
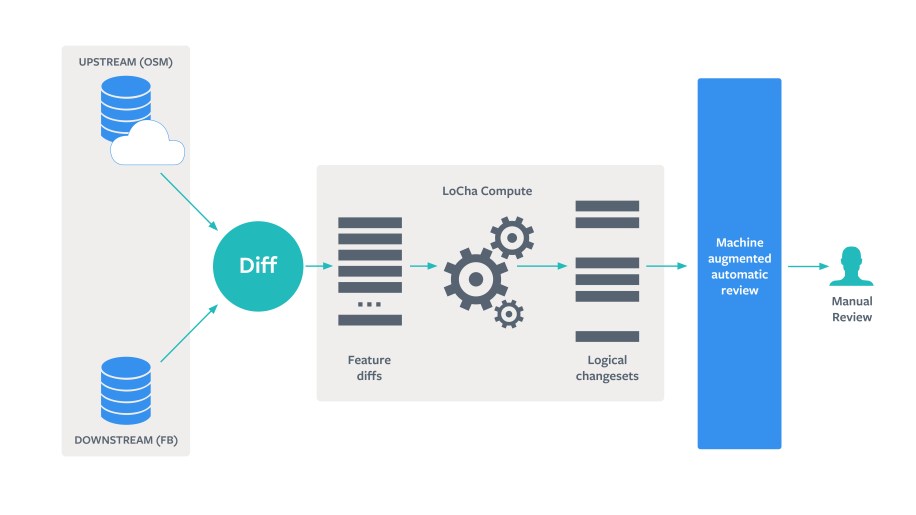
The maps people use on many of our apps to shop, find jobs, support causes, and more are all powered by OpenStreetMap (OSM). OSM is a community-driven project built by mappers all over the world who contribute and maintain data about roads and locations. The OSM global copy receives up to 5 million changes every day, which means our local copy would quickly become outdated if we didn’t regularly update it. To reduce the risk of bad edits, whether intentional (vandalism) or unintentional, we don’t update our local copy directly. Instead, changes between the two versions are reviewed and accepted into the local copy. This all needs to be done on a regular cadence, or the growing difference between the global and local versions will require significant time and effort to catch up. We developed two new tools to help us keep pace: Logical changesets (LoChas) and our new machine-augmented automatic review system (MaRS).
LoChas break OSM changesets into individual CRUD operations and then cluster them for more efficient human review. MaRS uses a blend of heuristics and machine learning (ML) techniques to automate evaluation of LoChas that don’t require a further nuanced review. The ultimate goal of these tools is to create a funnel where machine-augmented techniques reduce the workload that requires human intervention.
How OSM works
OSM uses changesets, a collection of CRUD operations to update the data created by a single contributor in a single session (analogous to commits on a source code repository). The data from OSM is made available for download as a Planet file, which is an interchange format. It has a rich ecosystem of tools for read/write and conversion workflows but isn’t designed for direct querying. So we, like most consumers of OSM data, have an internal storage format (a local copy).
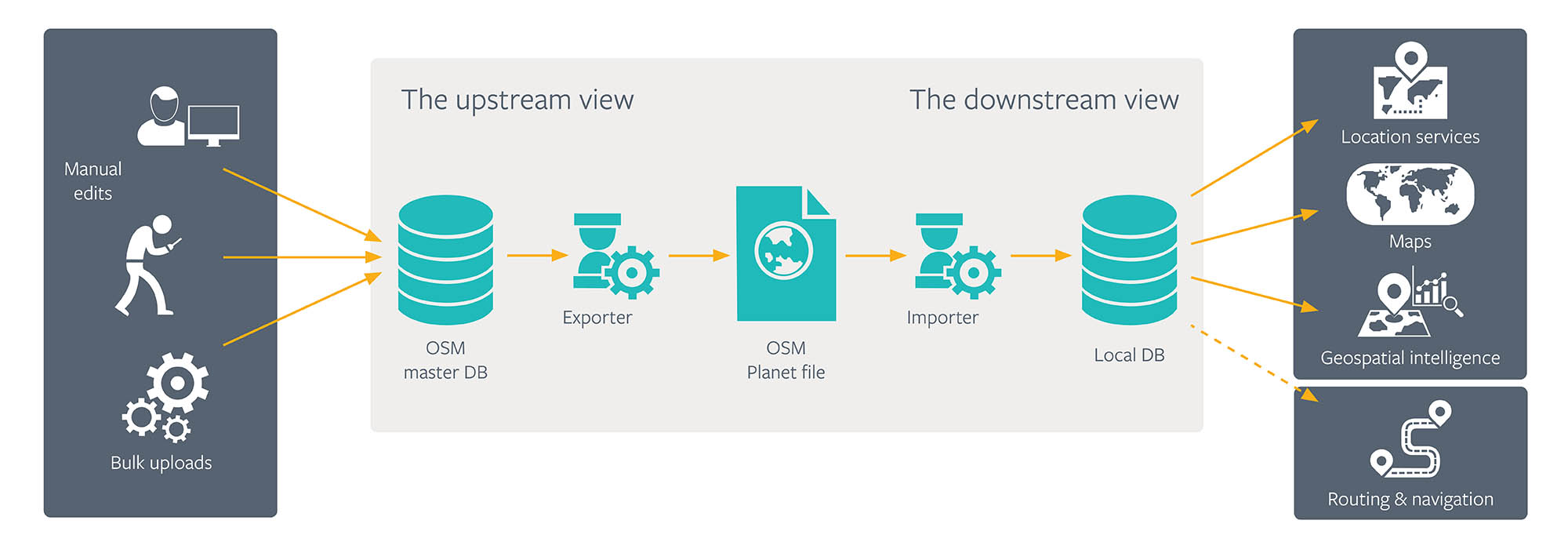
The OSM master database is updated via community edits and periodically exported into OSM Planet files for download. The Planet file is then downloaded and converted to a local storage format via an import pipeline, which makes the data available to the eventual consumer services and applications. OSM represents the world via nodes, ways, and relations:
- A node represents a point feature that might indicate either a standalone point with latitude or longitude, or a constituent of a way.
- A way represents either a line string, a closed loop (inner/outer), or a polygon. It has an ID and a list of the nodes that make it up.
- A relation is a grouping of two or more member entities, which allows us to create associations between entities with clear role assignment to each. The associations may be geometric (e.g., inner loops in polygons, polygons contained in multi-polygons) or logical (e.g., bus routes consisting of multiple ways).
The OSM data contains a list of geometric features along with relations. The Planet file is laid out as three ordered lists — one each for nodes, ways, and relations. Each OSM entity has a 64-bit ID and a list of free-form key-value string tags describing it.
Existing approaches and limitations
Any solution for keeping pace with upstream OSM has to maximize twin goals of freshness (keeping the internal copy as close in age to OSM master as possible) and correctness (as correct a representation of the “real world” as possible). Of these, correctness is an invariant for us (i.e., we can’t show wrong data), and we have some leeway on the freshness axis (the local copy can be up to X days behind the OSM master). Our World.AI Ingestion and Integrity engineers are thus tasked with keeping our map data as fresh as possible while maintaining maximum possible correctness.
Current approaches to keeping OSM data updated primarily focus on tackling the two axes separately. Correctness is ensured by watching for and flagging suspicious changesets (e.g., OSMCha) for human review, then quickly reverting them in the OSM master. This approach kicks the can down the road for maintaining correctness and requires staying up-to-date on the master. Freshness is achieved by simply consuming upstream changesets faster, or essentially rebasing the local copy with the upstream master on a regular cadence (e.g., daily or weekly). The trade-off here is that if we make the data too fresh, we run the risk of increased incorrectness and shrink the window for detecting and reacting to such incorrect data.
For example, if we consume OSM with no delay, any bad edits that get past our review will show up immediately in our maps. A staggered approach to consuming OSM (say, delaying it by a couple of weeks) punts the issues to a later time but still doesn’t guarantee that we would catch any incorrect data in time. Additionally, for every delay in consuming the OSM data, the eventual attempt to catch up has to deal with an increased volume of changes, thereby requiring even more effort and time. Thus we knew we needed a better alternative than current approaches to be able to ingest OSM as quickly as possible yet maintain an accurate representation of the world.
After examining existing solutions, we realized that current approaches base their view of reconciling OSM updates on one of the following two approaches:
OPTION 1: Go big or go home (aka the static diff approach)
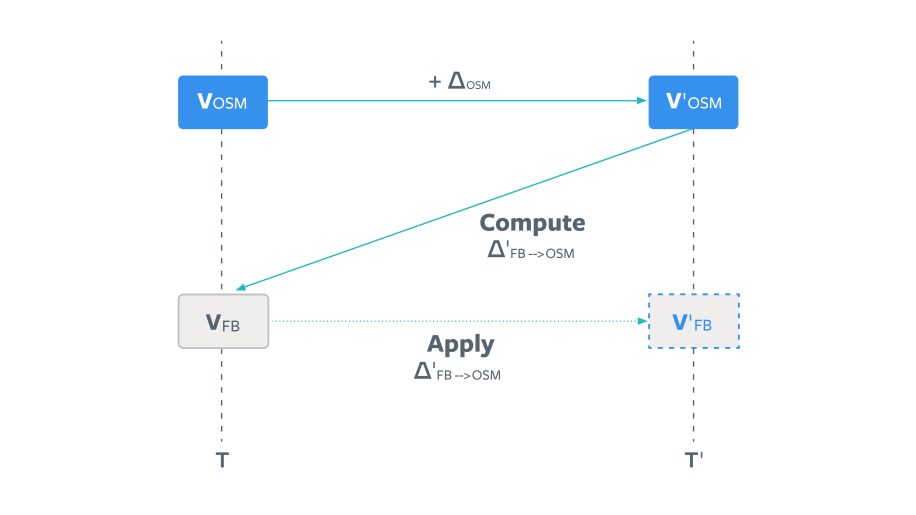
To update a downstream copy at time T based on upstream version V(OSM) to a version based on V'(OSM) at time T', we can compute a monolithic diff DELTA(FB→OSM) that updates the local copy V(FB) to V'(FB). For a long period of time, this represents a very large diff — almost equivalent to reviewing the whole world one change at one time.
OPTION 2: Drinking from the fire hose (aka continuous/streaming diff approach)
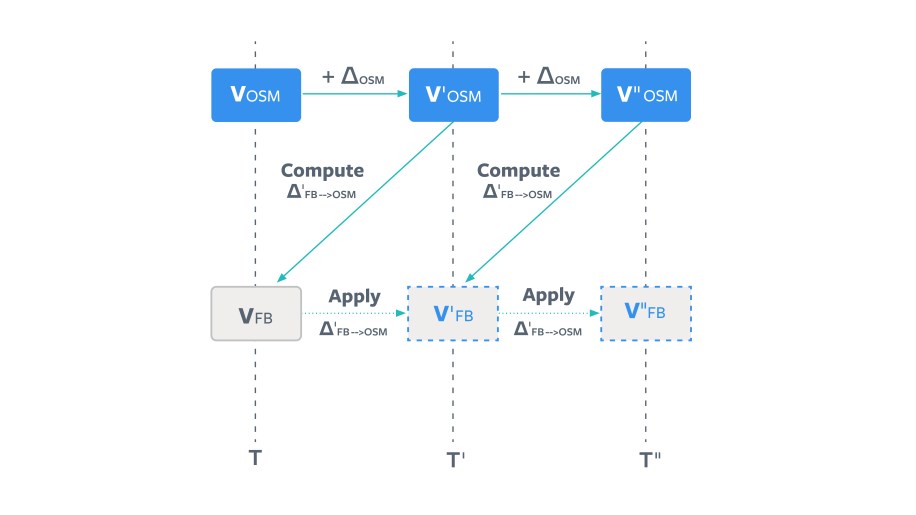
Alternatively, we can process all the changes between the two versions sequentially and incrementally update the local copy to catch up to the final one. This doesn’t really alleviate the workload of option 1; it just splits it into incremental or sequential chunks. Also, repeated edits that were reverted (the “ABA” situation) are blown up into redundant tasks that need to be processed sequentially to be correct.
Both of these approaches are limited by a single central assumption: that catching up to OSM is all or nothing. This assumption also compounds the fact that as we run vandalism detection and integrity checks that find actual problems, we end up amplifying the amount of work required to approve the changes and ingest them properly into our local copy. There’s no easy way to preserve geometric correctness unless we process and apply all the changes — then do the same for the changes that are generated to fix the problems found. Most current approaches also try to blend aspects of editing with the ingestion system and thus make the mechanics more complicated (akin to a merge workflow for forked codebases).
Our solution: LoChas
In 2018, the Facebook World.AI team began work on ingestion and integrity, based on a single epiphany that invalidated the core assumption mentioned previously and opened up a simplification that allowed us to create an optimized continuous ingestion system for catching up to OSM. The question we asked ourselves was simply “What if we could update portions of the OSM data without going through the whole world, while maintaining geometric validity?”
We used a hybrid of the two approaches described above:
- We calculate the absolute diff between the two OSM versions (from option 1 above).
- We then split this diff into a set of LoChas that can be individually applied (from option 2).
We also add a constraint that the upstream copy of the OSM is the only mutable copy. The local copy can accept only changes made upstream and can’t be written to directly. With this immutability constraint in place, the LoChas have some fundamental mathematical properties that alleviate the workload and issues arising from the sequential nature of the current approaches. The computation works as follows:
Let V(OSM) be the current OSM Upstream Master version.
Let V(Downstream) be the current downstream local copy version
based on an earlier version of upstream.
Now, Diff(Downstream→OSM) = V(OSM) – V(Downstream)
We create a function f where
f(Diff(Downstream→OSM)) = {LoCha 1, LoCha 2, …, LoCha N}Such that each LoCha:
- Is idempotent (accepting and applying a LoCha multiple times has the same effect as applying it once)
- Is commutative (can be applied in any order)
- Has a binary accept or reject decision
- Is guaranteed to be geometrically correct for either outcome
- Is independent (any or all of the LoChas can be applied or rejected and can be processed in parallel)
Another way of thinking about this approach is that it breaks the net delta (a set of actual OSM changesets) between two OSM versions into individual CRUD operations and then clusters them into LoChas, which are optimized for efficient human visual review.
The LoCha algorithm
The current LoCha generation algorithm leverages the containment and connectivity information of the features to cluster the individual changes. Here’s how it works on a simplified “world” with a small number of ways and nodes. The algorithm leverages the connectivity information in the graph to propagate the changes from the originating graph vertex to its neighbors. This determines the subgraph of coupled graph vertices that will be affected by this change and collates the members of that subgraph into the LoCha. This ensures that the before and after scenarios of advancing the version by applying the LoCha are both guaranteed for geometric validity. The following images illustrate the algorithm at work with a “toy” world made up of three ways and 10 nodes.
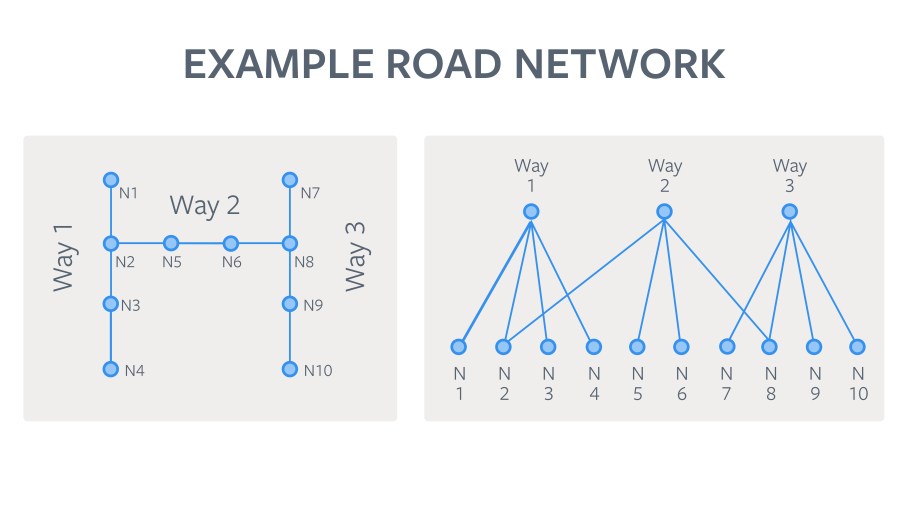
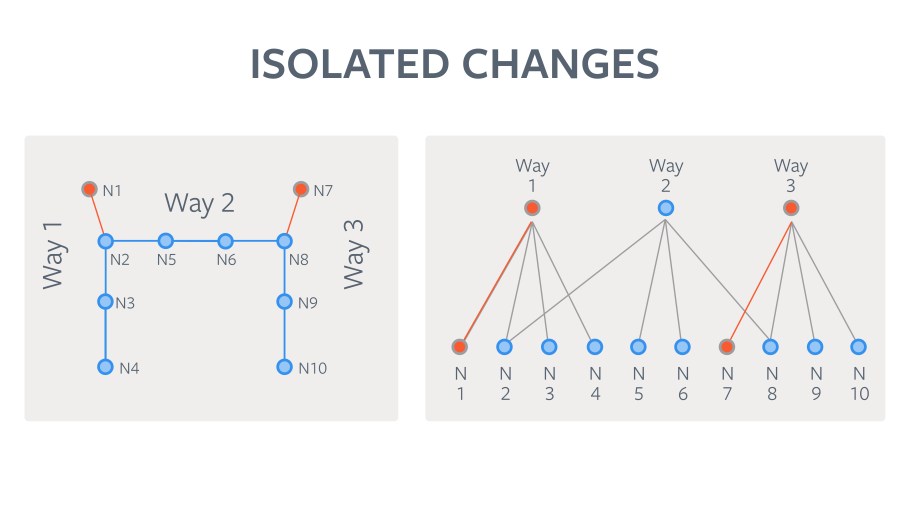
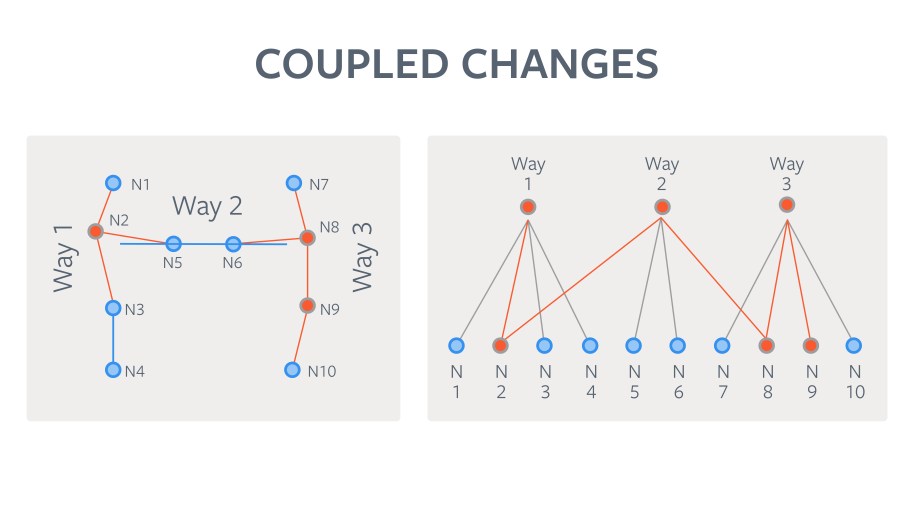
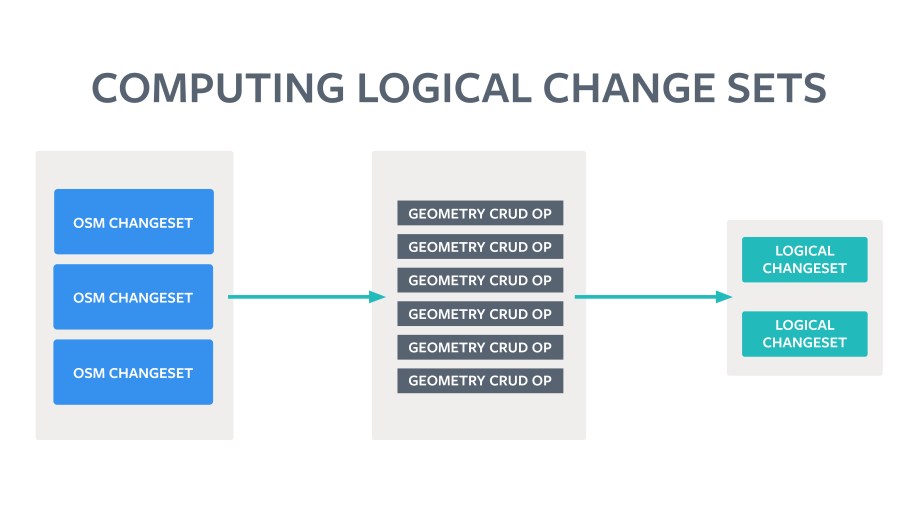
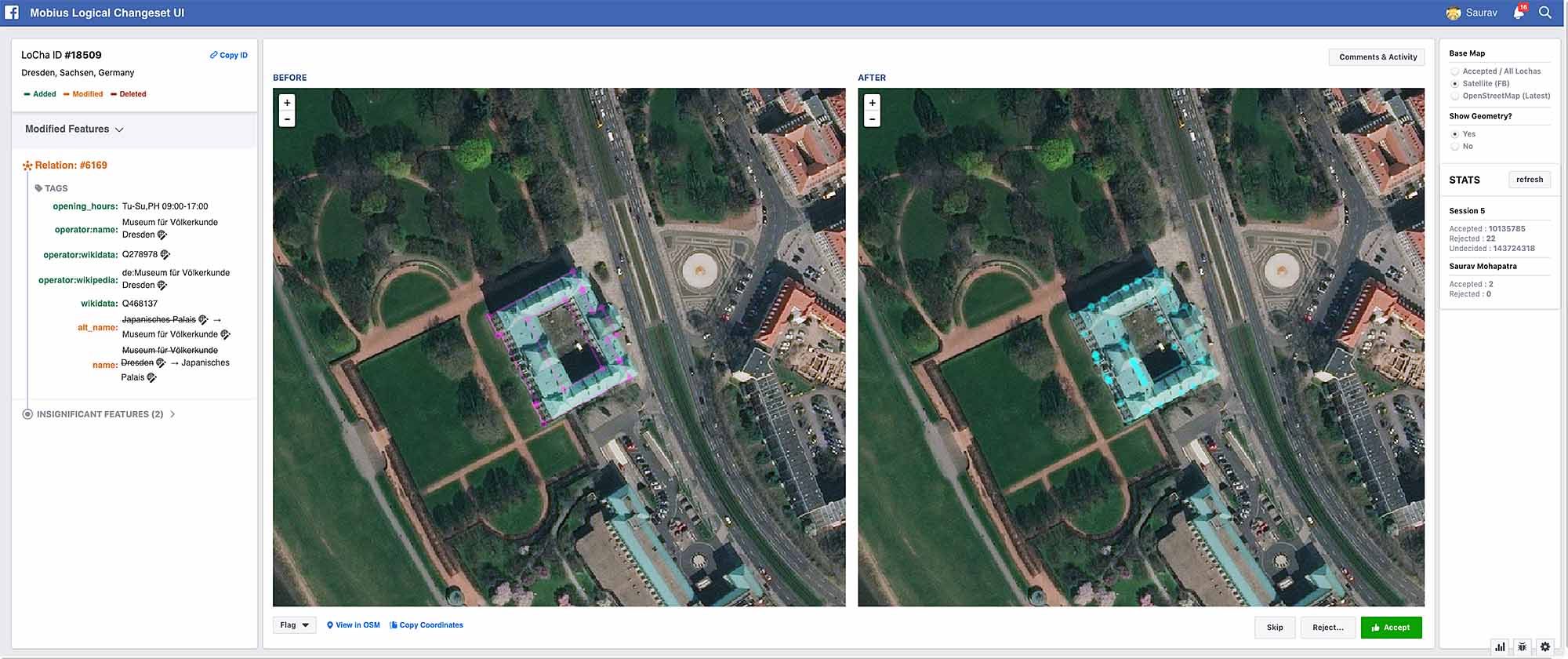
Once the LoChas are computed, the logical grouping makes it efficient for a human to view the before and after versions in a custom diff UI and quickly decide whether to accept or reject the changes. If any feature in a LoCha is rejected, the entire LoCha is rejected. When a LoCha is accepted, it is converted to a transaction consisting of the individual CRUD operations and applied to the local database, which moves the features touched by this set of changes forward. If rejected, the versions of the features included stay as-is. In either case the geometry remains valid.
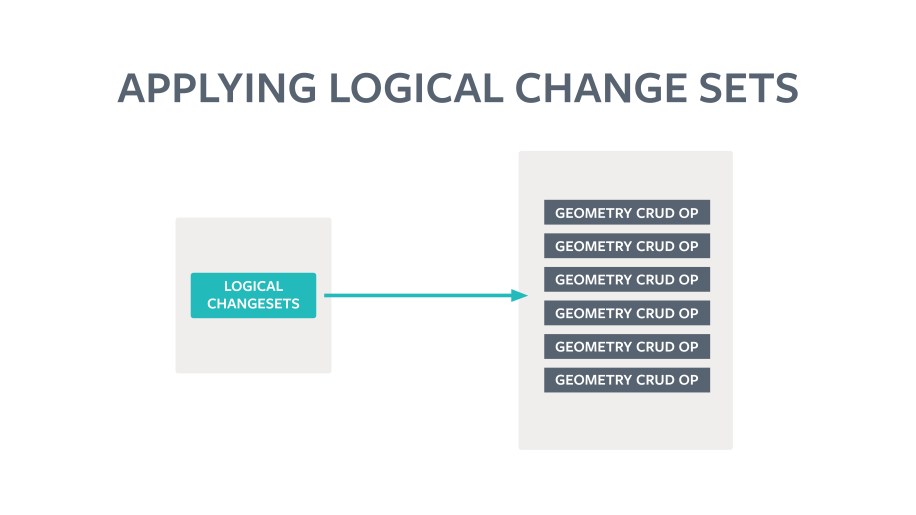
Thanks to the properties of the LoChas and the way Mobius handles reviewing and applying changes, we see several benefits. We can now trigger the LoCha generation between local downstream copy and the upstream OSM master at a regular cadence. Each of these reconciliation sessions produces a set of diffs that logically cluster all related changes for rapid review. We don’t have to even review all the diffs. We can focus on priority areas and feature types and ignore the rest. Each accepted diff forwards the versions of the individual features in the local copy to latest, while keeping the geometry valid. Any changes not captured in this session will be captured by the next one.
Toward automated review
For our first pass and proof-of-concept, we ran this ingestion and integrity workflow over our maps for Thailand and were able to ingest three million changed features in just over a month using a very small team of mappers. However, this process also highlighted a bottleneck in the process. To put this in context, the OSM Planet file has approximately 6 billion nodes, 600 million ways, and 7 million relations. Approximately 30,000 change sets are submitted each day, amounting to roughly 5 million individual changes to features.
To meet our goals of freshness and correctness for the whole world, Mobius needs to process upward of 1.8 billion individual feature changes every time we ingest. To do this with human reviewers alone is not scalable for this volume of changes. That said, human review is an essential part of the process — it provides much-needed nuance when triaging tricky changes to features (e.g., areas of the world under dispute, subtle cases of vandalism, and bad edits).
In simple terms, our objectives became:
- Maximize automated review
- Minimize human review
- Maximize efficiency of review workflow
To address the efficiency objective, we invested in workflow automation as well as an improved UI for Mobius. However, an even bigger investment was focused on machine-augmented automatic review to alleviate the load on the human review pipeline while making sure that the cases that require a nuanced review are still surfaced to human reviewers.
How map data changes are reviewed with MaRS
At a high level, a map change is vetted by a reviewer, and one of three decisions is reached:
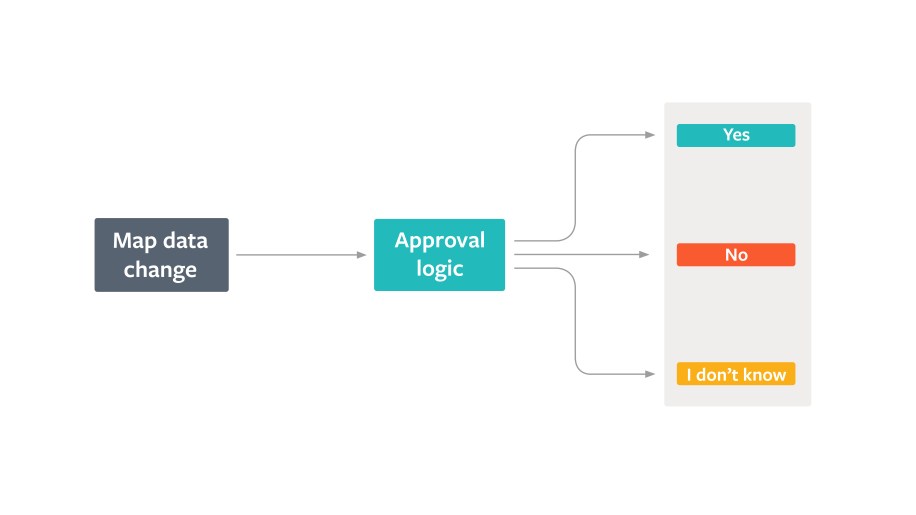
If we were to apply this to an automated review context, the yes and no are high-confidence decisions and are automatically processed, and the I don’t know (IDK) low-confidence lot gets flagged for manual review. In other words, we needed to maximize decisions that automated review can do with high confidence to reduce the volume that goes through the manual review pipeline. We started by subtly enhancing our mental model of map-change evaluation to capture more of the nuance that human reviewers provide.
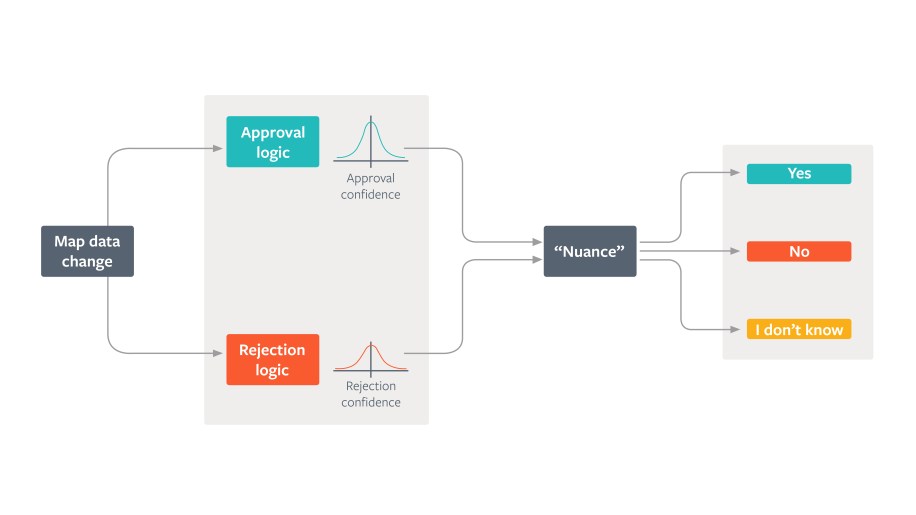
We built MaRS to sit between the computed LoChas and the manual review process. The machine-augmented review leverages a blend of heuristics and ML techniques towards automated evaluation of logical changesets. The goal is to reduce the volume of changes that require manual review. At a high level, the system is built as a rule engine. The current version uses a simple composition strategy of logical AND-ing the rule scores.
Stage 1: Per-feature scoring
The OSM feature is first classified by its type and the nature of the change that was made to it (create, delete, or modify). Currently the automatic review system is biased toward modify, since the most powerful of its heuristics target semantic and geometric changes of the feature’s before and after versions to determine whether the change is significant enough to warrant human review. However, we have AI-powered rules that currently target create and delete as well.
Stage 2: Per-LoCha evaluation
The system collates the features based on which LoCha they belong to, in order to build a list of LoChas that consist of entirely auto-approved features. (A mathematical property of the LoCha compute is that a feature is guaranteed to be in one and only one LoCha.) We auto-accept the LoChas with all approved features and remove them from the manual review queue. The per-feature scoring also reduces the eventual complexity of the LoChas sent for manual review by hiding the auto-approved features from the default view. If any feature is rejected by the MaRS review, the entire LoCha is auto-rejected.
The rules
Our current rules are built on top of checks (individual pieces of evaluators for feature changes that leverage heuristics, AI, and Computer Vision). The rules provide the low-level composition logic and can use one or more checks (along with conditionals) to provide a decision about a feature change. The engine itself acts as a compositor of individual rule decisions and makes the final decision.
These rules represent a combination of domain knowledge we gathered from map reviewers as well as patterns we inferred from the manually reviewed LoChas and OSM features from previous runs of the Ingestion and Integrity sessions. A few of the important rules currently in action in our automated review system are:
Algorithmic curve similarity
This rule uses a variant of Discrete Frechet Distance metrics (with some modifications to make it a faster check) to compute the similarity between the before and after versions of OSM ways. This is combined with other checks (vertex count, curve length, bounding box/centroid deltas, etc.) to create a combined change metric. We threshold the change metric to determine whether the curve characteristics have been altered significantly enough to warrant review.

Metrics
This rule uses checks that look at the complexity of the change as well as the history and quality of a submission to determine a probability of a particular change being a bad edit.
Truthiness
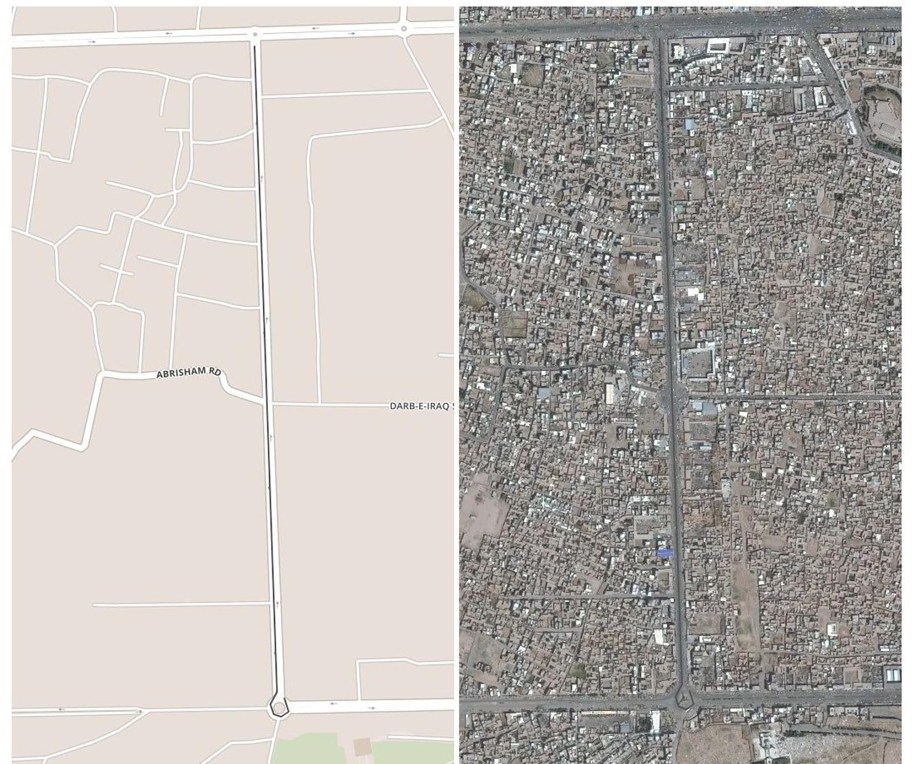
Truthiness is an AI-assisted check that looks at roads created and compares them with satellite images to find out whether there’s a real-world basis for each change. If we find a matching real-world road, then MaRS approves the create. This rule builds off of our teams’ work on AI-assisted road mapping. In fact, it does the inverse of how we infer roads out of satellite images. The truthiness rule uses satellite imagery as a basis to determine whether the changed or created features have any correlated visual counterparts. This correlation is then translated into a confidence metric of the change being good.
Significant tag change
Since OSM tags are freeform key-value pairs, we use a combination of ML and heuristics to evaluate the significance of the tag change and to check for profanity (“Does this significantly alter the characteristics of a feature?” or “Does this name change contain profanity or obscenity?”). This rule builds off of our work on integrity and profanity detection as well as some map data–specific techniques developed by the World.AI team.
Adaptive strictness of checks
Though it’s technically not a rule, a significant technique used in the system is to adaptively lower the strictness of the checks as well as the acceptance threshold, if a change is stable. For instance, if the last time a feature was changed was, say, more than a year ago, we can use a higher tolerance for changes made to the original feature. This allows us to process old and stable changes at an increased volume. These changes have a reduced set of heuristics and checks done before final approval and are also more likely to be marked for spot checking.
How we did
 In the latter half of 2018, our first proof of concept targeted ingesting OSM features in Thailand via mostly manual review. We did have some rudimentary heuristics-based automation around features added by the FB mapping team. The first pass of the review UI provided a basic experience to our validators. We were able to ingest around 3 million OSM features (fully approved LoChas) during this phase.
In the latter half of 2018, our first proof of concept targeted ingesting OSM features in Thailand via mostly manual review. We did have some rudimentary heuristics-based automation around features added by the FB mapping team. The first pass of the review UI provided a basic experience to our validators. We were able to ingest around 3 million OSM features (fully approved LoChas) during this phase.
In 2019 so far, with a similar-size team and our MaRS (and a refactored UI) in place, we targeted ingesting the whole world with a similar-size map review team and were able to get ~75 million OSM features into the new map version.
The figures above represent features that consist of entirely approved LoChas. With the per-feature scoring system, we were able to get close to 90 percent automated approval (approximately 1.6 billion features auto-approved out of approximately 1.8 billion total changed features).
The road ahead for MaRS
MaRS allows us to minimize human review while maintaining correctness. As OSM grows in popularity and participation, we expect the volume of changes to increase. Our goal is to keep pace with all the changed features at a regular cadence, so we need to keep increasing the volume processed by MaRS while maintaining accuracy and confidence in the changes that we auto-approve (or reject).
To this end, we are exploring the following areas for possible future iterations of MaRS:
- Extend the composition strategies of the rule engine beyond simple logical AND-ing, and allow for more expressive and complex composition strategies.
- Create more AI-powered rules to target
createsanddeletes, since those commands have only one version and heuristics-based evaluation is more suited tomodifies, which have before and after versions. - Extend truthiness to other geospatial types (buildings, water bodies, land use, etc.).
- Enhance the NLP-powered tag change significance (i.e., given my use cases, how significant is this tag change?).
- Conflate and cross-validate with other datasets (i.e., can I use my existing data sets as provisional ground truth? Points of interest, government or public data sets, survey data, etc.).
- Rethink our approach towards change processing from the top down (cartographic and semantic modeling of the changes, generative and/or Bayesian modeling of the map validation logic, etc.).








