
Today, we are announcing the next steps in Facebook’s efforts to build a hardware ecosystem for machine learning (ML) through partner support of the Glow compiler. We’re pleased to announce that Cadence, Esperanto, Intel, Marvell, and Qualcomm Technologies Inc, a subsidiary of Qualcomm Incorporated, have committed to supporting Glow in future silicon products.
We introduced Glow earlier this year to enable hardware acceleration for ML. As we look to proliferate deep learning frameworks such as PyTorch, we need compilers that provide a variety of optimizations to accelerate inference performance on a range of hardware platforms to support a growing number of artificial intelligence (AI) and ML industry needs.
We created Glow, an open source framework, to be community driven. This approach allows partners to more rapidly design and optimize new silicon products for AI and ML by leveraging community-driven compiler software.
A collaborative effort
Industry collaboration is core to Facebook’s DNA, and we continue to work with partners in the systems community to enable our platform to scale. With billions of people already connected across our family of apps and services, we need infrastructure solutions that support sustainable growth and enable a new class of platform capabilities through our efforts in AI and ML. These technologies require an enormous amount of computational processing, which presents a new set of challenges for how we design these systems and partner with the semiconductor ecosystem.
Over the past seven years, we’ve learned a great deal about how to best collaborate with the hardware community. Our work to help found and drive the Open Compute Project has been instrumental in allowing us to build highly scalable, efficient networking and storage technologies for our data centers. We’ve applied this thinking to how we work with telecom operators and the connectivity ecosystem overall with the Telecom Infra Project, as we work to get more people around the world better connected to the internet. As we look ahead, we now want to take these learnings and apply them to how we work with our silicon partners on AI and ML.
How Glow works
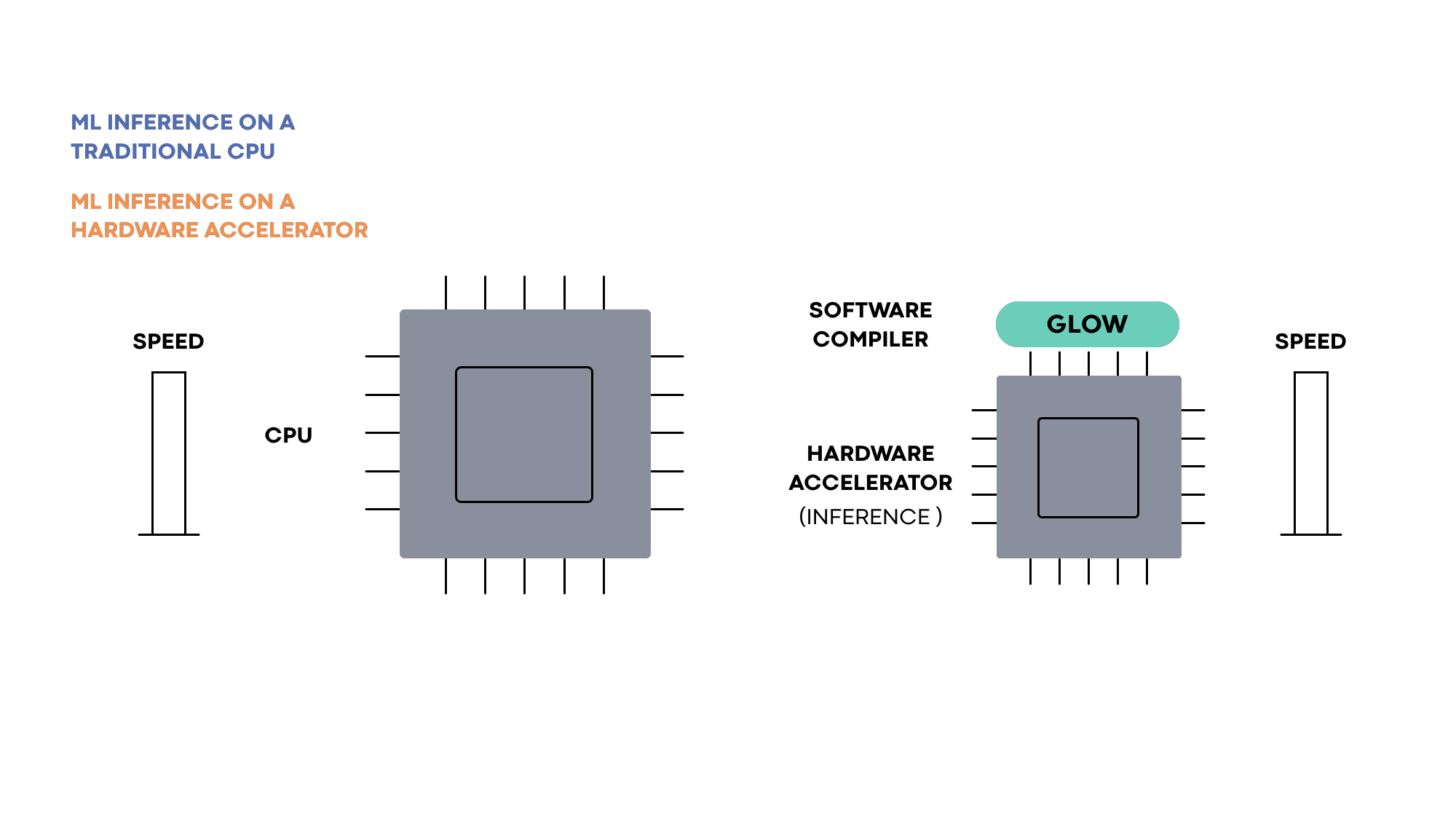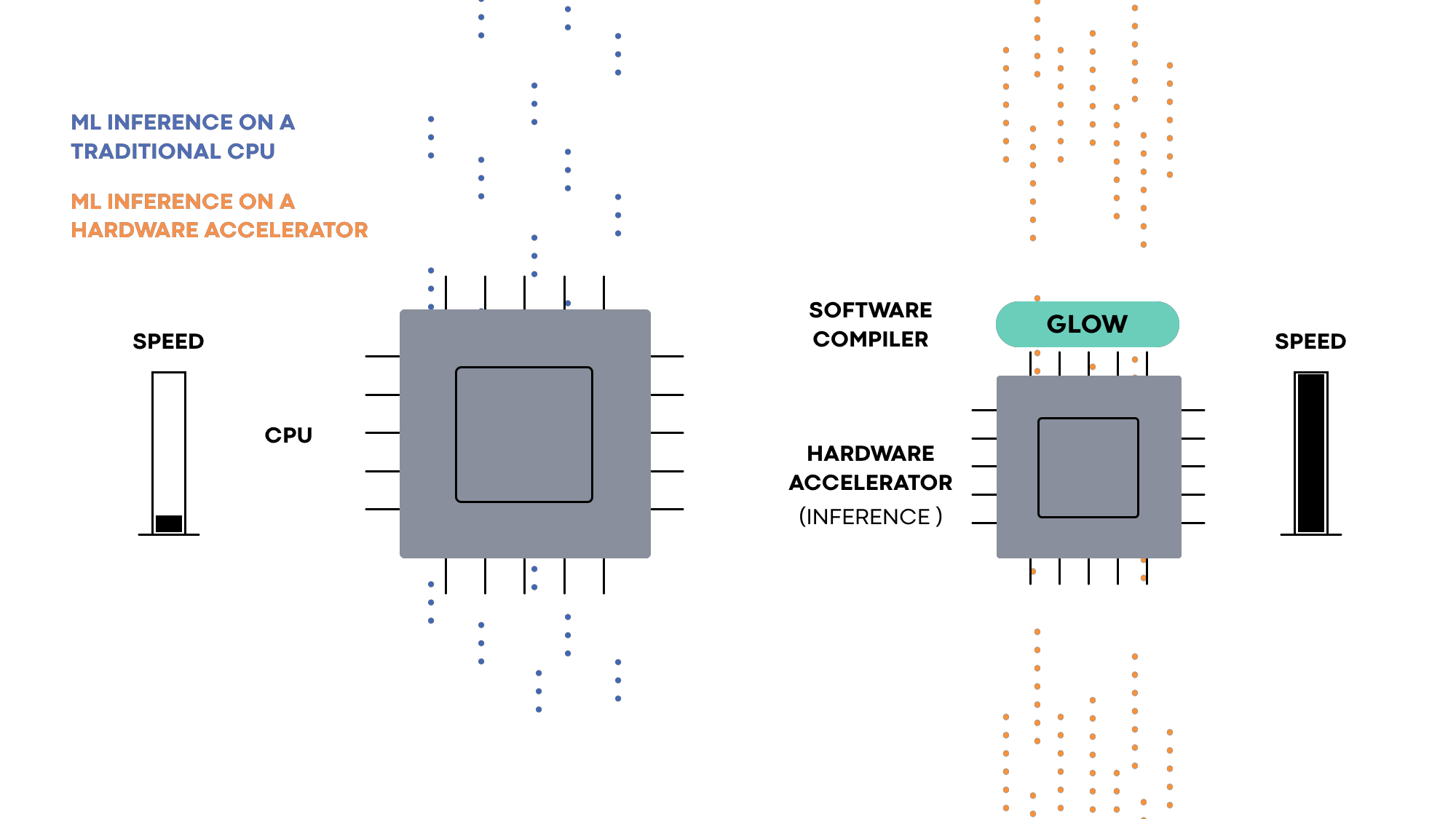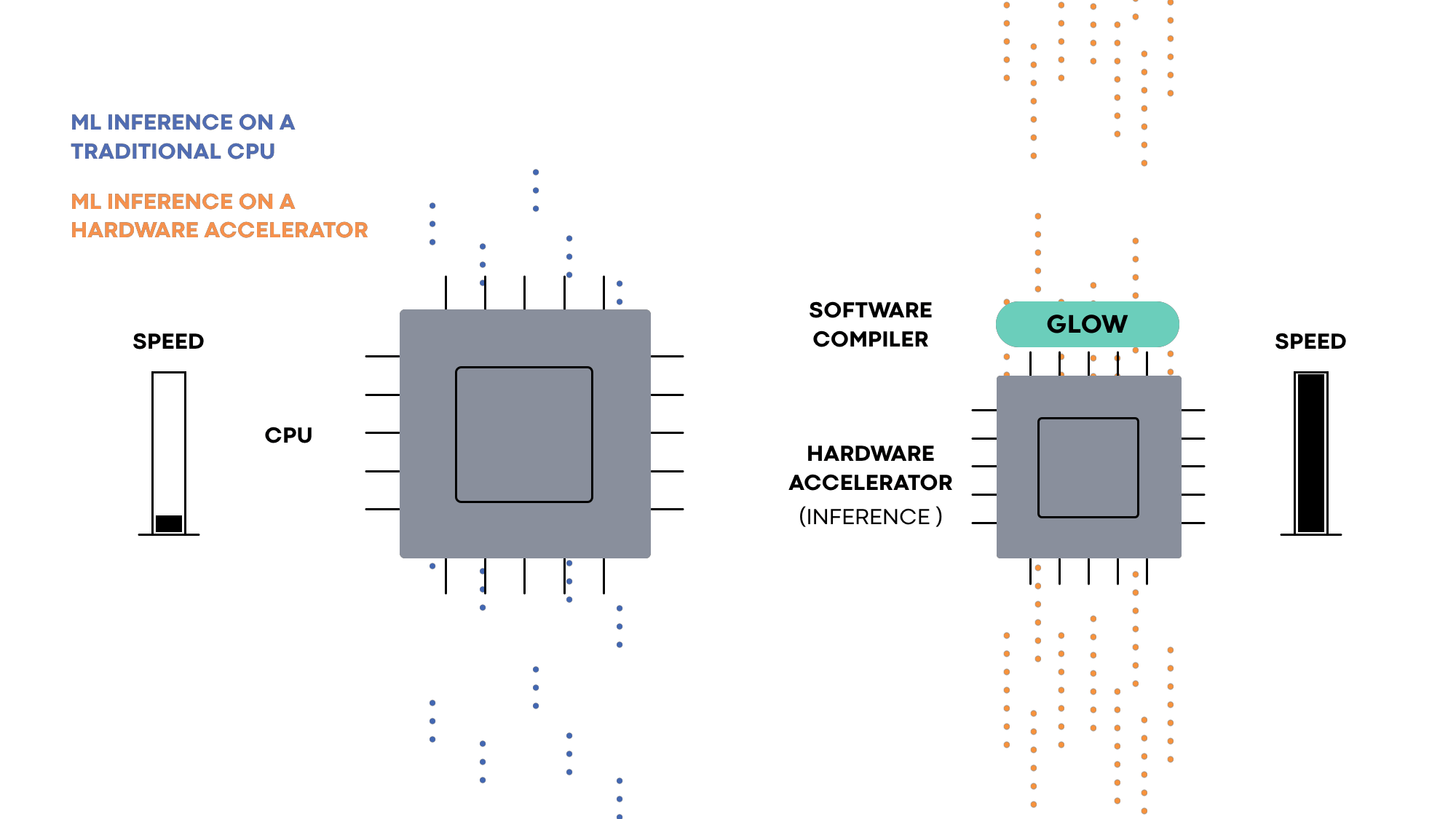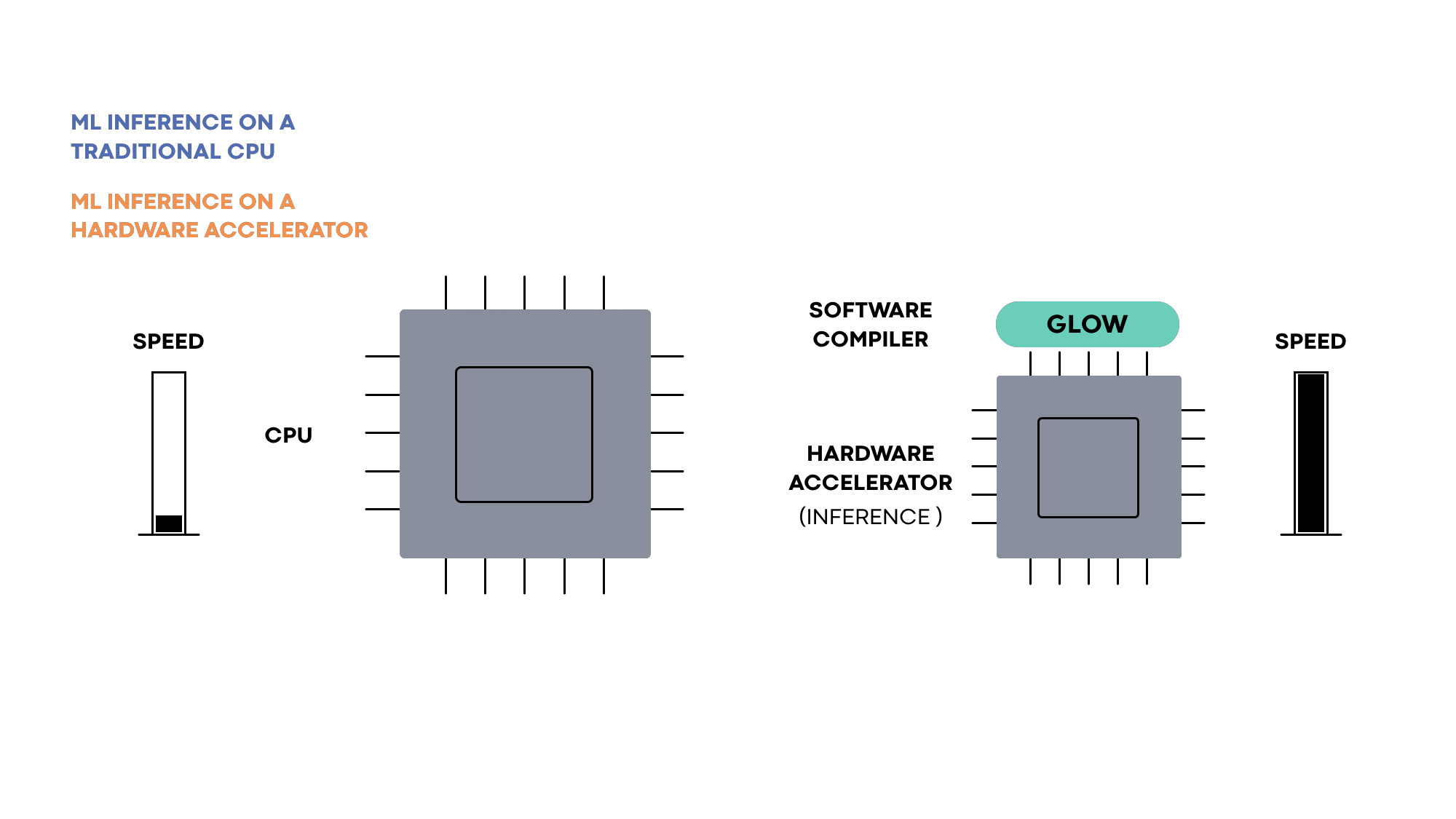
Glow enables the ecosystem of hardware developers and researchers to focus on building next-gen hardware accelerators that can be supported by deep learning frameworks such as PyTorch. It accepts a computation graph from these frameworks and generates highly optimized code for machine learning accelerators.
Hardware accelerators are specialized to solve the task of machine learning execution. They typically contain a large number of execution units, on-chip memory banks, and application-specific circuits that make the execution of ML workloads very efficient. To execute machine learning programs on specialized hardware, compilers are used to orchestrate the different parts and make them work together. Machine learning frameworks such as PyTorch rely on compilers to enable the efficient use of acceleration hardware.
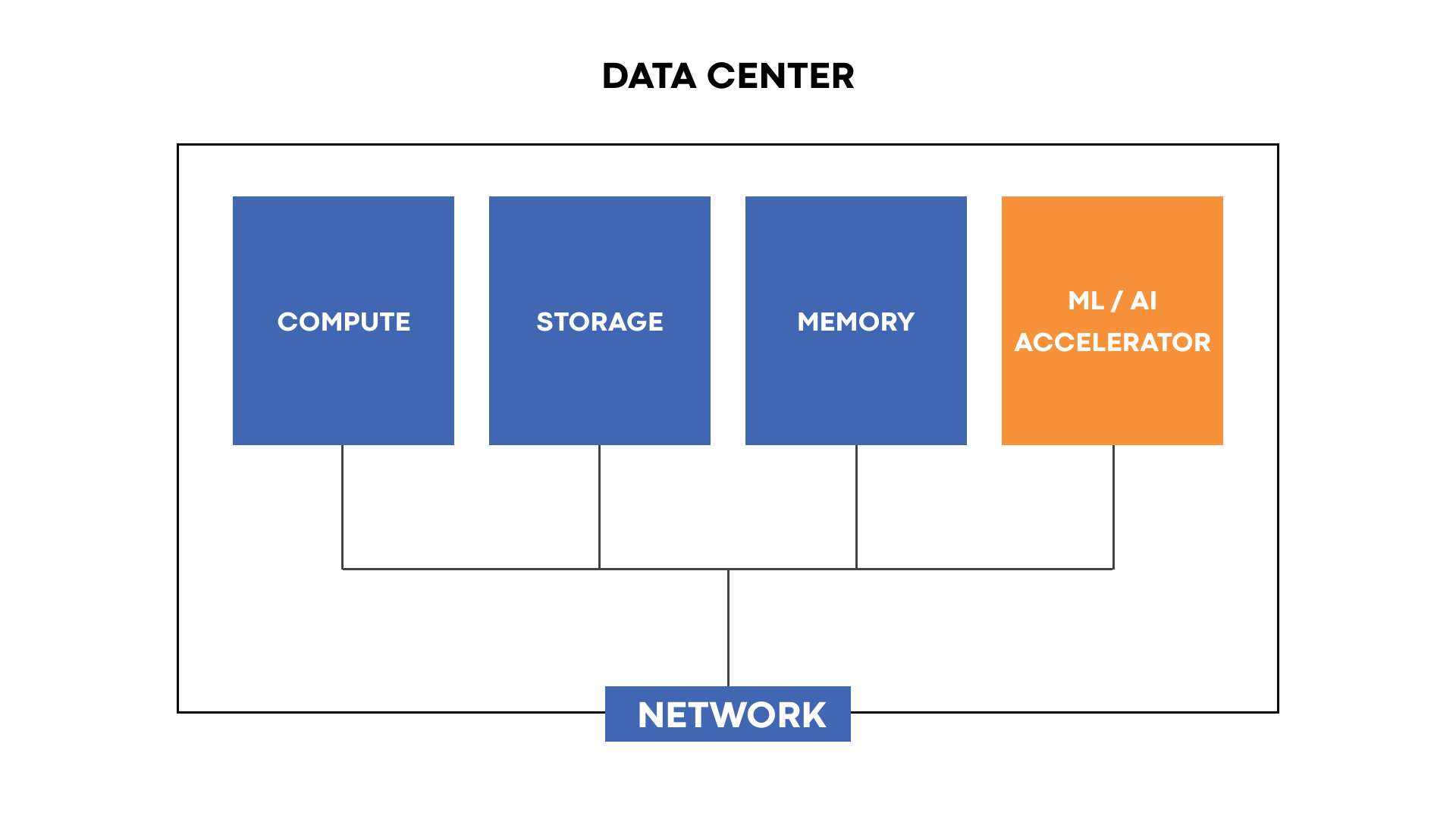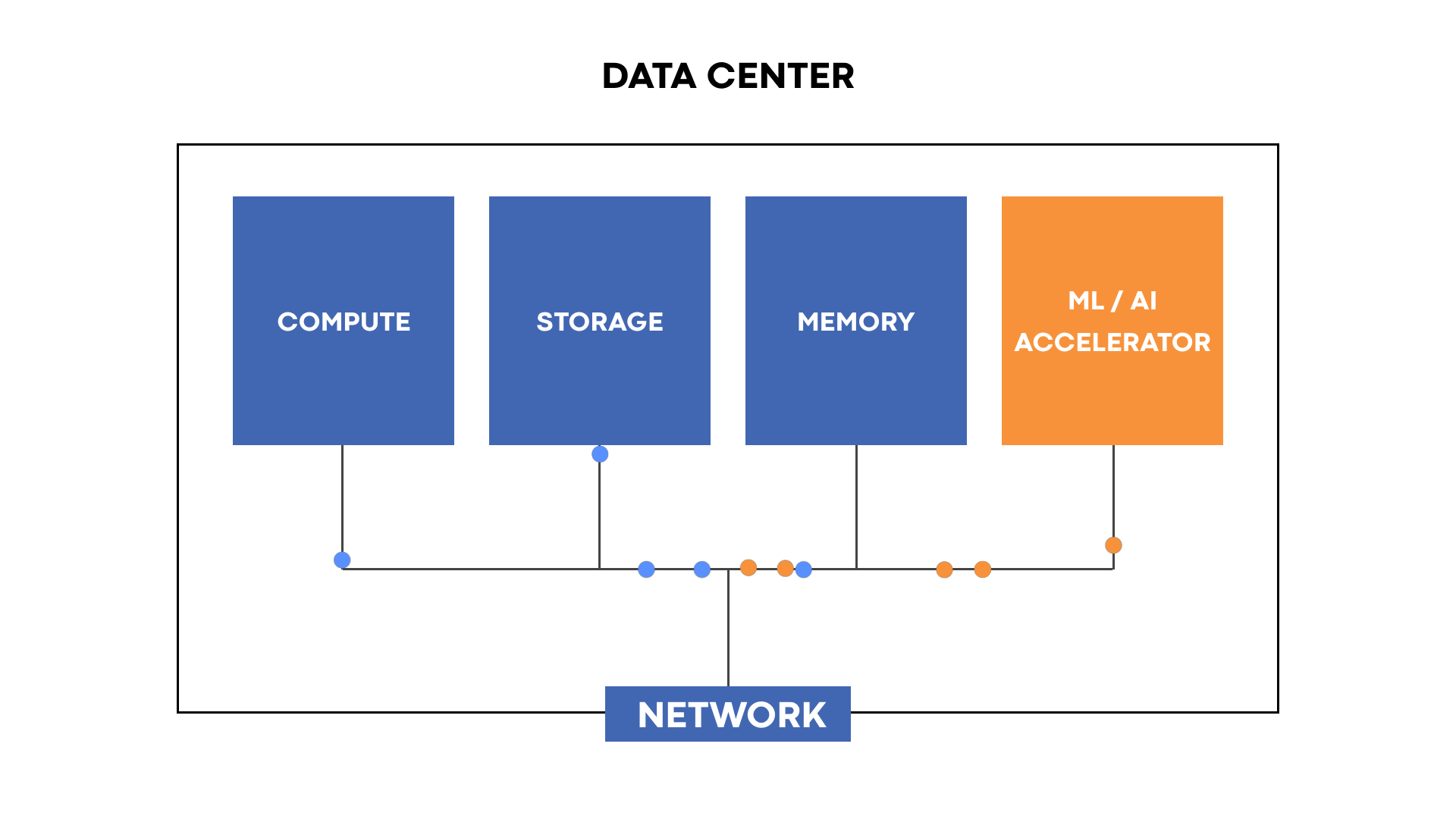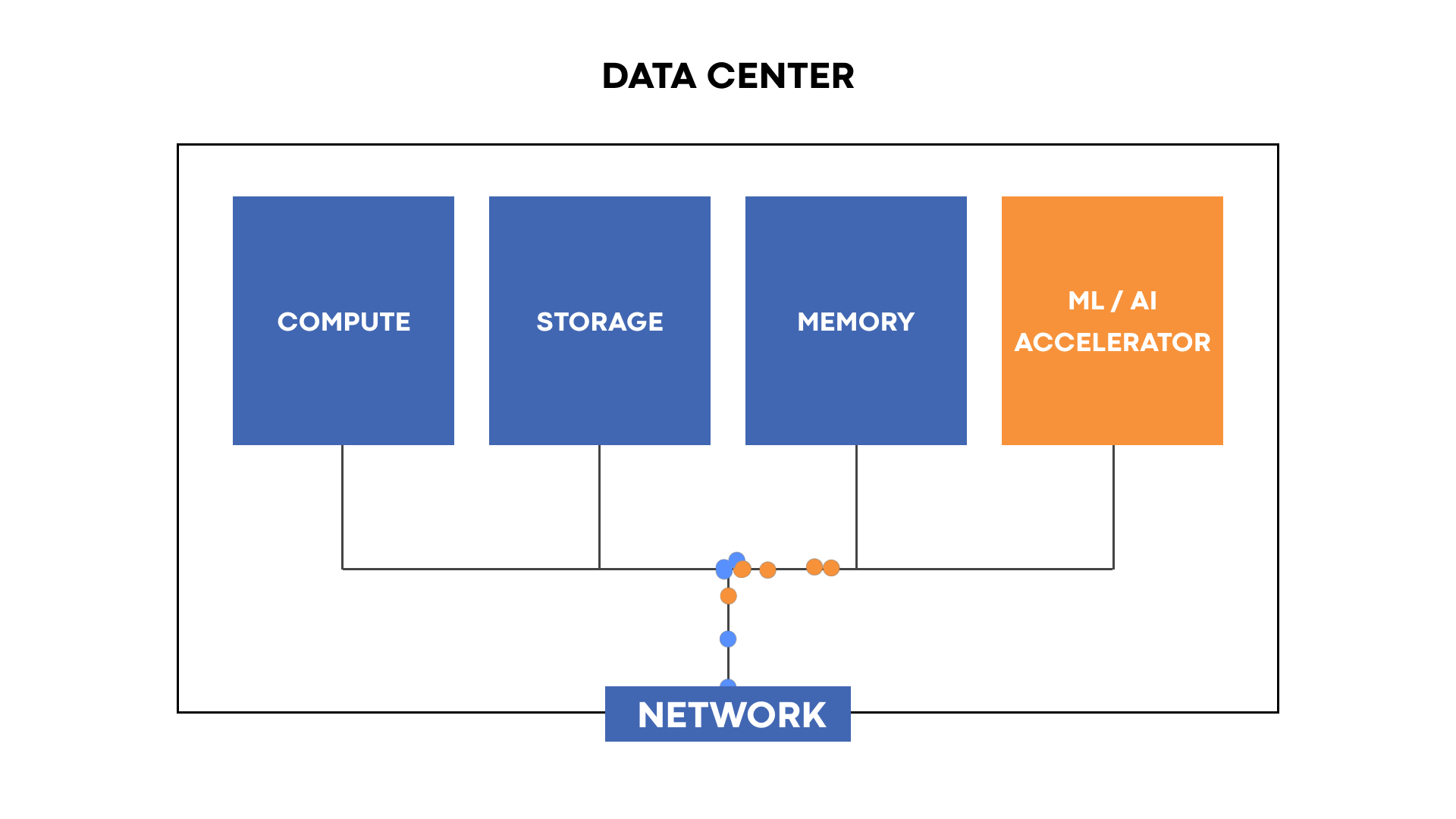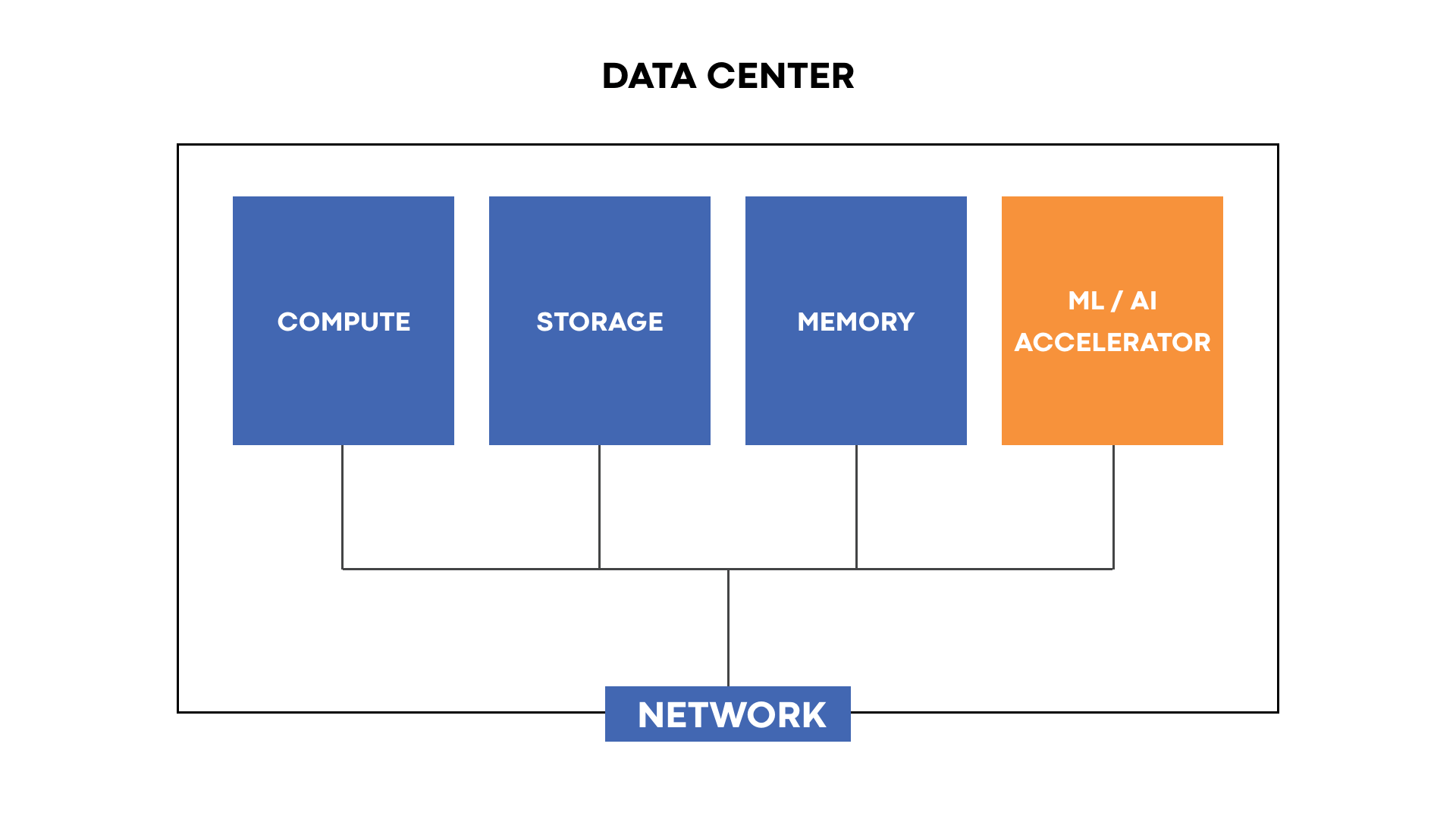
Hardware accelerators for ML are designed to solve a range of distinct problems. Some focus on inference, while others focus on training. Each model has a different memory and processor configuration. Glow is designed to target a wide range of hardware accelerators. The hardware-independent parts of the compiler focus on math-related optimizations that are not tied to a specific hardware model. In addition to the target-independent optimizations, Glow contains a number of utilities and building blocks that can be configured to support multiple hardware targets. For example, the memory allocator of the compiler is used to generate efficient code for a variety of hardware accelerators, each with a different memory configuration. These capabilities include a powerful linear algebra optimizer, an extensive test suite, a CPU-based reference implementation for testing the accuracy of hardware accelerators, as well as the memory allocator, an instruction scheduler, etc.
Hardware partners that use Glow can reduce the time it takes to bring their product to market. Relying on the existing optimizations and capabilities reduces development time, and the extensive test suite improves a hardware provider’s confidence in the accuracy of the compiler and its conformance to the PyTorch specification.
Looking ahead
We’d like to acknowledge the tremendous contributions and support of the LLVM community in advancing ecosystem support and adoption for Glow. We’re excited to continue our partner engagement for Glow as we look to expand our ecosystem to add more new partners in 2018 and beyond.
As the ecosystem for Glow matures and expands, we see the opportunities for hardware-acceleration for AI/ML to extend beyond the data center, with meaningful benefits to mobile device providers and adjacent industries over the long term. We’re excited to work with our hardware ecosystem partners to unlock the next steps in AI/ML innovation through Glow.








