
Most machine learning tasks — from natural language processing to image classification to translation and many others — rely on derivative-free optimization to tune parameters and/or hyperparameters in their models. To make this faster and easier, we have created and are now open-sourcing a Python3 library called Nevergrad. Nevergrad offers an extensive collection of algorithms that do not require gradient computation and presents them in a standard ask-and-tell Python framework. It also includes testing and evaluation tools.
The library is now available and of immediate use as a toolbox for AI researchers and others whose work involves derivative-free optimization. The platform enables them to implement state-of-the-art algorithms and methods to compare performance in different settings. It also will help ML scientists find the best optimizer for specific use cases. At FAIR, the Facebook Artificial Intelligence Research group, researchers are using Nevergrad in a variety of projects in reinforcement learning, image generation, and other areas. It’s helping to better tune ML models in place of parameter sweeping, for example.
The library includes a wide range of optimizers, such as:
- Differential evolution.
- Sequential quadratic programming.
- FastGA.
- Covariance matrix adaptation.
- Population control methods for noise management.
- Particle swarm optimization.
Previously, using these algorithms often involved custom-built implementations that make it difficult or impossible to compare results from a wide range of state-of-the-art methods. Now, using Nevergrad, AI developers can easily test many different methods on a particular ML problem and then compare results. Or, they can use well-known benchmarks to evaluate how a new derivative-free optimization method compares with the current state of the art.
The gradient-free optimizations included in Nevergrad are used for a wide variety of ML problems, such as:
- Multimodal problems, such as those that have several minima. (For example, hyperparametrization of deep learning for language modeling.)
- Ill-conditioned problems, which typically arise when trying to optimize several variables with very different dynamics (for example, dropout and learning rate without problem-specific rescaling).
- Separable or rotated problems, including partially rotated problems.
- Partially separable problems, which can be addressed by considering several blocks of variables. Examples include architecture search for deep learning or other forms of design, as well as the parametrization of multitask networks.
- Discrete, continuous, or mixed problems. These can include power systems (because some power plants have tunable continuous outputs and others have continuous or semicontinuous outputs) or tasks with neural networks that require simultaneously choosing the learning rate per layer, the weight decay per layer, and the types of nonlinearity per layer.
- Noisy problems, i.e., problems for which the function can return different results when it is called with the exact same parameter, such as independent episodes in reinforcement learning.
In machine learning, Nevergrad can be used to tune hyperparameters such as learning rate, momentum, weight decay (possibly per layer), dropout, and layer parameters for each part of a deep network, or others. More generally, gradient-free methods are also used in power grid management, aeronautics, lens design, and many other scientific and engineering applications.
The need for gradient-free optimization
In some cases, such as neural networks weight optimization, it is easy to compute a function’s gradient analytically. In other cases, however, estimating the gradient can be impractical — if function f is slow to compute, for example, or if the domains are not continuous. Derivative-free methods provide a solution in these use cases.
One simple gradient-free solution is random search, which consists of randomly sampling a large set of search points, evaluating each of them, and then selecting the best. Random search performs well with many simple cases but not with higher-dimension ones. Grid search, often used in parameter tuning in machine learning, suffers from similar limitations. There are many alternative methods, however. Some come from applied mathematics, like sequential quadratic programming, which updates quadratic approximations of the simulator. Bayesian optimization also builds a model of the objective function, including a model of uncertainties. Evolutionary computation contains a wide body of work on selecting, mutating, and mixing promising variants.

This example shows how an evolutionary algorithm works. Points are sampled in the function space, a population of best points is selected, and then new points are proposed around the existing points to try to improve the current population.
Algorithm benchmarks generated with Nevergrad
We used Nevergrad to implement several benchmarks, in order to show that a particular algorithm will work best in particular cases. These well-known examples correspond to various settings (multimodal or not, noisy or not, discrete or not, ill-conditioned or not) and show how to determine the best optimization algorithm using Nevergrad.
In each benchmark, we use independent experiments for the different x-values. This ensures that consistent rankings between methods, over several x-values, are statistically significant. In addition to the two benchmark examples below, a more comprehensive list is available here, along with instructions on how to rerun them in a simple command line.
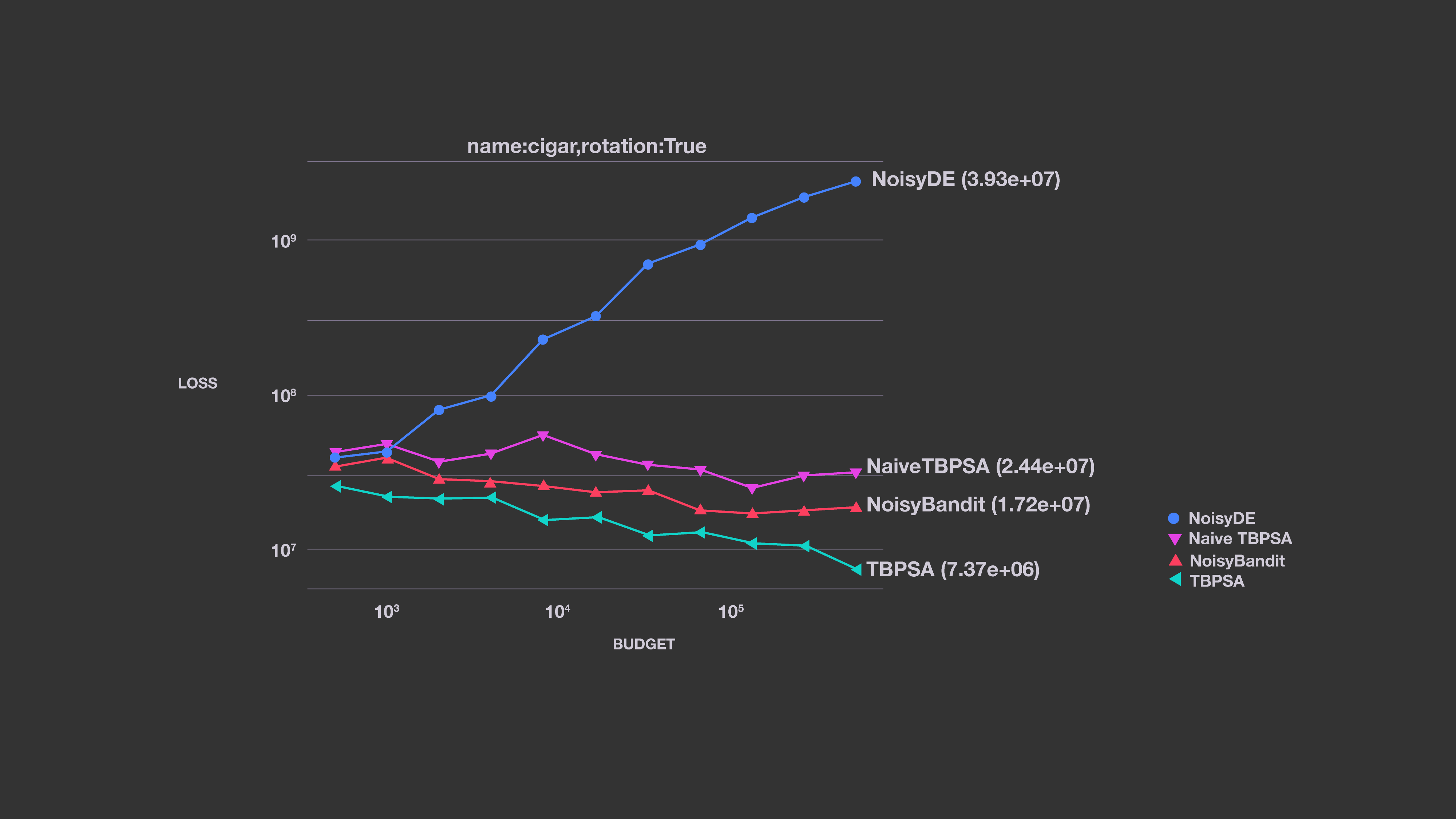
This graph shows an example of noisy optimization.
This example shows how TBPSA, which uses the noise-management principles of pcCMSA-ES, outperforms several alternatives. We compare it here to a limited sample of our algorithms, but it performs very well against many other methods as well.
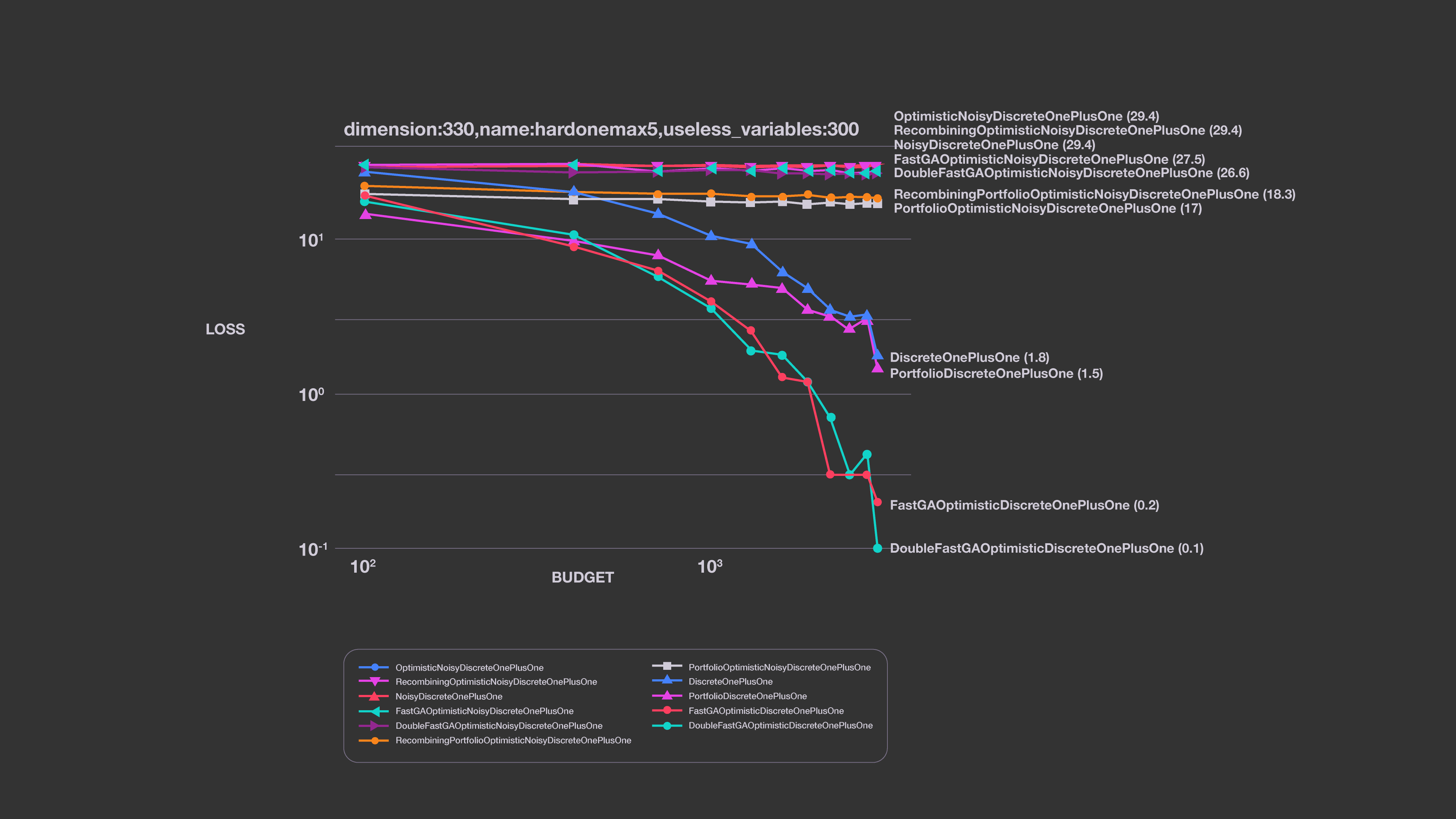
The Nevergrad platform can also work with discrete objective functions, which arise in many ML cases. These include, for example, choosing between a finite set of options (such as activation functions in neural nets) and choosing between types of layers (e.g., deciding whether skip connections are needed at some location in the network).
The existing alternative platforms (Bbob and Cutest) do not contain any discrete benchmarks. Nevergrad can work with discrete domains handled through the softmax function (which converts a discrete problem into a noisy, continuous one) or through discretization of continuous variables.
We note that FastGA performs best in this case. DoubleFastGA corresponds to a mutation rate ranging between 1/dim and (dim-1)/dim, instead of 1/dim and 1/2. This is because the original range corresponds to a binary domain, whereas here we consider arbitrary domains. The simple uniform mixing of mutation rates performs well in several cases.
Expanding the toolkit for researchers and ML scientists
We will continue to add functionality to Nevergrad to help researchers create and benchmark new algorithms. The initial release has basic artificial test function, but we plan on adding more, including functions that represent physical models. On the application side, we’ll continue to make Nevergrad easier to use, as well as explore using it to optimize parameters in PyTorch reinforcement learning models where the gradient is not well-defined. Nevergrad has the potential to help in parameter sweeps for other tasks, as well, such as A/B testing and job scheduling.
We look forward to collaborating with other researchers on additional tools and applications.








