
ZippyDB is the largest strongly consistent, geographically distributed key-value store at Facebook. Since we first deployed ZippyDB in 2013, this key-value store has expanded rapidly, and today, ZippyDB serves a number of use cases, ranging from metadata for a distributed filesystem, counting events for both internal and external purposes, to product data that’s used for various app features. ZippyDB offers a lot of flexibility to applications in terms of tunable durability, consistency, availability, and latency guarantees, which has made the service a popular choice within Facebook for storing both ephemeral and nonephemeral small key-value data. In this post, we are sharing for the first time the history and evolution of ZippyDB and some of the unique design choices and trade-offs made in building this service that addressed the majority of key-value store scenarios at Facebook.
History of ZippyDB
ZippyDB uses RocksDB as the underlying storage engine. Before ZippyDB, various teams across Facebook used RocksDB directly to manage their data. This resulted, however, in a duplication of efforts in terms of each team solving similar challenges such as consistency, fault tolerance, failure recovery, replication, and capacity management. To address the needs of these various teams, we built ZippyDB to provide a highly durable and consistent key-value data store that allowed products to move a lot faster by offloading all the data and the challenges associated with managing this data at scale to ZippyDB.
One of the significant design decisions we made early during the development of ZippyDB was to reuse as much of the existing infrastructure as possible. Consequently, most of our initial efforts were focused on building a reusable and flexible data replication library called Data Shuttle. We built a fully managed distributed key-value store by combining Data Shuttle with a preexisting and well-established storage engine (RocksDB) and layering this on top of our existing shard management (Shard Manager) and distributed configuration service (built on ZooKeeper), that together solves load balancing, shard placement, failure detection, and service discovery.
Architecture
ZippyDB is deployed in units known as tiers. A tier consists of compute and storage resources spread across several geographic areas known as regions worldwide, which makes it resilient to failures. There are only a handful of ZippyDB tiers that exist today, including the default “wildcard” tier and specialized tiers for distributed filesystem metadata and other product groups within Facebook. Each tier hosts multiple use cases. Normally, use cases are created on the wildcard tier, which is our generic multitenant tier. This is the preferred tier because of its better utilization of hardware and lower operational overhead, but we occasionally bring up dedicated tiers if there is a need, usually due to stricter isolation requirements.
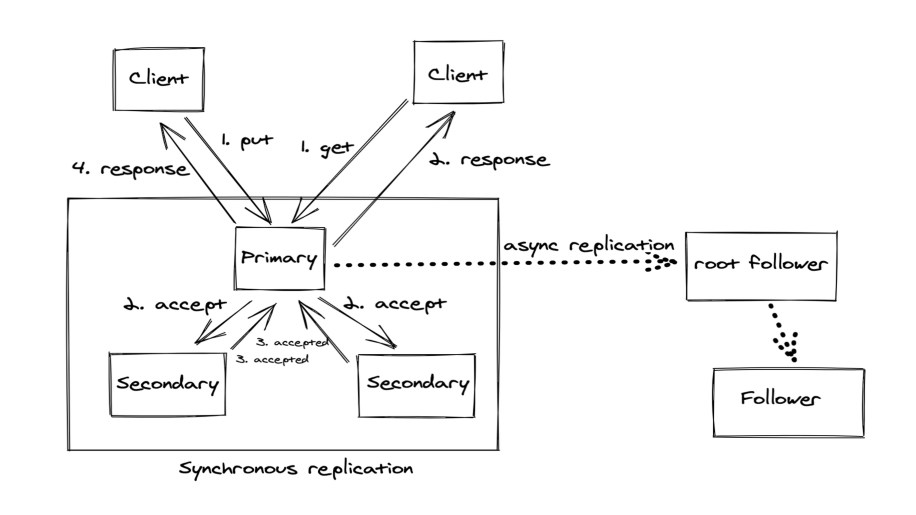
The data belonging to a use case on a tier is split into units known as shards, which are the basic units of data management on the server side. Each shard is replicated across multiple regions (for fault tolerance) using Data Shuttle, which uses either Paxos or async replication to replicate data, depending on the configuration. Within a shard, a subset of replicas are configured to be a part of the Paxos quorum group, also known as global scope, where data is synchronously replicated using Multi-Paxos to provide high durability and availability in case of failures. The remaining replicas, if any, are configured as followers. These are similar to learners in Paxos terminology and receive data asynchronously. Followers allow applications to have many in-region replicas to support low-latency reads with relaxed consistency, while keeping the quorum size small for lower write latency. This flexibility in replica role configuration within a shard allows applications to strike a balance between durability, write performance, and read performance depending on their needs.
In addition to the sync or async replication strategy, applications also have the option to provide “hints” to the service about the regions in which the replicas of a shard must be placed. These hints, also known as stickiness constraints, allow applications to have some control over the latency of reads and writes by having replicas built in regions from where they expect most of the access to come. ZippyDB also provides a caching layer and integrates with a pub-sub system allowing subscriptions to data mutations on shards, both of which are opt-ins depending on the requirements of the use case.
Data model
ZippyDB supports a simple key-value data model with APIs to get, put, and delete keys along with their batch variants. It supports iterating over key prefixes and deleting a range of keys. These APIs are very similar to the API exposed by the underlying RocksDB storage engine. In addition, we also support a test-and-set API for basic read-modify-write operations and transactions, conditional writes for more generic read-modify-write operations (more about this later). This minimal API set has proved to be sufficient for most use cases to manage their data on ZippyDB. For ephemeral data, ZippyDB has native TTL support where the client can optionally specify the expiry time for an object at the time of the write. We piggyback on RocksDB’s periodic compaction support to clean up all the expired keys efficiently while filtering out dead keys on the read side in between compaction runs. Many applications actually access data on ZippyDB through an ORM layer on top of ZippyDB, which translates these accesses into ZippyDB API. Among other things, this layer serves to abstract the details of the underlying storage service.
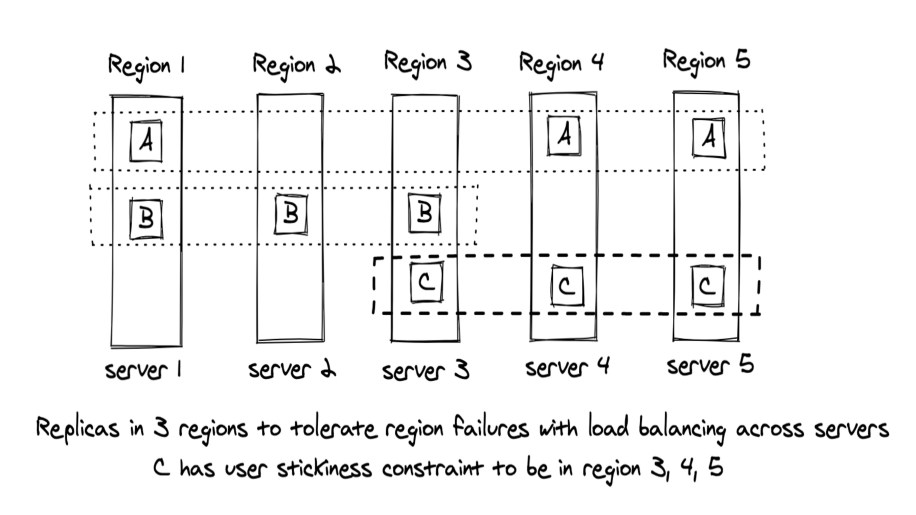
Shard is the unit of data management on the server side. The optimal assignment of shards to servers needs to take into account load, failure domains, user constraints, etc., and this is handled by ShardManager. ShardManager is responsible for monitoring servers for load imbalance, failures, and initiating shard movement between servers.
Shard, often referred to as physical shard or p-shard, is a server-side concept and isn’t exposed to applications directly. Instead, we allow use cases to partition their key space into smaller units of related data known as μshards (micro-shards). A typical physical shard has a size of 50–100 GB, hosting several tens of thousands of μshards. This additional layer of abstraction allows ZippyDB to reshard the data transparently without any changes on the client.
ZippyDB supports two kinds of mappings from μshards to physical shards: compact mapping and Akkio mapping. Compact mapping is used when the assignment is fairly static and mapping is only changed when there is a need to split shards that have become too large or hot. In practice, this is a fairly infrequent operation when compared with Akkio mapping, where mapping of μshards is managed by a service known as Akkio. Akkio splits use cases’ key space into μshards and places these μshards in regions where the information is typically accessed. Akkio helps reduce data set duplication and provides a significantly more efficient solution for low latency access than having to place data in every region.
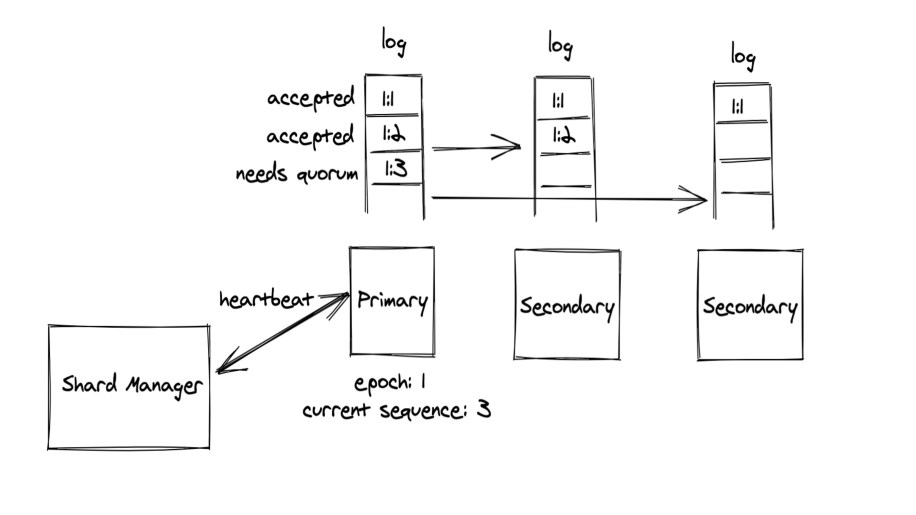
As we mentioned earlier, Data Shuttle uses Multi-Paxos to synchronously replicate data to all replicas in the global scope. Conceptually, time is subdivided into units known as epochs. Each epoch has a unique leader, whose role is assigned using an external shard management service called ShardManager. Once a leader is assigned, it has a lease for the entire duration of the epoch. Periodic heartbeats used to keep a lease active until ShardManager bumps up the epoch on the shard (e.g., for failover, primary load balancing, etc.). When a failure occurs, ShardManager detects the failure, assigns a new leader with a higher epoch and restores write availability. Within each epoch, the leader generates a total ordering of all writes to the shard, by assigning each write a monotonically increasing sequence number. The writes are then written to a replicated durable log using Multi-Paxos to achieve consensus on the ordering. Once the writes have reached consensus, they are drained in-order across all replicas.
We chose to use an external service to detect failures and assign leaders to keep the design of the service simple in the initial implementation. However, in the future we plan to move towards detecting failures entirely within Data Shuttle (“in-band”) and reelecting the leaders more proactively without having to wait for ShardManager and incurring delays.
Consistency
ZippyDB provides configurable consistency and durability levels to applications, which can be specified as options in read and write APIs. This allows applications to make durability, consistency, and performance trade-offs dynamically on a per-request level.
By default, a write involves persisting the data on a majority of replicas’ Paxos logs and writing the data to RocksDB on the primary before acknowledging the write to the client. With the default write mode, a read on primary will always see the most recent write. Some applications cannot tolerate cross-region latencies for every write, so ZippyDB supports a fast-acknowledge mode, where writes are acknowledged as soon as they are enqueued on the primary for replication. The durability and consistency guarantees for this mode are obviously lower, which is the trade-off for higher performance.
On the read side, the three most popular consistency levels are eventual, read-your-writes, and strong. The eventual consistency level supported by ZippyDB is actually a much stronger consistency level than the more well-known eventual consistency. ZippyDB provides total ordering for all writes within a shard and ensures that reads aren’t served by replicas that are lagging behind primary/quorum beyond a certain configurable threshold (heartbeats are used to detect lag), so eventual reads supported by ZippyDB are closer to bounded staleness consistency in literature.
For read-your-writes, the clients cache the latest sequence number returned by the server for writes and use the version to run at-or-later queries while reading. The cache of versions is within the same client process.
ZippyDB also provides strong consistency or linearizability, where clients can see the effects of the most recent writes regardless of where the writes or reads come from. Strong reads today are implemented by routing the reads to the primary in order to avoid the need to speak to a quorum, mostly for performance reasons. The primary relies on owning the lease to ensure that there is no other primary before serving reads. In certain outlier cases, where the primary hasn’t heard about the lease renewal, strong reads on primary turn into a quorum check and read.
Transactions and conditional writes
![]()
![]()
ZippyDB supports transactions and conditional writes for use cases that need atomic read-modify-write operations on a set of keys.
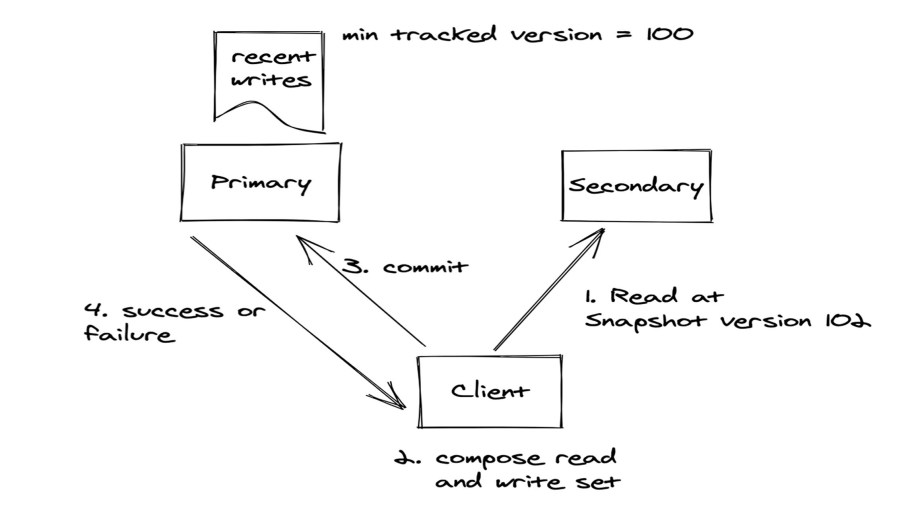
All transactions are serializable by default on a shard, and we don’t support lower isolation levels. This simplifies the server-side implementation and the reasoning about correctness of concurrently executing transactions on the client side. Transactions use optimistic concurrency control to detect and resolve conflicts, which works as shown in the figure above. The clients typically read from a secondary all of the data from a snapshot of the DB, compose the write set, and send both the read and write sets to the primary to commit. Upon receiving the read and write sets and the snapshot against which reads were performed, the primary checks whether there were conflicting writes by other concurrently executing transactions that have already been admitted. The transaction is admitted only if there are no conflicts, after which the transaction is guaranteed to succeed, assuming no server failures. Conflict resolution on the primary relies on tracking all of the recent writes performed by previously admitted transactions during the same epoch on the primary. Transactions spanning epochs are rejected, as this simplifies write set tracking without requiring replication. The history of writes maintained on the primary is also periodically purged to keep the space usage low. Since the complete history isn’t maintained, the primary needs to maintain a minimum tracked version and reject all transactions that have reads against a snapshot with lower version to guarantee serializability. Read-only transactions work exactly similar to read-write transactions, except that the write set is empty.
Conditional write is implemented using “server-side transactions”. It provides a more user friendly client side API for use cases where clients want to atomically modify a set of keys based on some common preconditions such as key_present, key_not_present, and value_matches_or_key_not_present. When a primary receives a conditional write request it sets up a transaction context and converts the preconditions and write set to a transaction on the server, reusing all of the machinery for transactions. The conditional-write API can be more efficient than the transaction API in cases where clients can compute the precondition without requiring a read.
The future of ZippyDB
Distributed key-value stores have many applications, and the need for them often comes up while building a variety of systems, from products to storing metadata for various infrastructure services. Building a scalable, strongly consistent, and fault-tolerant key-value store can be very challenging and often requires thinking through many trade-offs to provide a curated combination of system capabilities and guarantees that works well in practice for a variety of workloads. This blog post introduced ZippyDB, Facebook’s biggest key-value store, which has been in production for more than six years serving a lot of different workloads. Since its inception, the service has seen very steep adoption, mostly due to the flexibility that it offers in terms of making efficiency, availability, and performance trade-offs. The service also enables us to use engineering resources effectively as a company and use our key-value store capacity efficiently as a single pool. ZippyDB is still evolving and currently undergoing significant architectural changes, such as storage-compute disaggregation, fundamental changes to membership management, failure detection and recovery, and distributed transactions, in order to adapt to the changing ecosystem and product requirements.








