
What the research is:
Twine is our homegrown cluster management system, which has been running in production for the past decade. A cluster management system allocates workloads to machines and manages the life cycle of machines, containers, and workloads. Kubernetes is a prominent example of an open source cluster management system. Twine has helped convert our infrastructure from a collection of siloed pools of customized machines dedicated to individual workloads to a large-scale ubiquitous shared infrastructure in which any machine can run any workload.
We had broad conversations with colleagues in industry and learned that, while partial consolidation of workloads is common, no large organization has achieved ubiquitous shared infrastructure. To achieve this goal, we made several unconventional decisions, including:
- We scale a single Twine control plane to manage one million machines across data centers in a geographic region while providing high reliability and performance guarantees.
- We support workload-specific customization, which allows diverse workloads to run on shared infrastructure without sacrificing performance.
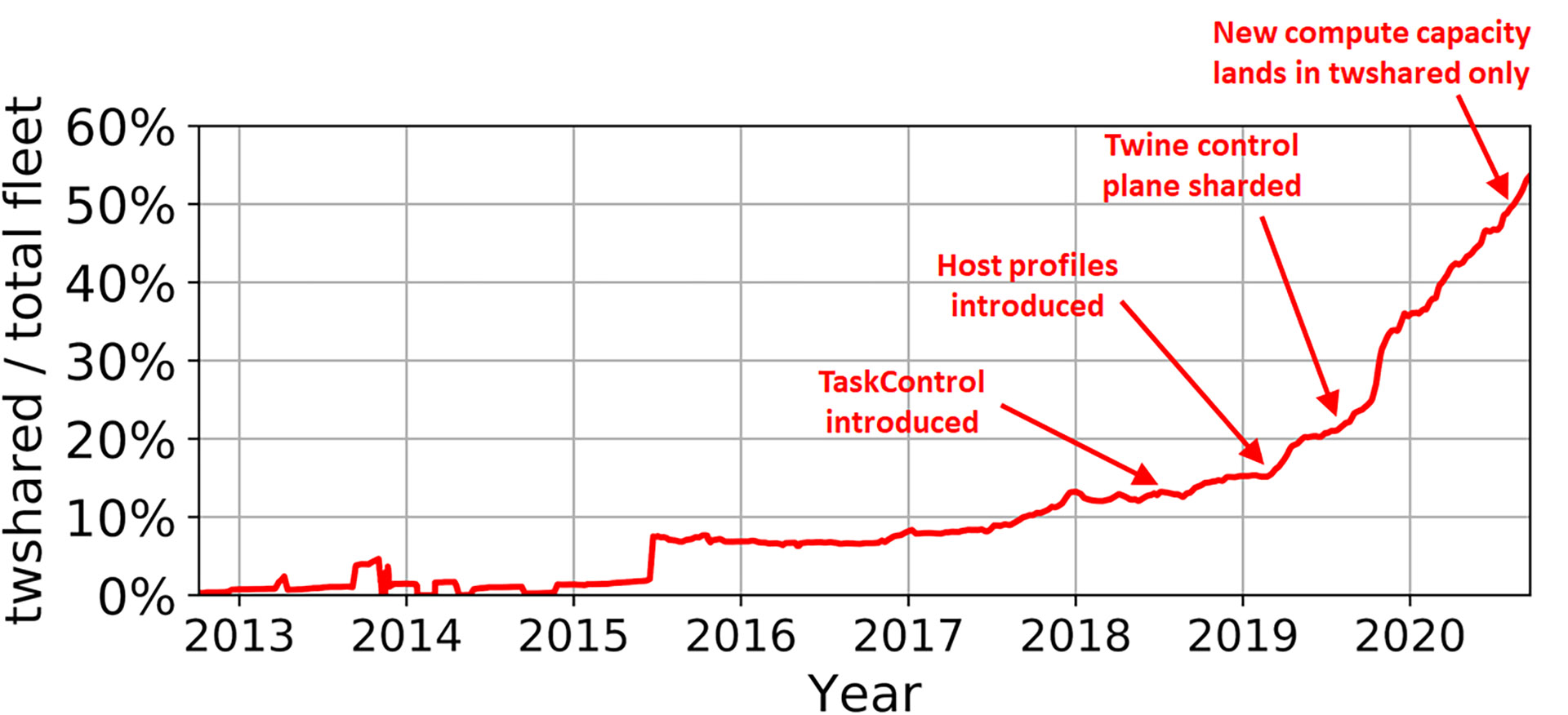
- We developed an interface called TaskControl to enable workloads to collaborate with the Twine control plane to manage software rollouts, kernel upgrades, and other machine life cycle operations.
- We use power-efficient small machines as a universal computing platform to achieve higher performance per watt. Moreover, we are moving our fleet toward a single compute machine type with one CPU and 64 GB RAM, as opposed to offering a variety of high-memory or high-CPU machine types. By using small machines in our fleet, we have seen an 18 percent savings in power and a 17 percent savings in total cost of ownership.
How it works:
The following features allowed us to rapidly consolidate diverse workloads into twshared.
Scaling a single Twine control plane to manage up to one million machines in a region:
In many cluster management systems, machines typically are statically assigned to clusters and workloads are bound to clusters. Isolated small clusters result in stranded capacity and operational burden as workloads cannot easily migrate across clusters. Twine forgoes the concept of clusters and uses a single control plane to manage one million machines across all data centers in a geographic region. Twine can easily migrate workloads across data centers without manual intervention. To scale to millions of machines, all Twine components are sharded and scaled out independently to avoid any central bottleneck. Unlike federation approaches such as Kubernetes Federation, Twine scales out natively without an additional federation layer.
Collaborative workload life cycle management:
Cluster management systems rarely consult an application about its life cycle management operations, making it more difficult for the application to uphold its availability. In one example, they may unknowingly restart an application while it is in the process of building another data replica, rendering the data unavailable. In another example, they may be unaware of ZooKeeper’s preference for updating its followers first and its leader last during a software release in order to minimize the number of leader failovers. Twine provides a novel TaskControl API to enable applications to collaborate with Twine in handling container life cycle events that affect its availability. For example, an application’s TaskController can communicate with Twine to precisely manage the order and timing of container restarts.
Hardware and OS customizations in shared infrastructure:
Our fleet runs thousands of different applications. On one hand, a shared infrastructure prefers standard machine configurations so that a machine can be easily reused across applications. On the other hand, applications benefit significantly from customizing hardware and OS settings. For example, our web tier achieves 11 percent higher throughput by tuning OS kernel settings such as HugePages and CPU scheduling. We resolve the conflict between host-level customization and sharing machines in a common infrastructure via host profiles. Host profiles capture hardware and OS settings that workloads can tune to improve performance and reliability. By fully automating the process of allocating machines to workloads and switching host profiles accordingly, we can perform fleet-wide optimizations (e.g., swapping machines across workloads to eliminate hotspots in network or power) without sacrificing workload performance or reliability.
Why it matters:
Many large organizations run diverse workloads on shared infrastructure, as it leverages economies of scale to reduce hardware, development, and operational costs. However, few organizations have achieved the goal of using one ubiquitous shared infrastructure to host all their workloads because of existing cluster management systems’ limited scalability and inability to support workload-specific customization in a shared infrastructure. Twine overcomes these challenges. We hope that sharing our experience in developing Twine advances the state of the art in cluster management and helps other organizations make further progress in shared infrastructure consolidation.
To learn more, watch our presentation from OSDI 2020.
Read the full paper:
Twine: A unified cluster management system for shared infrastructure








