
Hardware fails, networks partition, and humans break things. The job of our infrastructure engineers is to abstract these realities away and provide a reliable, stable production environment nonetheless. Two of the technologies we deploy in this pursuit are Twine, our internal container orchestrator, and Apache ZooKeeper. Twine maintains service availability by managing services in containers across millions of machines. ZooKeeper provides the primitives that allow distributed systems to handle faults in correct and deterministic ways. Components of Twine rely on ZooKeeper in some fashion for leader election, fencing, distributed locking, and membership management. Until recently, ZooKeeper rested squarely at the bottom of this stack with a clear, unidirectional expectation: ZooKeeper powers Twine, not the other way around. For this reason, ZooKeeper has historically been excluded from many of the rich features that our first-class containerized services enjoy.
Earlier this year, we migrated the last ZooKeeper cluster off its bare-metal home and onto the Twine ecosystem, which now manages 100 percent of our ZooKeeper deployments, including clusters that directly power Twine. An autonomous system now pulls the levers once tended to by human operators, freeing them to focus on solving interesting distributed systems problems, and we’ve jettisoned years of obsolete code in the process, but doing so has meant rethinking what it means to be a low-dependency service.
ZooKeeper at Facebook
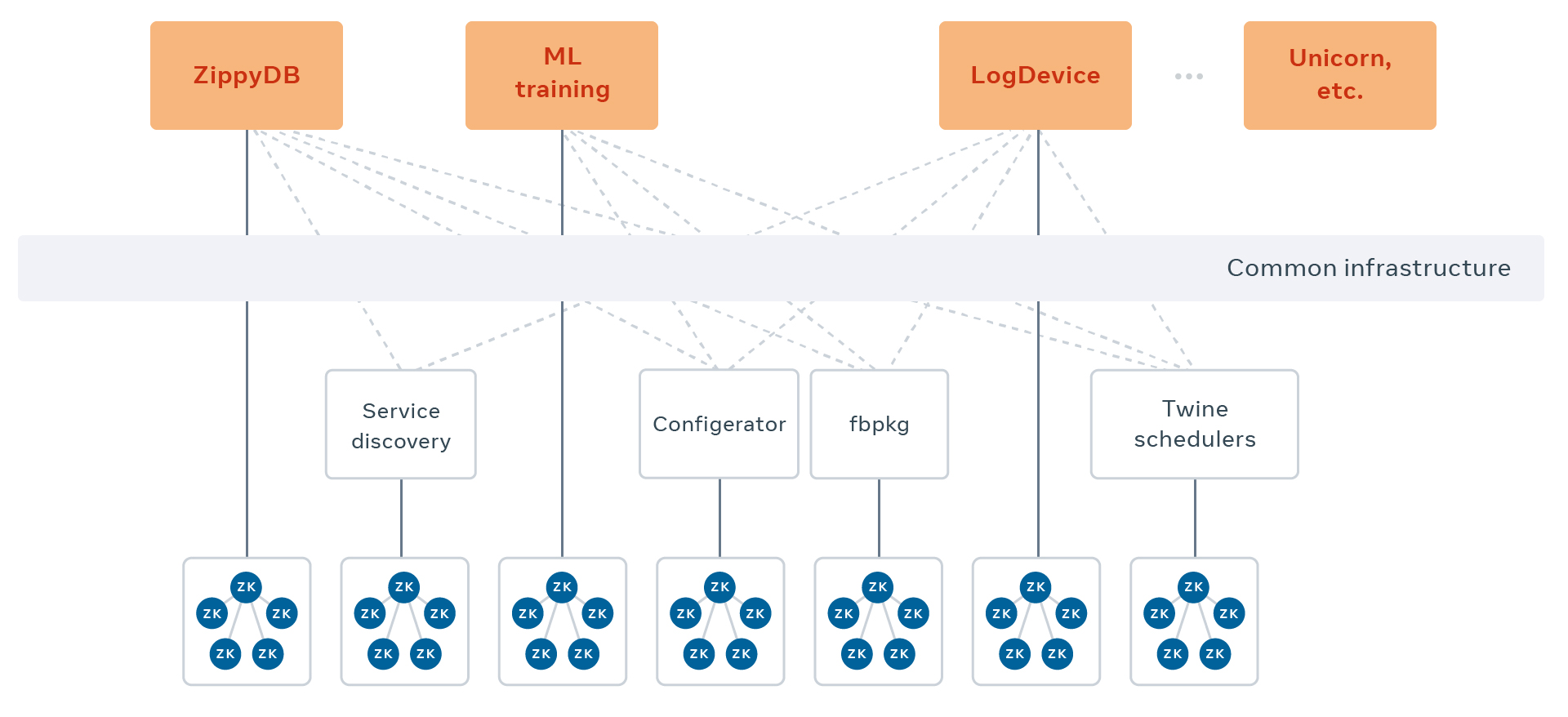
A single ZooKeeper cluster — an ensemble — is typically five participants, one of which is a leader that replicates data to the followers. Data or availability loss only occurs if three participants are simultaneously compromised, and ZooKeeper guarantees it will serve only the latest commit or no data at all. These attributes produce a linearizable, durable storage system for thousands of use cases, such as machine learning, Unicorn, and LogDevice, deployed across hundreds of ensembles.
Notably, ZooKeeper has become the standard low-dependency metadata store of choice for foundational infrastructure, such as:
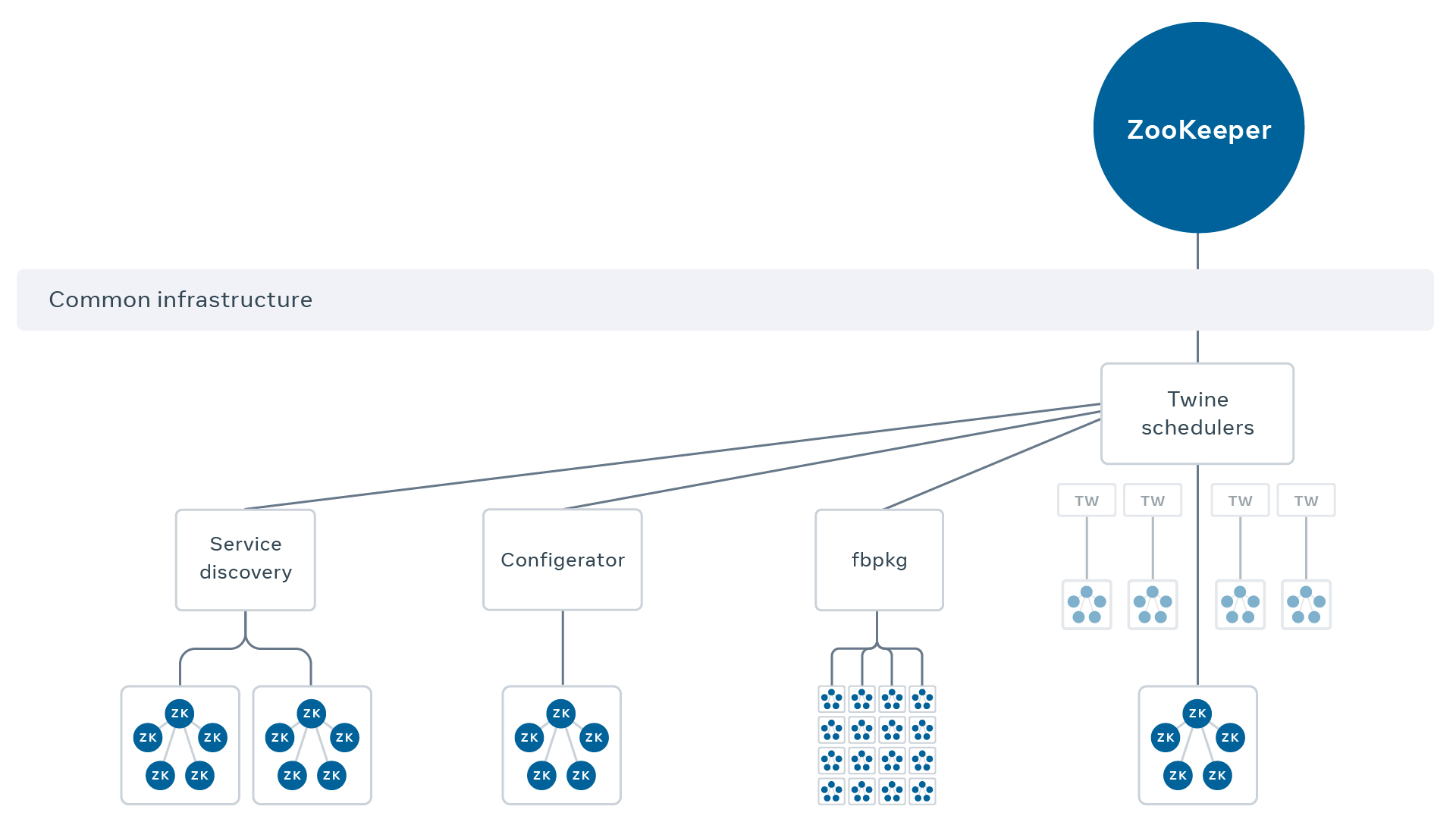
- Twine schedulers: Container life cycle management and placement
- Service discovery: Our production service endpoint catalog
- Configerator: Unified configuration distribution
- Fbpkg: Peer-to-peer package replication
These components work together to power Facebook’s containers: Schedulers connect to ZooKeeper via service discovery and operate in accordance with configuration from Configerator. The containers they schedule are composed of fbpkgs, the processes inside them consume configuration, and their endpoints are advertised by service discovery. All powered by ZooKeeper.
Given its position in the stack, ZooKeeper has traditionally been managed without our standard infrastructure, to avoid circular dependencies and ensure we can recover ensembles during a disaster. Over time, however, this strategy actually made it increasingly difficult to run a reliable service. Because we chose not to leverage common infrastructure, we didn’t ship ZooKeeper using Conveyor, our hardened deployment solution. Our alternative lacked the robust health check and revert capabilities available in Conveyor. We also built a custom solution to spread participants across failure domains — a duty typically handled by the scheduler — but we frequently found participants clustered in a single data center. We designed our own configuration distribution, as well, bypassing Configerator, but that solution lacked some of Configerator’s safety features like canarying and dead-simple peer review. Kernel upgrades, access control, machine decommissioning, and resource isolation were all reinvented. We even had to build custom tooling to restart our servers in a safe fashion. All of these alternate solutions required our engineers to spend time supporting duplicative code, whose bugs exclusively affected ZooKeeper, while Twine continued to evolve and release improvements that we weren’t benefiting from.
We began to wonder: What if we could lift ZooKeeper up the stack so it could run on top of the Twine platform, where it could enjoy first-class support, all the while powering it as if from below? Such an undertaking may sound absurd, but after years of managing our own infra, running anywhere else felt like sheer madness.
Containerizing is the easy part
Twine is two big pieces: A scheduler that manages container placement and life cycle — think Kubernetes or Apache Mesos — and the containers themselves. To run ZooKeeper on Twine, we knew we’d have to tangle with both. ZooKeeper runs on the JVM, which makes for some tricky resource sizing problems, but actually repackaging the software into a container is fairly straightforward compared to safely integrating with the scheduler. The scheduler supports a number of different resource management models, the gold standard being the Twine shared pool (TSP). In this model, containers run on a huge pool of managed hardware that is someone else’s responsibility. TSP engineers take care of everything: kernel upgrades, hardware remediation, maintenance events, capacity estimates, etc. To run on TSP, however, your service must play by the rules:
- Container RAM and CPU allocation is strictly enforced by cgroups.
- The scheduler can evict your service from a machine at any time.
- Twine will erase any side effects left on the machine once the scheduler decides to vacate it.
- The service owner is an unprivileged guest on the hardware.
In other words, TSP is great for stateless services that don’t write anything to disk. For teams that cannot tolerate these constraints, Twine supports private pools, which grant service owners greater flexibility in exchange for taking on the full responsibilities of hardware ownership.
Because our move to Twine was motivated largely by the headaches of fleet management, we decided early on that we’d make the switch only if we could find a way to run on TSP. Only the gold standard would make the immense engineering effort worthwhile. Yet in this mode, the scheduler is at its most ruthless: It knows nothing about the quorum requirements of ZooKeeper nor its commitment to data durability, but it will move containers and delete data as it sees fit. This is true even for ZooKeeper containers that store data essential to Twine itself.
Durability on a stateless platform is hard
An ensemble of five must keep at least three participants in good health, and if three replicas are destroyed, the resulting data loss is irreversible. So a change in the ensemble’s membership — the replacing of a failed host, for instance — is a notable event that requires a reconfiguration and generation of a new replica, during which the ensemble’s replication factor is reduced. We’ve historically managed membership changes by hand so that it’s simple and easy to intervene in strange circumstances. But manual control has an Achilles’ heel: Humans must react quickly to avert catastrophe in the event of widespread machine failure. With thousands of participants, it’s also burdensome toil: Hosts require maintenance frequently enough that our on-call became a human lever puller.
Fortunately, Twine is built to handle host replacements automatically — following our first host failure on Twine, it took us less than 90 seconds to find a suitable replacement, rather than the typical 12-hour response our engineers achieved. Watching this system move containers within seconds was awesome, but also nerve-racking: Twine treats its containers as black boxes and doesn’t replicate filesystem data when it schedules a replacement, so this responsibility falls to the ZooKeeper application layer in a way that’s opaque to the scheduler. Twine does, however, mark the abandoned data set for immediate deletion, so if Twine didn’t act conservatively enough when replacements went awry, we’d end up systematically destroying our infrastructure’s most valuable data.
It quickly became clear that we needed to inform the scheduler’s decisions with the heuristics of ZooKeeper quorum health. This meant deploying one of the company’s first task controllers, a scheduler enhancement that requires Twine to ask for permission before taking any action with our containers. For each operation — moving to a new host, starting or stopping a container, changing the size of a job — task control is allowed to acknowledge the operation or NACK it. This simple, powerful interface allowed us to build a nuanced set of guardrails for safe management of each ensemble’s data. Task control NACKS any operation that would jeopardize an ensemble’s durability, enforcing one-at-a-time operations and ensuring successful replication between them.
By requiring that our controller write data to the ensemble in question, we grant it the ability to persist acknowledgements between operations and detect when the ensemble is unreachable. In contrast to most Twine jobs, we want unhealthy containers to be rescheduled only if the rest of the job will be able to support the subsequent synchronization, and our task control programmatically enforces our priority: Preserve data, even at the expense of service availability.
Disaster readiness is harder
Having proved we could safely manage a stateful service on Twine, we had to address the elephant in the room: Could we avoid introducing the circular dependencies that haunted every box diagram we drew? ZooKeeper powers many systems high in our stack that don’t pose circular dependency risks, and initially we considered running those ensembles on Twine, while retaining core infrastructure use cases on bare metal. But such a setup would require maintaining our bespoke solutions while also operating on Twine, adding more complexity without eliminating any. So we committed to migrating 100 percent of ensembles to the new platform, which meant engineering escape hatches for each would-be cycle in our dependency graph.
While ZooKeeper serves data to many of the systems in the Twine ecosystem, it doesn’t power every aspect of them. Sure, schedulers can’t assign new containers to hosts while ZooKeeper is offline, but this doesn’t mean containers cannot run. Service discovery cannot receive writes in the absence of ZooKeeper, but network endpoints don’t suddenly stop accepting traffic.
In short, we could accept certain dependencies on these systems, but only on those components that were immune to ZooKeeper outages. This insight yielded a few practical capabilities we needed to solve for:
- Starting and stopping containers when the Twine scheduler was unavailable.
- Injecting configuration into ensembles while the Configerator network couldn’t serve reads.
- Informing ZooKeeper participants and select clients about the new location of an ensemble while service discovery rejected writes.
- Obtaining packages and binaries while fbpkg’s front end was offline.
These problems were dramatically simplified when we realized that such break-glass recovery techniques were needed for only a handful of use cases. After recovering the fbpkg ensembles, for instance, subsequent recoveries wouldn’t need the fbpkg escape hatch.
These solutions could be built just as they would for any other engineering project:
- Container control: The daemon that runs on each worker machine and manages its containers looks for instructions from a scheduler. With tooling built by the Twine team, we can commandeer this agent and schedule tasks on behalf of a human operator. All we need is the intermediate task specification we wish to execute — a JSON blob that’s straightforward to back up and manipulate.
- Configuration: Most of ZooKeeper’s configuration is static and read at startup, so we can alleviate the runtime dependency on distribution by prepackaging config snapshots at build time. Dynamic configuration, in turn, is written to the ensemble itself, just like our customer data.
- Service discovery: These ensembles are few in number, so we needed to solve service discovery only for a dozen ip:port tuples, rather than for the entire fleet. Our disaster recovery tooling operates with raw IP information — eliminating any role for service discovery during ZooKeeper recoveries — and these critical ensembles are assigned static, BGP-propagated virtual IPs that never change.
- Packages: While more than a dozen ZooKeeper ensembles power the fbpkg fan-out network, new packages are initially persisted in a low-dependency storage system prior to fan-out, in which ZooKeeper plays no role. We worked with the fbpkg team to develop a recovery mode that allows packages to be served directly from this source of truth when recovering critical ZooKeeper ensembles, bypassing the ZooKeeper-powered infrastructure altogether.
Together, these methods allow us to recover the ensembles that power low-level infrastructure during the most severe outages. However, nothing prevented more cycles from being inadvertently added to our dependency graph in the future, and because untested tools and runbooks tend to drift into staleness, we also needed a way to continuously verify these contracts and prove that every new build of ZooKeeper could be recovered in a vacuum.
To this end, we also built a completely new testing framework that exercises our recovery runbook in a severely deprived environment — one where virtually none of Facebook’s infrastructure is available. This framework validates every ZooKeeper release candidate, along with the affiliated DR tooling, prior to green-lighting the release for production.
Scale demands correctness
When we talk about problems being hard at scale, we often mean that a solution that produces correct results anything less than 100 percent of the time will eventually lead to catastrophic failure.
Consider how a single ZooKeeper failure could manifest if we didn’t get it right:
- Corruption of the source-of-truth data required for all service-to-service RPC routing
- Unavailability of blob storage, which serves all images and videos across our apps and services
- Deletion of millions of containers from our data centers
Let’s deep-dive on two nuanced examples:
100,000 membership changes
Twine hosts are rebooted every few weeks for upgrades, and containers are continually moved to achieve optimal resource usage. Each event requires the replacement of a participant in ZooKeeper’s membership list, and it’s realistic that we’ll see more than 100,000 such replacements over the next few years. With this in mind, we had to design the replacement process — called a reconfiguration — to ensure that it could not endanger an ensemble if the process were only partially completed. This ruled out early designs that had participants removed and added in favor of atomic swaps that actually healed misconfigurations upon retry.
When an ensemble leader distributes a new transaction to the ensemble, it counts how many followers have recorded that transaction to their write-ahead log and issues a corresponding commit message only once a majority of participants have done so. Each participant, therefore, must be uniquely identified so that its vote is counted separately, so each is assigned a logical Server ID (SID). Twine assumes that all containers in a job are fungible, however, so generating unique SIDs is no trivial problem. For legacy reasons, ZooKeeper’s SID is 64 bits, but uniqueness is required on the lowest eight bits: 2^8 is far too small for any randomization technique, so we originally opted to use the task identifier provided by Twine, which assigns a sequenced number to each container in a job.
We soon found out that task ID alone is insufficient. A network partition between one participant and the Twine scheduler leads the scheduler to produce a new, duplicate task on another healthy machine, assigning it the same identifier. For a period shortly after the partition mends, we have two participants submitting durability votes on each other’s behalf — a dangerous violation of ZooKeeper’s consensus requirements that could jeopardize our data’s durability.
To address this, we had to derive a unique 8-bit identifier from both the task ID and the task version number, which the scheduler uniquely assigns to each rescheduled participant. Yet there was no obvious way to produce a unique 8-bit value from these combined 40 bits of input until one of our engineers volunteered a creative solution: What if we used the current ensemble membership as a historical record of previously assigned, monotonic 8-bit identifiers? We designed SID assignment logic such that XOR-ing the full list of 64-bit participant identifiers, then applying a bitmask, would indicate the value in the 0–255 range that had been least recently assigned. We could incorporate this result in the lower 8 bits of the SID assigned to the next participant.
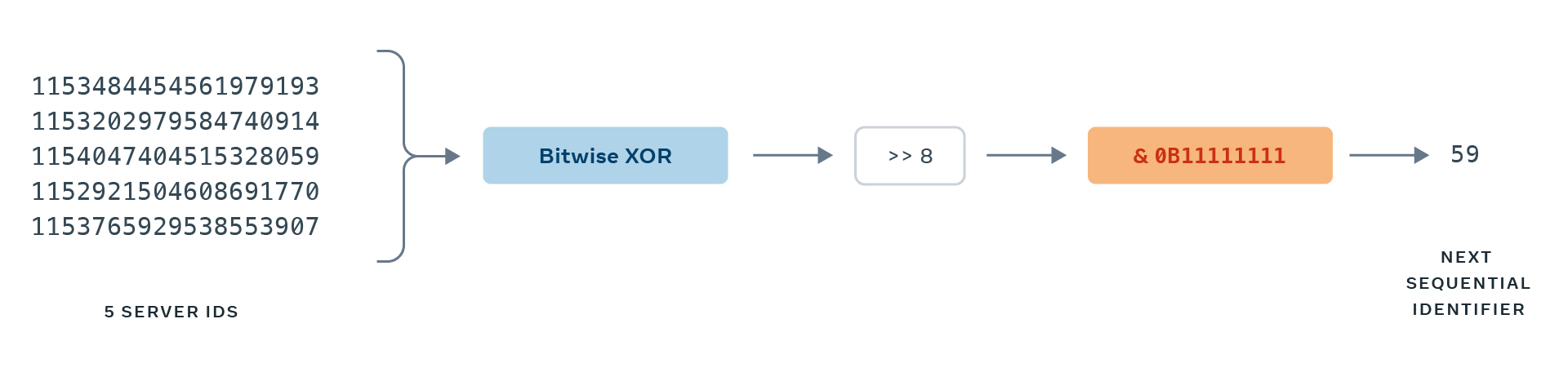
Given we never run ensembles with anywhere close to 256 participants, we could safely increment this assignment and ensure that we’d never wind up with multiple contemporaneous tasks that shared the same SID.
Kernel behavior and 100th percentile tail latencies
Some of our ensembles incur extremely heavy workloads, with spikes over 100 million read requests per minute and 500,000 writes per minute. Early in our migration onto Twine, we found that these heaviest workloads would exhibit occasional latency spikes not encountered in matching workloads on the legacy deployment model. Weeks of investigation indicated we could expect a dozen single-point violations of our one-second latency SLO every few hours, but only under specific load conditions on particular hardware configurations.
The Twine container environment differs from our bare-metal hosts in many ways: kernel version, TCP congestion algorithm, sysctl settings, and cgroups configuration, to name a few. To isolate the underlying explanation of our newfound latency spikes, we systematically mutated our container hosts until they resembled their legacy bare-metal counterparts, rolling back kernel settings and file system differences along the way. The regression abruptly disappeared as soon as we disabled the cgroup v2 memory controller. This controller manages the memory limits imposed on our containers, and by disabling it, we effectively allowed the container to consume an entire machine’s RAM supply. Something about the memory constraint was responsible for the occasional latency spike.
Through partnership with our kernel maintainers, and thanks to new container pressure metrics, we were able to correlate the latency with cases where the container experienced elevated memory pressure but the host itself did not. Using bpftrace — a magical tool that lets us inspect and time kernel function calls — we attributed each latency spike to an application-layer stall induced by direct page cache reclaim. Page reclaim is the kernel’s means of freeing pages from the filesystem cache when free memory becomes scarce. Modern Linux systems handle this page recycling behind the scenes through an asynchronous kernel thread called kswapd. However, this thread only kicks in once the host experiences sufficient memory pressure, indicating the depletion of free pages. By containerizing ZooKeeper, we were artificially constraining the supply of memory to the process, and some RAM was reserved for ancillary workloads elsewhere on the host. Occasionally, under high load, we would trigger memory pressure at the container’s scope but not at the global machine scope, which meant kswapd never kicked in. In cases like these, our application was forced to incur the cost of recycling pages directly, inline with page requests, sometimes producing multisecond stalls in our tail latencies.
A typical investigation might end at this point, mitigating the issue by awkwardly resizing our containers. But we like to go a step further: We landed a kernel patch that extends kswapd behavior to containers under pressure. Now that it’s released, every container we run can reap the benefits, and we’re working to upstream the patch to mainline Linux.
Everything elastic
Some of the biggest rewards of this solution only became clear after we migrated the entire fleet of ZooKeeper ensembles onto Twine. Now that our service is no longer coupled to physical hardware or manual placement, everything about how we operate ZooKeeper, and what we can do with it, has changed:
- Fractional workloads: Previously, we required five whole machines to compose a new ensemble, but now we need only five containers. For small workloads, these containers can use fractional machines while enjoying strong isolation from neighboring workloads, and we can bin pack them efficiently on heterogeneous hardware.
- Dedicated ensembles: By sizing our containers to their workloads, we also simplify how we manage tiny workloads that have historically been colocated in shared ensembles. Now, we’re splitting them apart so each workload can grow independently without fate sharing or noisy neighbors.
- Effortless scaling: Offloading our infra needs to Twine has driven the marginal operational burden for each new ensemble toward zero, allowing us to deploy new ensembles based on customer need rather than on operational considerations.
- Novel automation: Empowered by Twine’s APIs, ensemble life cycle management is now fully automated. This has unlocked new workflow-driven, live data migrations and ensemble splitting, along with new region turn-ups and even short-lived ensembles dedicated to a single integration test.
Cultural direction from the foundation layer
At many companies, it is unusual for the foundation layer of infrastructure to make bold bets on new ways of operating software. But for us, ZooKeeper became the lowest layer of our core services to run stateful, low-level infrastructure on the fully managed TSP. This milestone paves the way for others who may still be stuck in the quagmire of managing their own hardware. It also intentionally sets a clear bar: Twine is mature enough to run the most fundamental components of Facebook. Today, we see other projects migrating low-level, stateful services onto the platform, including TAO and LogDevice.
Safely running a low-dependency service atop a dynamic container orchestration platform takes a lot of attention to detail. Migrating hundreds of ensembles with complete transparency takes perseverance. And powering that platform from the very containers it schedules requires a deep reflection on disaster readiness, not to mention just a touch of madness. But it’s brought ZooKeeper at Facebook into the future, and it enables our team to provide stable, reliable infrastructure that can move at light speed.








