
- We’re sharing Tulip, a binary serialization protocol supporting schema evolution.
- Tulip assists with data schematization by addressing protocol reliability and other issues simultaneously.
- It replaces multiple legacy formats used in Meta’s data platform and has achieved significant performance and efficiency gains.
There are numerous heterogeneous services, such as warehouse data storage and various real-time systems, that make up Meta’s data platform — all exchanging large amounts of data among themselves as they communicate via service APIs. As we continue to grow the number of AI- and machine learning (ML)–related workloads in our systems that leverage data for tasks such as training ML models, we’re continually working to make our data logging systems more efficient.
Schematization of data plays an important role in a data platform at Meta’s scale. These systems are designed with the knowledge that every decision and trade-off can impact the reliability, performance, and efficiency of data processing, as well as our engineers’ developer experience.
Making huge bets, like changing serialization formats for the entire data infrastructure, is challenging in the short term, but offers greater long-term benefits that help the platform evolve over time.
The challenge of a data platform at exabyte scale
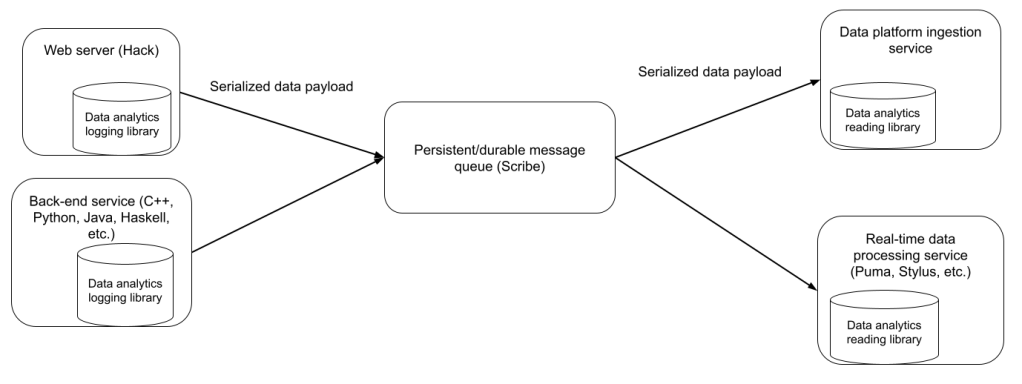
The data analytics logging library is present in the web tier as well as in internal services. It is responsible for logging analytical and operational data via Scribe (Meta’s persistent and durable message queuing system). Various services read and ingest data from Scribe, including (but not limited to) the data platform Ingestion Service, and real-time processing systems, such as Puma, Stylus, and XStream. The data analytics reading library correspondingly assists in deserializing data and rehydrating it into a structured payload. While this article will focus on only the logging library, the narrative applies to both.
At the scale at which Meta’s data platform operates, thousands of engineers create, update, and delete logging schemas every month. These logging schemas see petabytes of data flowing through them every day over Scribe.
Schematization is important to ensure that any message logged in the present, past, or future, relative to the version of (de)serializer, can be (de)serialized reliably at any point in time with the highest fidelity and no loss of data. This property is called safe schema evolution via forward and backward compatibility.
This article will focus on the on-wire serialization format chosen to encode data that is finally processed by the data platform. We motivate the evolution of this design, the trade-offs considered, and the resulting improvements. From an efficiency point of view, the new encoding format needs between 40 percent to 85 percent fewer bytes, and uses 50 percent to 90 percent fewer CPU cycles to (de)serialize data compared with the previously used serialization formats, namely Hive Text Delimited and JSON serialization.
How we developed Tulip
An overview of the data analytics logging library
The logging library is used by applications written in various languages (such as Hack, C++, Java, Python, and Haskell) to serialize a payload according to a logging schema. Engineers define logging schemas in accordance with business needs. These serialized payloads are written to Scribe for durable delivery.
The logging library itself comes in two flavors:
- Code-generated: In this flavor, statically typed setters for each field are generated for type-safe usage. Additionally, post-processing and serialization code are also code-generated (where applicable) for maximum efficiency. For example, Hack’s thrift serializer uses a C++ accelerator, where code generation is partially employed.
- Generic: A C++ library called Tulib (not to be confused with Tulip) to perform (de)serialization of dynamically typed payloads is provided. In this flavor, a dynamically typed message is serialized according to a logging schema. This mode is more versatile than the code-generated mode because it allows (de)serialization of messages without rebuilding and redeploying the application binary.
Legacy serialization format
The logging library writes data to multiple back-end systems that have historically dictated their own serialization mechanisms. For example, warehouse ingestion uses Hive Text Delimiters during serialization, whereas other systems use JSON serialization. There are many problems when using one or both of these formats for serializing payloads.
- Standardization: Previously, each downstream system had its own format, and there was no standardization of serialization formats. This increased development and maintenance costs.
- Reliability: The Hive Text Delimited format is positional in nature. To maintain deserialization reliability, new columns can be added only at the end. Any attempt to add fields in the middle of a column or delete columns will shift all the columns after it, making the row impossible to deserialize (since a row is not self-describing, unlike in JSON). We distribute the updated schema to readers in real time.
- Efficiency: Both the Hive Text Delimited and JSON protocol are text-based and inefficient in comparison with binary (de)serialization.
- Correctness: Text-based protocols such as Hive Text require escaping and unescaping of control characters field delimiters and line delimiters. This is done by every writer/reader and puts additional burden on library authors. It’s challenging to deal with legacy/buggy implementations that only check for the presence of such characters and disallow the entire message instead of escaping the problematic characters.
- Forward and backward compatibility: It’s desirable for consumers to be able to consume payloads that were serialized by a serialization schema both before and after the version that the consumer sees. The Hive Text Protocol doesn’t provide this guarantee.
- Metadata: Hive Text Serialization doesn’t trivially permit the addition of metadata to the payload. Propagation of metadata for downstream systems is critical to implement features that benefit from its presence. For example, certain debugging workflows benefit from having a hostname or a checksum transferred along with the serialized payload.
The fundamental problem that Tulip solved is the reliability issue, by ensuring a safe schema evolution format with forward and backward compatibility across services that have their own deployment schedules.
One could have imagined solving the others independently by pursuing a different strategy, but the fact that Tulip was able to solve all of these problems at once made it a much more compelling investment than other options.
Tulip serialization
The Tulip serialization protocol is a binary serialization protocol that uses Thrift’s TCompactProtocol for serializing a payload. It follows the same rules for numbering fields with IDs as one would expect an engineer to use when updating IDs in a Thrift struct.
When engineers author a logging schema, they specify a list of field names and types. Field IDs are not specified by engineers, but are instead assigned by the data platform management module.

This figure shows user-facing workflow when an engineer creates/updates a logging schema. Once validation succeeds, the changes to the logging schema are published to various systems in the data platform.
The logging schema is translated into a serialization schema and stored in the serialization schema repository. A serialization config holds lists of (field name, field type, field ID) for a corresponding logging schema as well as the field history. A transactional operation is performed on the serialization schema when an engineer wishes to update a logging schema.

The example above shows the creation and updation of a logging schema and its impact on the serialization schema over time.
- Field addition: When a new field named “authors” is added to the logging schema, a new ID is assigned in the serialization schema.
- Field type change: Similarly, when the type of the field “isbn” is changed from “i64” to “string”, a new ID is associated with the new field, but the ID of the original “i64” typed “isbn” field is retained in the serialization schema. When the underlying data store doesn’t allow field type changes, the logging library disallows this change.
- Field deletion: IDs are never removed from the serialization schema, allowing complete backward compatibility with already serialized payloads. The field in a serialization schema for a logging schema is indelible even if fields in the logging schema are added/removed.
- Field rename: There’s no concept of a field rename, and this operation is treated as a field deletion followed by a field addition.
Acknowledgements
We would like to thank all the members of the data platform team who helped make this project a success. Without the XFN-support of these teams and engineers at Meta, this project would not have been possible.
A special thank-you to Sriguru Chakravarthi, Sushil Dhaundiyal, Hung Duong, Stefan Filip, Manski Fransazov, Alexander Gugel, Paul Harrington, Manos Karpathiotakis, Thomas Lento, Harani Mukkala, Pramod Nayak, David Pletcher, Lin Qiao, Milos Stojanovic, Ezra Stuetzel, Huseyin Tan, Bharat Vaidhyanathan, Dino Wernli, Kevin Wilfong, Chong Xie, Jingjing Zhang, and Zhenyuan Zhao.








