
- We developed a new static analysis tool called Nullsafe that is used at Meta to detect NullPointerException (NPE) errors in Java code.
- Interoperability with legacy code and gradual deployment model were key to Nullsafe’s wide adoption and allowed us to recover some null-safety properties in the context of an otherwise null-unsafe language in a multimillion-line codebase.
- Nullsafe has helped significantly reduce the overall number of NPE errors and improved developers’ productivity. This shows the value of static analysis in solving real-world problems at scale.
Null dereferencing is a common type of programming error in Java. On Android, NullPointerException (NPE) errors are the largest cause of app crashes on Google Play. Since Java doesn’t provide tools to express and check nullness invariants, developers have to rely on testing and dynamic analysis to improve reliability of their code. These techniques are essential but have their own limitations in terms of time-to-signal and coverage.
In 2019, we started a project called 0NPE with the goal of addressing this challenge within our apps and significantly improving null-safety of Java code through static analysis.
Over the course of two years, we developed Nullsafe, a static analyzer for detecting NPE errors in Java, integrated it into the core developer workflow, and ran a large-scale code transformation to make many million lines of Java code Nullsafe-compliant.
Taking Instagram, one of Meta’s largest Android apps, as an example, we observed a 27 percent reduction in production NPE crashes during the 18 months of code transformation. Moreover, NPEs are no longer a leading cause of crashes in both alpha and beta channels, which is a direct reflection of improved developer experience and development velocity.
The problem of nulls
Null pointers are notorious for causing bugs in programs. Even in a tiny snippet of code like the one below, things can go wrong in a number of ways:
Listing 1: buggy getParentName method
Path getParentName(Path path) {
return path.getParent().getFileName();
}
- getParent() may produce null and cause a NullPointerException locally in getParentName(…).
- getFileName() may return null which may propagate further and cause a crash in some other place.
The former is relatively easy to spot and debug, but the latter may prove challenging — especially as the codebase grows and evolves.
Figuring out nullness of values and spotting potential problems is easy in toy examples like the one above, but it becomes extremely hard at the scale of millions of lines of code. Then adding thousands of code changes a day makes it impossible to manually ensure that no single change leads to a NullPointerException in some other component. As a result, users suffer from crashes and application developers need to spend an inordinate amount of mental energy tracking nullness of values.
The problem, however, is not the null value itself but rather the lack of explicit nullness information in APIs and lack of tooling to validate that the code properly handles nullness.
Java and nullness
In response to these challenges Java 8 introduced java.util.Optional<T> class. But its performance impact and legacy API compatibility issues meant that Optional could not be used as a general-purpose substitute for nullable references.
At the same time, annotations have been used with success as a language extension point. In particular, adding annotations such as @Nullable and @NotNull to regular nullable reference types is a viable way to extend Java’s types with explicit nullness while avoiding the downsides of Optional. However, this approach requires an external checker.
An annotated version of the code from Listing 1 might look like this:
Listing 2: correct and annotated getParentName method
// (2) (1)
@Nullable Path getParentName(Path path) {
Path parent = path.getParent(); // (3)
return parent != null ? parent.getFileName() : null;
// (4)
}
Compared to a null-safe but not annotated version, this code adds a single annotation on the return type. There are several things worth noting here:
- Unannotated types are considered not-nullable. This convention greatly reduces the annotation burden but is applied only to first-party code.
- Return type is marked @Nullable because the method can return null.
- Local variable parent is not annotated, as its nullness must be inferred by the static analysis checker. This further reduces the annotation burden.
- Checking a value for null refines its type to be not-nullable in the corresponding branch. This is called flow-sensitive typing, and it allows writing code idiomatically and handling nullness only where it’s really necessary.
Code annotated for nullness can be statically checked for null-safety. The analyzer can protect the codebase from regressions and allow developers to move faster with confidence.
Kotlin and nullness
Kotlin is a modern programming language designed to interoperate with Java. In Kotlin, nullness is explicit in the types, and the compiler checks that the code is handling nullness correctly, giving developers instant feedback.
We recognize these advantages and, in fact, use Kotlin heavily at Meta. But we also recognize the fact that there is a lot of business-critical Java code that cannot — and sometimes should not — be moved to Kotlin overnight.
The two languages – Java and Kotlin – have to coexist, which means there is still a need for a null-safety solution for Java.
Static analysis for nullness checking at scale
Meta’s success building other static analysis tools such as Infer, Hack, and Flow and applying them to real-world code-bases made us confident that we could build a nullness checker for Java that is:
- Ergonomic: understands the flow of control in the code, doesn’t require developers to bend over backward to make their code compliant, and adds minimal annotation burden.
- Scalable: able to scale from hundreds of lines of code to millions.
- Compatible with Kotlin: for seamless interoperability.
In retrospect, implementing the static analysis checker itself was probably the easy part. The real effort went into integrating this checker with the development infrastructure, working with the developer communities, and then making millions of lines of production Java code null-safe.
We implemented the first version of our nullness checker for Java as a part of Infer, and it served as a great foundation. Later on, we moved to a compiler-based infrastructure. Having a tighter integration with the compiler allowed us to improve the accuracy of the analysis and streamline the integration with development tools.
This second version of the analyzer is called Nullsafe, and we will be covering it below.
Null-checking under the hood
Java compiler API was introduced via JSR-199. This API gives access to the compiler’s internal representation of a compiled program and allows custom functionality to be added at different stages of the compilation process. We use this API to extend Java’s type-checking with an extra pass that runs Nullsafe analysis and then collects and reports nullness errors.
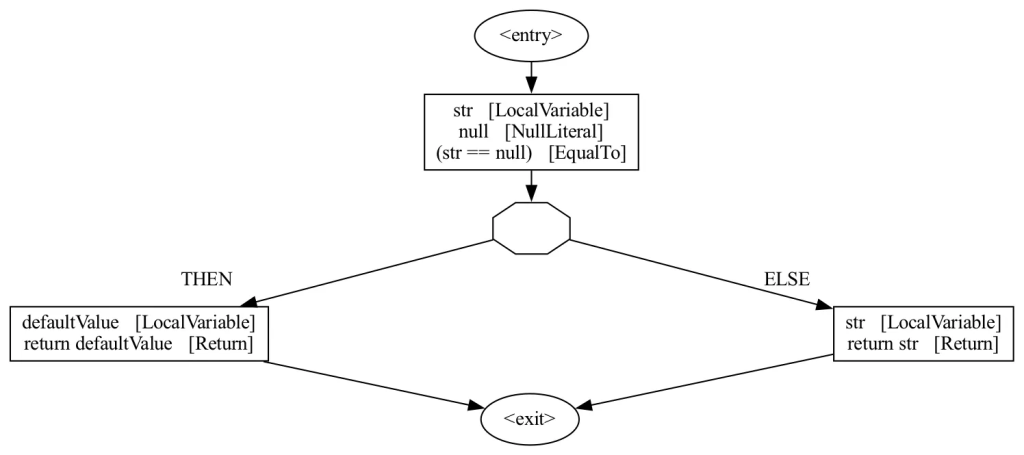
Two main data structures used in the analysis are the abstract syntax tree (AST) and control flow graph (CFG). See Listing 3 and Figures 2 and 3 for examples.
- The AST represents the syntactic structure of the source code without superfluous details like punctuation. We get a program’s AST via the compiler API, together with the type and annotation information.
- The CFG is a flowchart of a piece of code: blocks of instructions connected with arrows representing a change in control flow. We’re using the Dataflow library to build a CFG for a given AST.
The analysis itself is split into two phases:
- The type inference phase is responsible for figuring out nullness of various pieces of code, answering questions such as:
- Can this method invocation return null at program point X?
- Can this variable be null at program point Y?
- The type checking phase is responsible for validating that the code doesn’t do anything unsafe, such as dereferencing a nullable value or passing a nullable argument where it’s not expected.
Listing 3: example getOrDefault method
String getOrDefault(@Nullable String str, String defaultValue) {
if (str == null) { return defaultValue; }
return str;
}
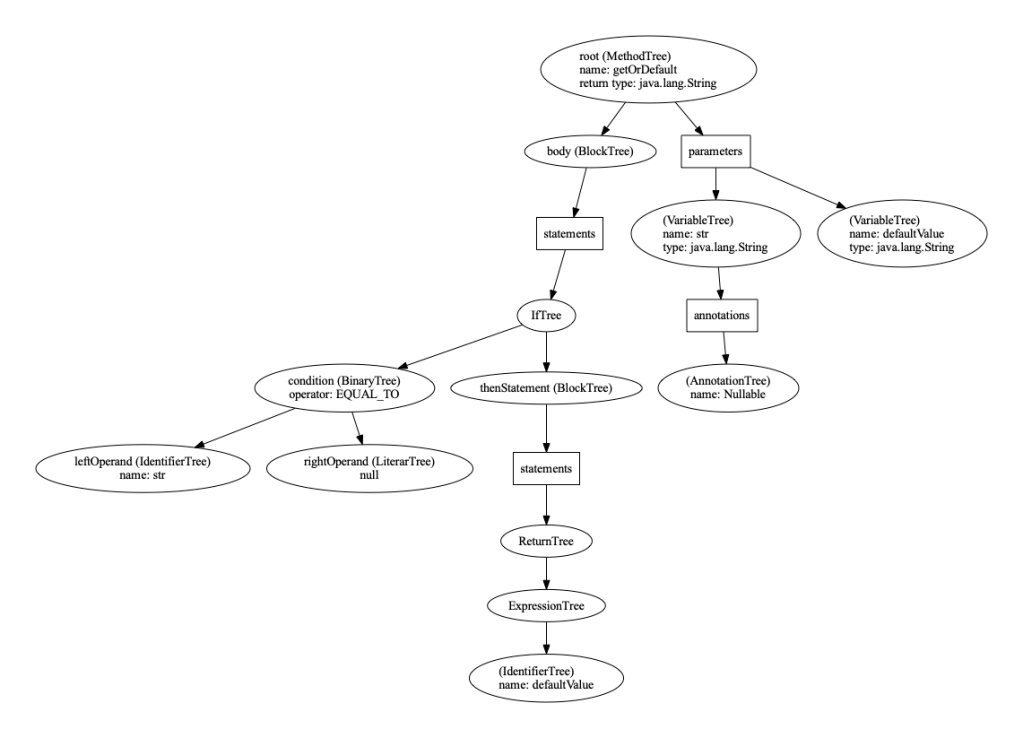
Type-inference phase
Nullsafe does type inference based on the code’s CFG. The result of the inference is a mapping from expressions to nullness-extended types at different program points.
state = expression x program point → nullness – extended type
The inference engine traverses the CFG and executes every instruction according to the analysis’ rules. For a program from Listing 3 this would look like this:
- We start with a mapping at <entry> point:
- {str → @Nullable String, defaultValue → String}.
- When we execute the comparison str == null, the control flow splits and we produce two mappings:
- THEN: {str → @Nullable String, defaultValue → String}.
- ELSE: {str → String, defaultValue → String}.
- When the control flow joins, the inference engine needs to produce a mapping that over-approximates the state in both branches. If we have @Nullable String in one branch and String in another, the over-approximated type would be @Nullable String.
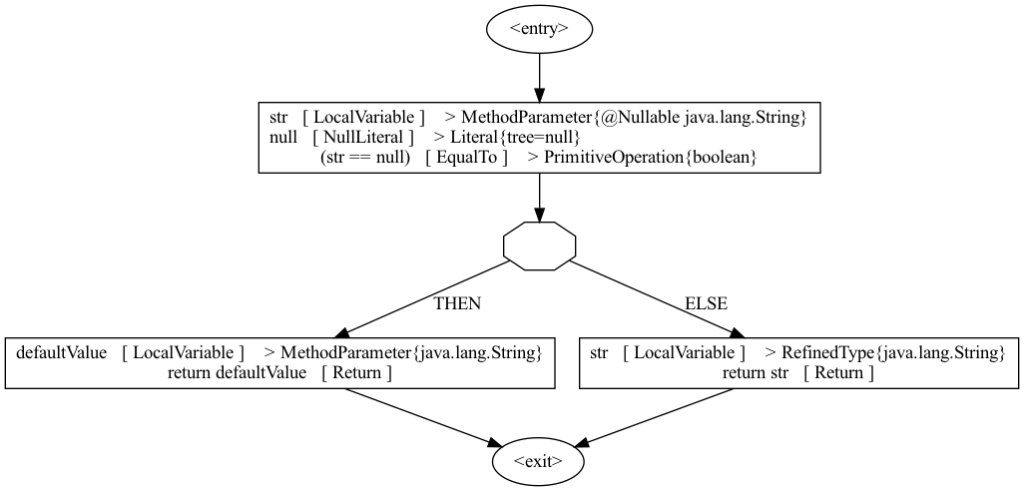
The main benefit of using a CFG for inference is that it allows us to make the analysis flow-sensitive, which is crucial for an analysis like this to be useful in practice.
The example above demonstrates a very common case where nullness of a value is refined according to the control flow. To accommodate real-world coding patterns, Nullsafe has support for more advanced features, ranging from contracts and complex invariants where we use SAT solving to interprocedural object initialization analysis. Discussion of these features, however, is outside the scope of this post.
Type-checking phase
Nullsafe does type checking based on the program’s AST. By traversing the AST, we can compare the information specified in the source code with the results from the inference step.
In our example from Listing 3, when we visit the return str node we fetch the inferred type of str expression, which happens to be String, and check whether this type is compatible with the return type of the method, which is declared as String.

When we see an AST node corresponding to an object dereference, we check that the inferred type of the receiver excludes null. Implicit unboxing is treated in a similar way. For method call nodes, we check that the inferred types of the arguments are compatible with method’s declared types. And so on.
Overall, the type-checking phase is much more straightforward than the type-inference phase. One nontrivial aspect here is error rendering, where we need to augment a type error with a context, such as a type trace, code origin, and potential quick fix.
Challenges in supporting generics
Examples of the nullness analysis given above covered only the so-called root nullness, or nullness of a value itself. Generics add a whole new dimension of expressivity to the language and, similarly, nullness analysis can be extended to support generic and parameterized classes to further improve the expressivity and precision of APIs.
Supporting generics is obviously a good thing. But extra expressivity comes as a cost. In particular, type inference gets a lot more complicated.
Consider a parameterized class Map<K, List<Pair<V1, V2>>>. In the case of non-generic nullness checker, there is only the root nullness to infer:
// NON-GENERIC CASE
␣ Map<K, List<Pair<V1, V2>>
// ^
// \--- Only the root nullness needs to be inferred
The generic case requires a lot more gaps to fill on top of an already complex flow-sensitive analysis:
// GENERIC CASE
␣ Map<␣ K, ␣ List<␣ Pair<␣ V1, ␣ V2>>
// ^ ^ ^ ^ ^ ^
// \-----|----|------|------|------|--- All these need to be inferred
This is not all. Generic types that the analysis infers must closely follow the shape of the types that Java itself inferred to avoid bogus errors. For example, consider the following snippet of code:
interface Animal {}
class Cat implements Animal {}
class Dog implements Animal {}
void targetType(@Nullable Cat catMaybe) {
List<@Nullable Animal> animalsMaybe = List.of(catMaybe);
}
List.<T>of(T…) is a generic method and in isolation the type of List.of(catMaybe) could be inferred as List<@Nullable Cat>. This would be problematic because generics in Java are invariant, which means that List<Animal> is not compatible with List<Cat> and the assignment would produce an error.
The reason this code type checks is that the Java compiler knows the type of the target of the assignment and uses this information to tune how the type inference engine works in the context of the assignment (or a method argument for the matter). This feature is called target typing, and although it improves the ergonomics of working with generics, it doesn’t play nicely with the kind of forward CFG-based analysis we described before, and it required extra care to handle.
In addition to the above, the Java compiler itself has bugs (e.g., this) that require various workarounds in Nullsafe and in other static analysis tools that work with type annotations.
Despite these challenges, we see significant value in supporting generics. In particular:
- Improved ergonomics. Without support for generics, developers cannot define and use certain APIs in a null-aware way: from collections and functional interfaces to streams. They are forced to circumvent the nullness checker, which harms reliability and reinforces a bad habit. We have found many places in the codebase where lack of null-safe generics led to brittle code and bugs.
- Safer Kotlin interoperability. Meta is a heavy user of Kotlin, and a nullness analysis that supports generics closes the gap between the two languages and significantly improves the safety of the interop and the development experience in a heterogeneous codebase.
Dealing with legacy and third-party code
Conceptually, the static analysis performed by Nullsafe adds a new set of semantic rules to Java in an attempt to retrofit null-safety onto an otherwise null-unsafe language. The ideal scenario is that all code follows these rules, in which case diagnostics raised by the analyzer are relevant and actionable. The reality is that there’s a lot of null-safe code that knows nothing about the new rules, and there’s even more null-unsafe code. Running the analysis on such legacy code or even newer code that calls into legacy components would produce too much noise, which would add friction and undermine the value of the analyzer.
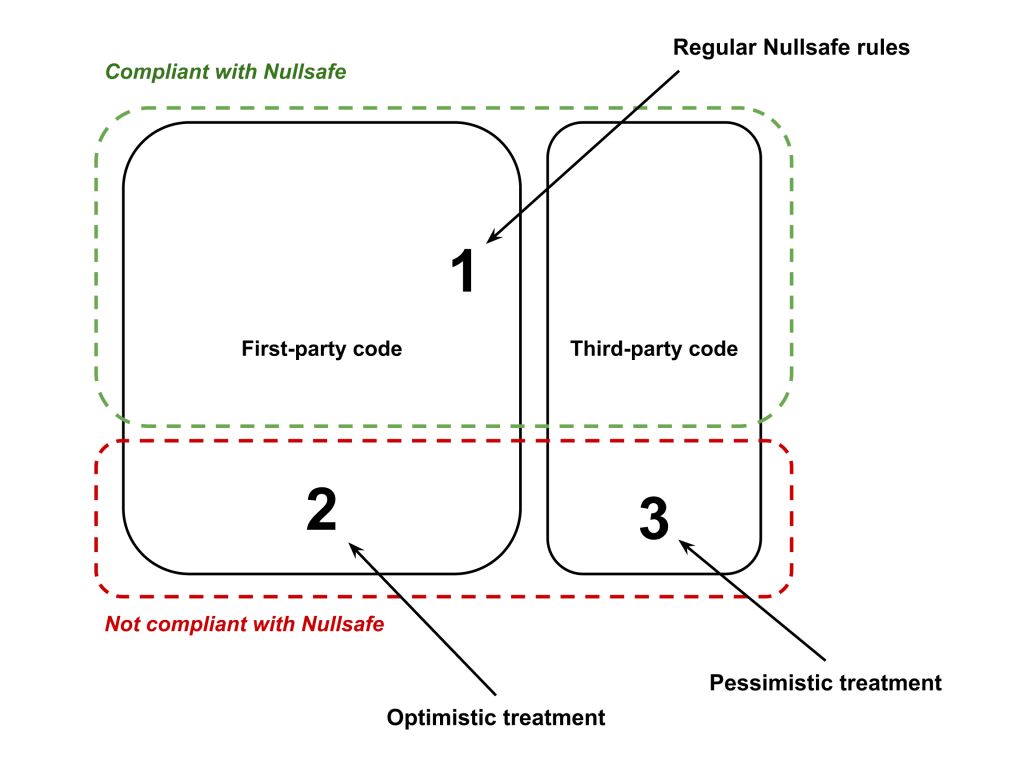
To deal with this problem in Nullsafe, we separate code into three tiers:
- Tier 1: Nullsafe compliant code. This includes first-party code marked as @Nullsafe and checked to have no errors. This also includes known good annotated third-party code or third-party code for which we have added nullness models.
- Tier 2: First-party code not compliant with Nullsafe. This is internal code written without explicit nullness tracking in mind. This code is checked optimistically by Nullsafe.
- Tier 3: Unvetted third-party code. This is third-party code that Nullsafe knows nothing about. When using such code, the uses are checked pessimistically and developers are urged to add proper nullness models.
The important aspect of this tiered system is that when Nullsafe type-checks Tier X code that calls into Tier Y code, it uses Tier Y’s rules. In particular:
- Calls from Tier 1 to Tier 2 are checked optimistically,
- Calls from Tier 1 to Tier 3 are checked pessimistically,
- Calls from Tier 2 to Tier 1 are checked according to Tier 1 component’s nullness.
Two things are worth noting here:
- According to point A, Tier 1 code can have unsafe dependencies or safe dependencies used unsafely. This unsoundness is the price we had to pay to streamline and gradualize the rollout and adoption of Nullsafe in the codebase. We tried other approaches, but extra friction rendered them extremely hard to scale. The good news is that as more Tier 2 code is migrated to Tier 1 code, this point becomes less of a concern.
- Pessimistic treatment of third-party code (point B) adds extra friction to the nullness checker adoption. But in our experience, the cost was not prohibitive, while the improvement in the safety of Tier 1 and Tier 3 code interoperability was real.
Deployment, automation, and adoption
A nullness checker alone is not enough to make a real impact. The effect of the checker is proportional to the amount of code compliant with this checker. Thus a migration strategy, developer adoption, and protection from regressions become primary concerns.
We found three main points to be essential to our initiative’s success:
- Quick fixes are incredibly helpful. The codebase is full of trivial null-safety violations. Teaching a static analysis to not only check for errors but also to come up with quick fixes can cover a lot of ground and give developers the space to work on meaningful fixes.
- Developer adoption is key. This means that the checker and related tooling should integrate well with the main development tools: build tools, IDEs, CLIs, and CI. But more important, there should be a working feedback loop between application and static analysis developers.
- Data and metrics are important to keep the momentum. Knowing where you are, the progress you’ve made, and the next best thing to fix really helps facilitate the migration.
Longer-term reliability impact
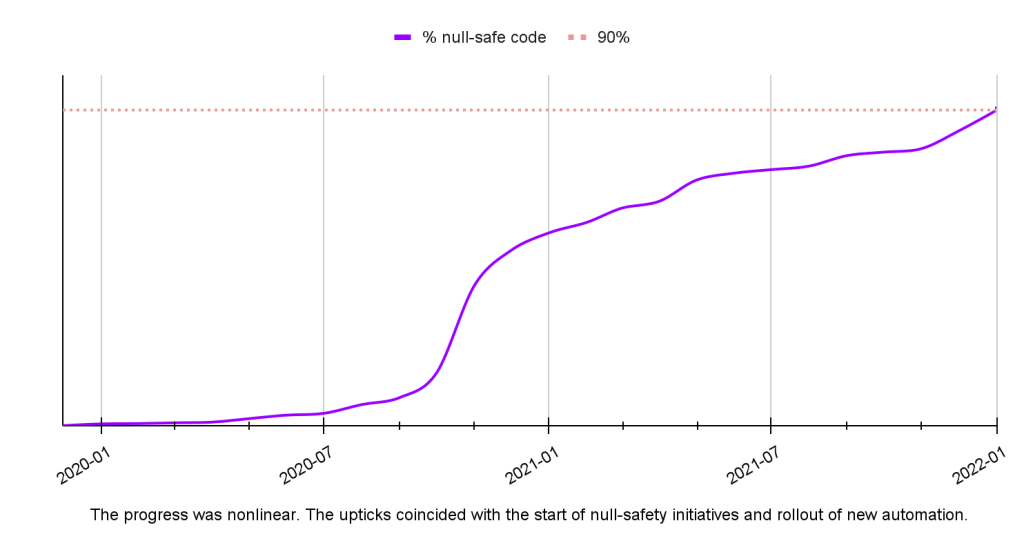
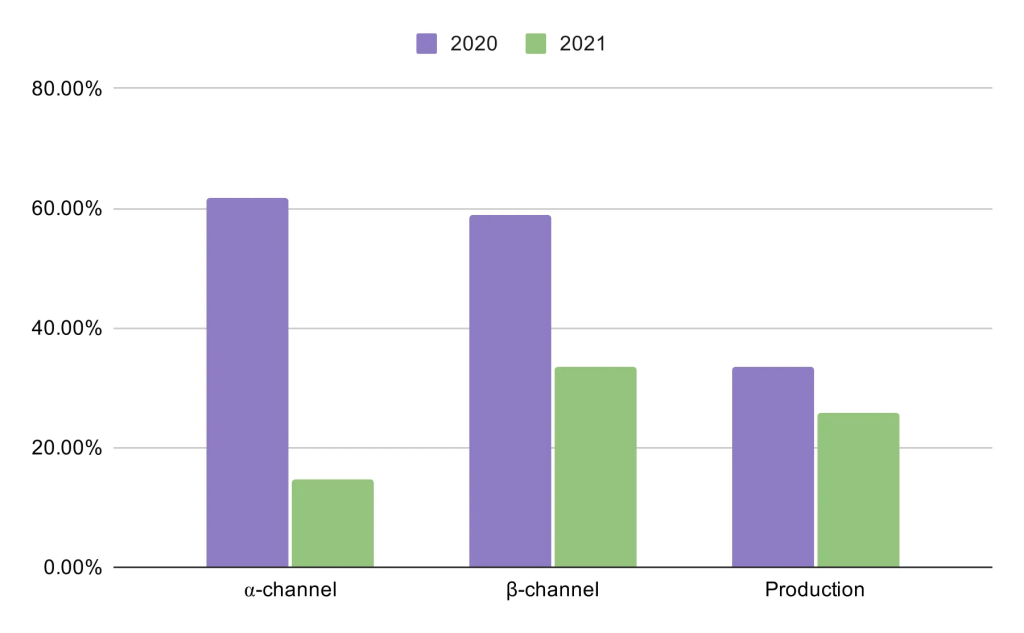
As one example, looking at 18 months of reliability data for the Instagram Android app:
- The portion of the app’s code compliant with Nullsafe grew from 3 percent to 90 percent.
- There was a significant decrease in the relative volume of NullPointerException (NPE) errors across all release channels (see Figure 7). Particularly, in production, the volume of NPEs was reduced by 27 percent.
This data is validated against other types of crashes and shows a real improvement in reliability and null-safety of the app.
At the same time, individual product teams also reported significant reduction in the volume of NPE crashes after addressing nullness errors reported by Nullsafe.
The drop in production NPEs varied from team to team, with improvements ranging from 35 percent to 80 percent.
One particularly interesting aspect of the results is the drastic drop in NPEs in the alpha-channel. This directly reflects the improvement in the developer productivity that comes from using and relying on a nullness checker.
Our north star goal, and an ideal scenario, would be to completely eliminate NPEs. However, real-world reliability is complex, and there are more factors playing a role:
- There is still null-unsafe code that is, in fact, responsible for a large percentage of top NPE crashes. But now we are in a position where targeted null-safety improvements can make a significant and lasting impact.
- The volume of crashes is not the best metric to measure reliability improvement because one bug that slips into production can become very hot and single-handedly skew the results. A better metric might be the number of new unique crashes per release, where we see n-fold improvement.
- Not all NPE crashes are caused by bugs in the app’s code alone. A mismatch between the client and the server is another major source of production issues that need to be addressed via other means.
- The static analysis itself has limitations and unsound assumptions that let certain bugs slip into production.
It is important to note that this is the aggregate effect of hundreds of engineers using Nullsafe to improve the safety of their code as well as the effect of other reliability initiatives, so we can’t attribute the improvement solely to the use of Nullsafe. However, based on reports and our own observations over the course of the last few years, we’re confident that Nullsafe played a significant role in driving down NPE-related crashes.
Beyond Meta
The problems outlined above are hardly specific to Meta. Unexpected null-dereferences have caused countless problems in different companies. Languages like C# evolved into having explicit nullness in their type system, while others, like Kotlin, had it from the very beginning.
When it comes to Java, there were multiple attempts to add nullness, starting with JSR-305, but none was widely successful. Currently, there are many great static analysis tools for Java that can check nullness, including CheckerFramework, SpotBugs, ErrorProne, and NullAway, to name a few. In particular, Uber walked the same path by making their Android codebase null-safe using NullAway checker. But in the end, all the checkers perform nullness analysis in different and subtly incompatible ways. The lack of standard annotations with precise semantics has constrained the use of static analysis for Java throughout the industry.
This problem is exactly what the JSpecify workgroup aims to address. The JSpecify started in 2019 and is a collaboration between individuals representing companies such as Google, JetBrains, Uber, Oracle, and others. Meta has also been part of JSpecify since late 2019.
Although the standard for nullness is not yet finalized, there has been a lot of progress on the specification itself and on the tooling, with more exciting announcements following soon. Participation in JSpecify has also influenced how we at Meta think about nullness for Java and about our own codebase evolution.








