluence of these trends affords new opportunities for memory tiering that were impossible in the past.
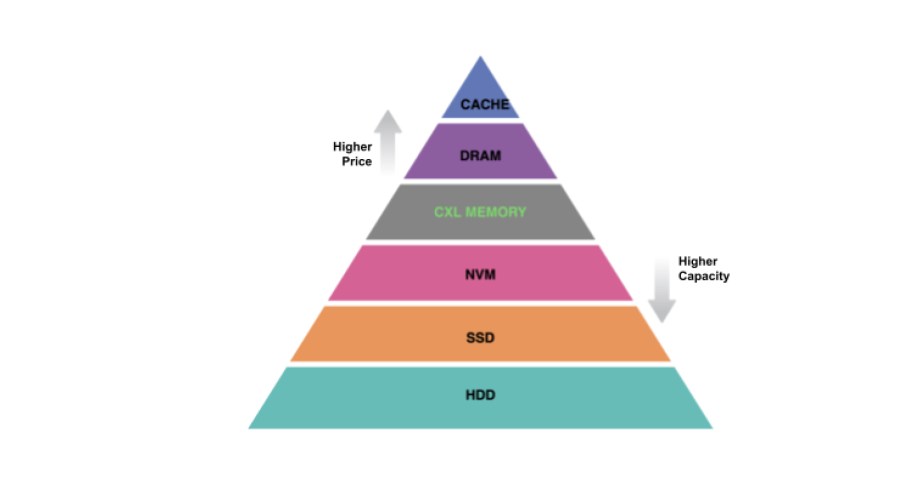
With memory tiering, less frequently accessed data gets migrated to slower memory. The application itself, a userspace library, the kernel, or the hypervisor can drive the migration process. Our TMO work focuses on kernel-driven migration, or swapping. Why? Because it can be applied transparently to many applications without requiring application modification. Despite its conceptual simplicity, kernel-driven swapping for latency-sensitive data center applications is challenging at hyperscale. We built TMO, a transparent memory offloading solution for containerized environments.
The solution: Transparent memory offloading
TMO consists of the following components:
- Pressure Stall Information (PSI), a Linux kernel component that measures the lost work due to resource shortage across CPU, memory, and I/O in real time. For the first time, we can directly measure an application’s sensitivity to memory access slowdown without resorting to fragile low-level metrics such as the page promotion rate.
- Senpai, a userspace agent that applies mild, proactive memory pressure to effectively offload memory across diverse workloads and heterogeneous hardware with minimal impact on application performance.
- TMO performs memory offloading to swap at subliminal memory pressure levels, with turnover proportional to file cache. This contrasts with the historical behavior of swapping as an emergency overflow under severe memory pressure.
The increasing cost of DRAM as a fraction of server cost motivated our work on TMO. Figure 2 shows the relative cost of DRAM, compressed memory, and SSD storage. We estimate the cost of compressed DRAM based on a 3x compression ratio representative of the average of our production workloads. We expect the cost of DRAM to grow, reaching 33 percent of our infrastructure spend. While not shown below, DRAM power consumption follows a similar trend, which we expect to reach 38 percent of our server infrastructure power. This makes compressed DRAM a good choice for memory offloading.
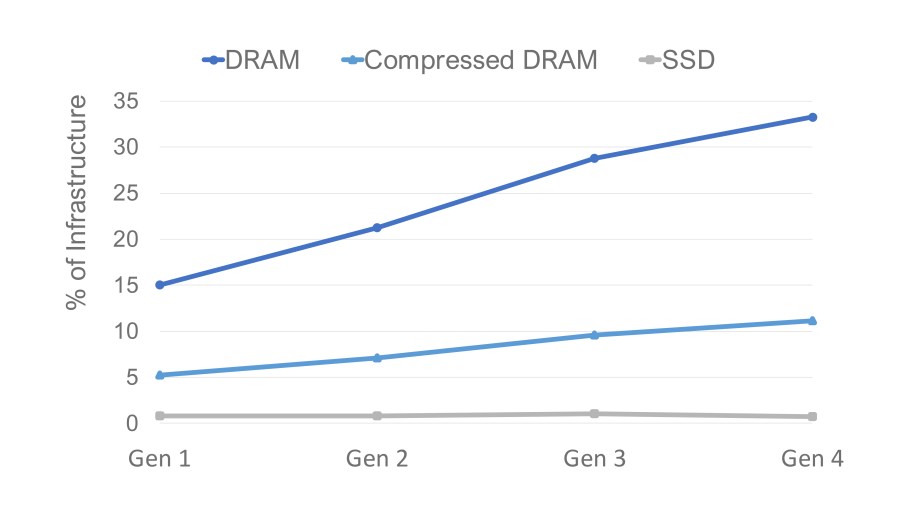
On top of compressed DRAM, we also equip all our production servers with very capable NVMe SSDs. At the system level, NVMe SSDs contribute to less than 3 percent of server cost (about 3x lower than compressed memory in our current generation of servers). Moreover, Figure 2 shows that, iso-capacity to DRAM, SSD remains under 1 percent of server cost across generations — about 10x lower than compressed memory in cost per byte! These trends make NVMe SSDs much more cost-effective compared with compressed memory.
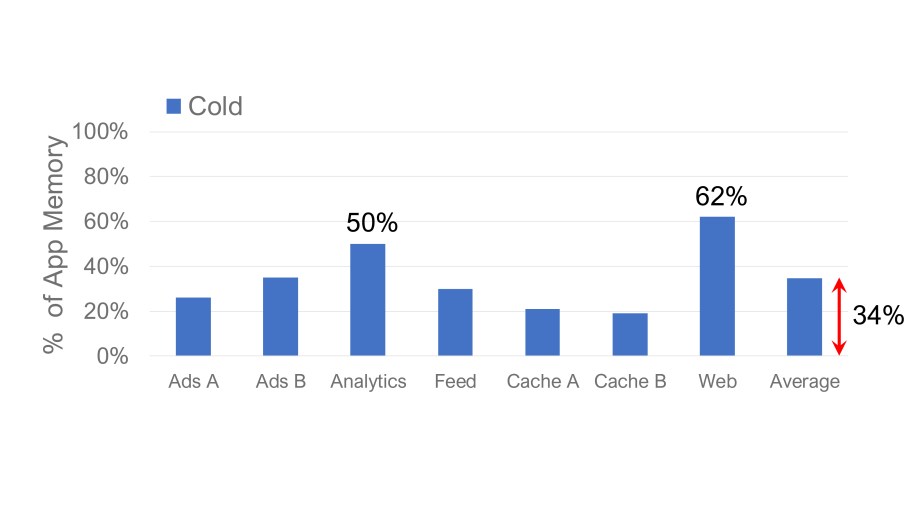
While cheaper than DRAM, compressed memory and NVMe SSDs have worse performance characteristics. Luckily, typical memory access patterns work in our favor and provide substantial opportunity for offloading to slower media. Figure 3 shows “cold” application memory — the percentage of pages not accessed in the past five minutes. Such memory can be offloaded to compressed memory or SSDs without affecting application performance. Overall, cold memory averages about 35 percent of total memory in our fleet. However, it varies wildly across applications, ranging from 19 percent to 62 percent. This highlights the importance of an offloading method that is robust against diverse application behavior.
In addition to access frequency, an offloading solution needs to account for which type of memory to offload. Memory accessed by applications consists of two main categories: anonymous and file-backed. Anonymous memory is allocated directly by applications in the form of heap or stack pages. File-backed memory is allocated by the kernel’s page cache to store frequently used filesystem data on the application’s behalf. Our workloads demonstrate a variety of file and anonymous mixtures. Some workloads use almost exclusively anonymous memory. Others’ footprint is dominated by the page cache. This requires our offloading solution to work equally well for anonymous and file pages.
TMO design overview
TMO comprises multiple pieces across the userspace and the kernel. A userspace agent called Senpai resides at the heart of the offloading operation. In a control loop around observed memory pressure, it engages the kernel’s reclaim algorithm to identify the least-used memory pages and move them out to the offloading backend. A kernel component called PSI (Pressure Stall Information) quantifies and reports memory pressure. The reclaim algorithm gets directed toward specific applications through the kernel’s cgroup2 memory controller.
PSI
Historically, system administrators have used metrics such as page fault rates to determine the memory health of a workload. However, this presents limitations. For one, fault rates can be elevated when workloads start on a cold cache or when working sets transition. Second, the impact a certain fault rate has on the workload depends heavily on the speed of the storage back end. What might constitute a significant slowdown on a rotational hard drive could be a nonevent on a decent flash drive.
PSI defines memory pressure such that it captures the true impact a memory shortage has on the workload. To accomplish this, it tracks task states that specifically occur due to lack of memory — for example, a thread stalling on the fault of a very recently reclaimed page, or a thread having to enter reclaim to satisfy an allocation request. PSI then aggregates the state of all threads inside the container and at system level into two pressure indicators: some and full. Some represents the condition where one or more threads stall. Full represents the condition where all non-idle threads simultaneously stall, and no thread can actively work toward what the application actually strives to accomplish. Finally, PSI measures the time that containers and the system spend in these aggregate states and reports it as a percentage of wall clock time.
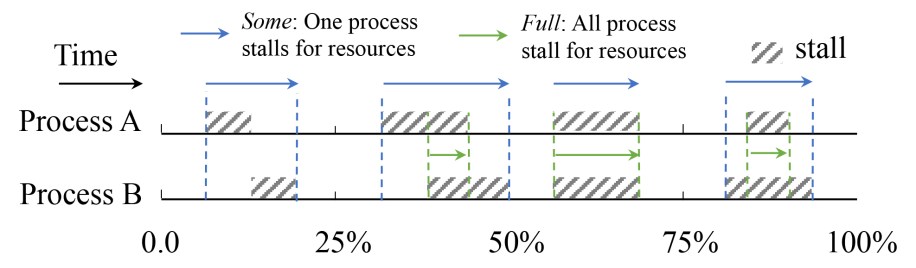
For example, if the full metric for a container is reported to be 1 percent over a 10s window, it means that for a sum total of 100ms during that period, a lack of memory in the container generated a concurrent unproductive phase for all non-idle threads. We consider the rate of the underlying events irrelevant. This could be the result of 10 page faults on a rotating hard drive or 10,000 faults on an SSD.
Senpai
Senpai sits atop the PSI metrics. It uses pressure as feedback to determine how aggressively to drive the kernel’s memory reclaim. If the container measures below a given pressure threshold, Senpai will increase the rate of reclaim. If pressure drops below, Senpai will ease up. The pressure threshold gets calibrated such that the paging overhead doesn’t functionally affect the workload’s performance.
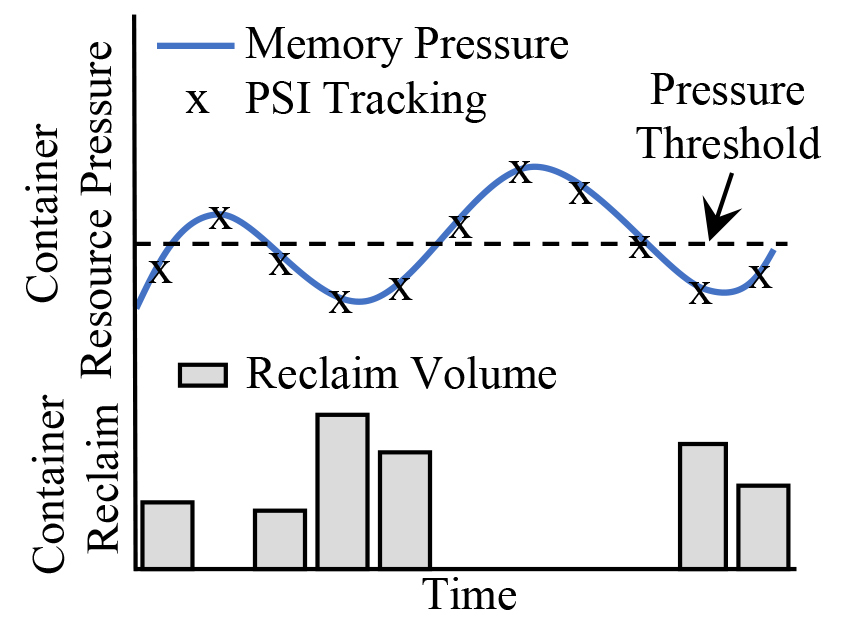
Senpai engages the kernel’s reclaim algorithm using the cgroup2 memory controller interface. Based on the deviation from the pressure target, Senpai determines a number of pages to reclaim and then instructs the kernel to do so:
reclaim = current_mem * reclaim_ratio * max(0,1 – psi_some/psi_threshold)
This occurs every six seconds, which allows time for the reclaim activity to translate to workload pressure in the form of refaults down the line.
Initially, Senpai used the cgroup2 memory limit control file to drive reclaim. It would calculate the reclaim step and then lower the limit that was in place by this amount. However, this sparked several problems in practice. For one, if the Senpai agent crashed, it would leave behind a potentially devastating restriction on the workload, resulting in extreme pressure and even OOM kills. Even without crashing, Senpai was often unable to raise the limit quickly enough on a rapidly expanding workload. This led to pressure spikes significantly above workload tolerances. To address these problems, we added a stateless memory.reclaim cgroup control file to the kernel. This knob allows Senpai to ask the kernel to reclaim exactly the calculated memory amount without applying any limit, thus avoiding the risk of blocking expanding workloads.
Swap algorithm
TMO aims to offload memory at pressure levels so low that they don’t hurt the workload. However, while Linux happily evicts the filesystem cache under pressure, we found it reluctant to move anonymous memory out to a swap device. Even when known cold heap pages exist and the file cache actively thrashes beyond TMO pressure thresholds, configured swap space would sit frustratingly idle.
The reason for this behavior? The kernel evolved over a period where storage was made up of hard drives with rotating spindles. The seek overhead of these devices results in rather poor performance when it comes to the semirandom IO patterns produced by swapping (and paging in general). Over the years, memory sizes only grew. At the same time, disk IOP/s rates remained stagnant. Attempts to page a significant share of the workload seemed increasingly futile. A system that’s actively swapping has become widely associated with intolerable latencies and jankiness. Over time, Linux for the most part resorted to engaging swap only when pressure levels approach out-of-memory (OOM) conditions.
However, the IOP capacity of contemporary flash drives — even cheap ones — is an order of magnitude better than that of hard drives. Where even high-end hard drives operate in the ballpark of a meager hundred IOP/s, commodity flash drives can easily handle hundreds of thousands of IOP/s. On those drives, paging a few gigabytes back and forth isn’t a big deal.
TMO introduces a new swap algorithm that takes advantage of these drives without regressing legacy setups still sporting rotational media. We accomplish this by tracking the rate of filesystem cache refaults in the system and engaging swap in direct proportion. That means that for every file page that repeatedly needs to be read from the filesystem, the kernel attempts to swap out one anonymous page. In doing so, it makes room for the thrashing page. Should swap-ins occur, reclaim pushes back on the file cache again.
This feedback loop finds an equilibrium that evicts the overall coldest memory among the two pools. This serves the workload with the minimal amount of aggregate paging IO. Because it only ever trades one type of paging activity for another, it never performs worse than the previous algorithm. In practice, it begins engaging swap at the first signs of file cache distress, thus effectively utilizing available swap space at the subliminal pressure levels of TMO.
TMO’s impact
TMO has been running in production for more than a year and has brought significant memory usage savings to Meta’s fleet. We break TMO’s memory savings into savings from applications, data center memory tax, and application memory tax, respectively.
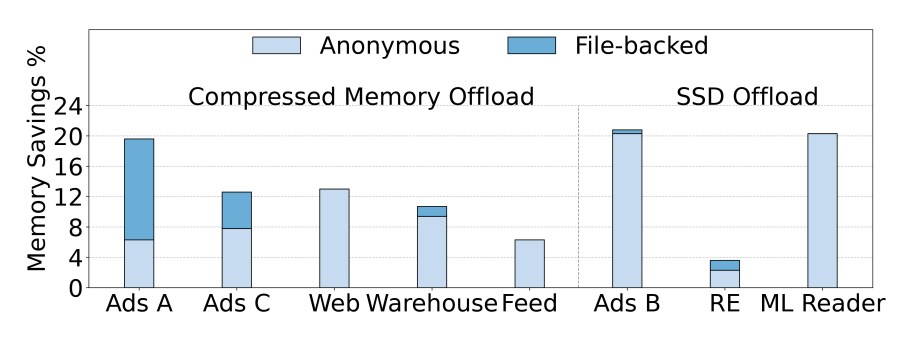
Application savings: Figure 6 shows the relative memory savings achieved by TMO for eight representative applications using different offload back ends, either compressed memory or SSDs. Using a compressed-memory back end, TMO saves 7 percent to12 percent of resident
memory across five applications. Multiple applications’ data have poor compressibility, such that offloading to an SSD proves far more effective. Specifically, machine learning models used for Ads prediction commonly use quantized byte-encoded values that exhibit a compression ratio of 1.3-1.4x. For those applications, Figure 8 shows that offloading to an SSD instead achieves savings of 10 percent to 19 percent. Overall, across compressed-memory and SSD back ends, TMO achieves significant savings of 7 percent to 19 percent of the total memory without noticeable application performance degradation.
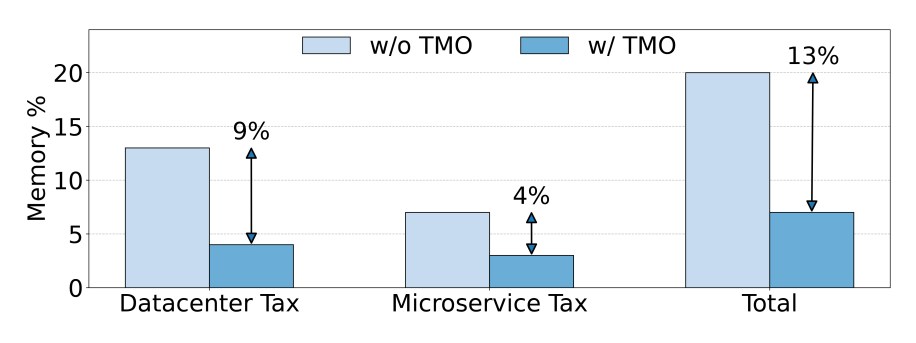
Data center and application memory tax savings: TMO further targets the memory overhead imposed by data center and application management services that run on each host besides the main workload. We call this the memory tax. Figure 7 shows the relative savings from offloading this type of memory across Meta’s fleet. When it comes to the data center tax, TMO saves an average of 9 percent of the total memory within a server. Application tax savings account for 4 percent. Overall, TMO achieves an average of 13 percent of memory tax savings. This is in addition to workload savings and represents a significant amount of memory at the scale of Meta’s fleet.
Limitations and future work
Currently, we manually choose the offload back end between compressed memory and SSD-backed swap depending on the application’s memory compressibility as well as its sensitivity to memory-access slowdown. Although we could develop tools to automate the process, a more fundamental solution entails the kernel managing a hierarchy of offload back ends (e.g., automatically using zswap for warmer pages and SSD for colder or less compressible pages, as well as folding NVM and CXL devices into the memory hierarchy in the future). The kernel reclaim algorithm should dynamically balance across these pools of memory. We are actively working on this architecture.
With upcoming bus technologies such as CXL that provide memorylike access semantics, memory offloading can help offload not only cold memory but also warm memory. We are actively focusing on that architecture to utilize CXL devices as a memory-offloading back end.








