
Part of Facebook’s mission to bring the world closer together is breaking down language barriers and allowing everyone to engage with content in their preferred language. Translating more content in more languages also helps us better detect policy-violating content and expand access to the products and services offered on our platforms. When we factor in the number of languages in use and the volume of content on those platforms, we are serving nearly 6 billion translations per day to our community. Using traditional methods, it could take years to professionally translate a single day’s content. Providing automatic translation at our scale and volume requires the use of artificial intelligence (AI) and, more specifically, neural machine translation (NMT).
Our translation models have improved in terms of quality since we transitioned to neural networks, but until recently, technical challenges kept us from increasing the amount of languages we serve. In 2018, Facebook’s Language and Translation Technologies (LATTE) group set out to change that, and to achieve the goal of “no language left behind.” Our primary challenges included a lack of resources for training (most of these languages do not have a quantity of readily available human translations) and the need to find a way to train systems fast enough to produce usable translations quickly.
Today, we are proud to share the results of those efforts and announce that we have added 24 new languages to our automatic translation services. We are now serving translations for a total of 4,504 language directions (a pair of languages between which we offer translation, e.g., English to Spanish).
The newly supported languages in 2018 are:
- Serbian
- Belarusian
- Marathi
- Sinhalese
- Telugu
- Nepali
- Kannada
- Gujarati
- Punjabi
- Urdu
- Malayalam
- Cambodian
- Pashto
- Mongolian
- Hausa
- Zulu
- Xhosa
- Amharic
- Somali
- Swahili
- Romanized Arabic
- Romanized Bengali
- Romanized Hindi
- Romanized Urdu
Early progress
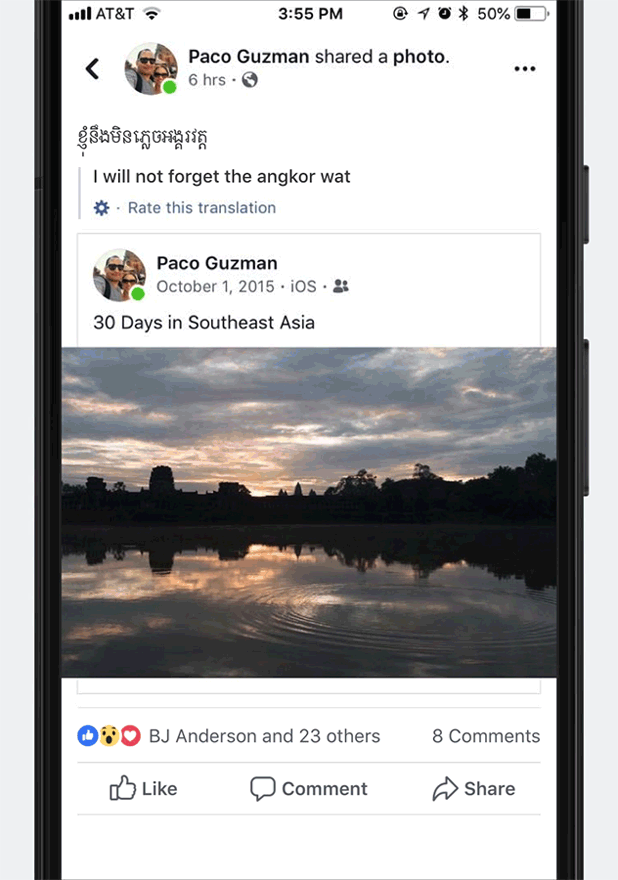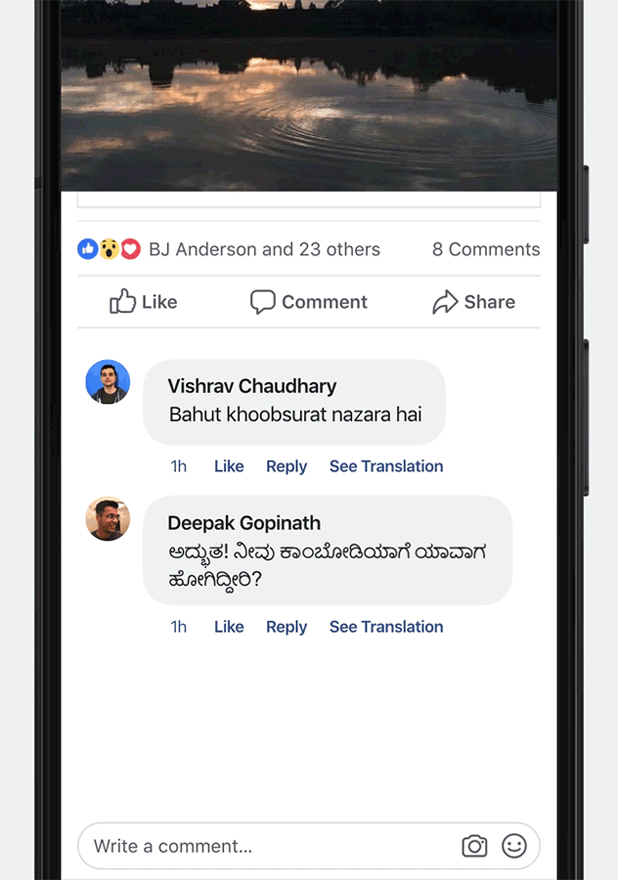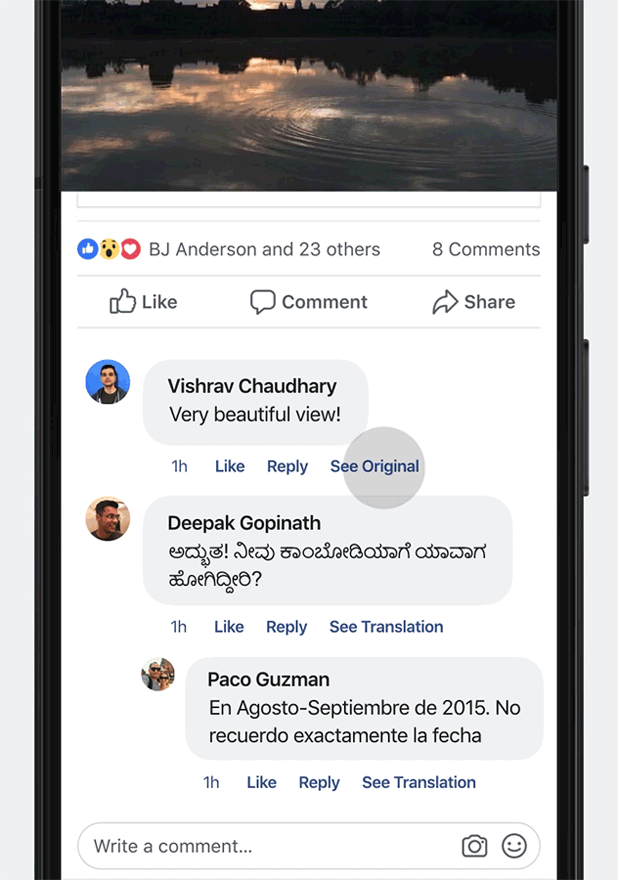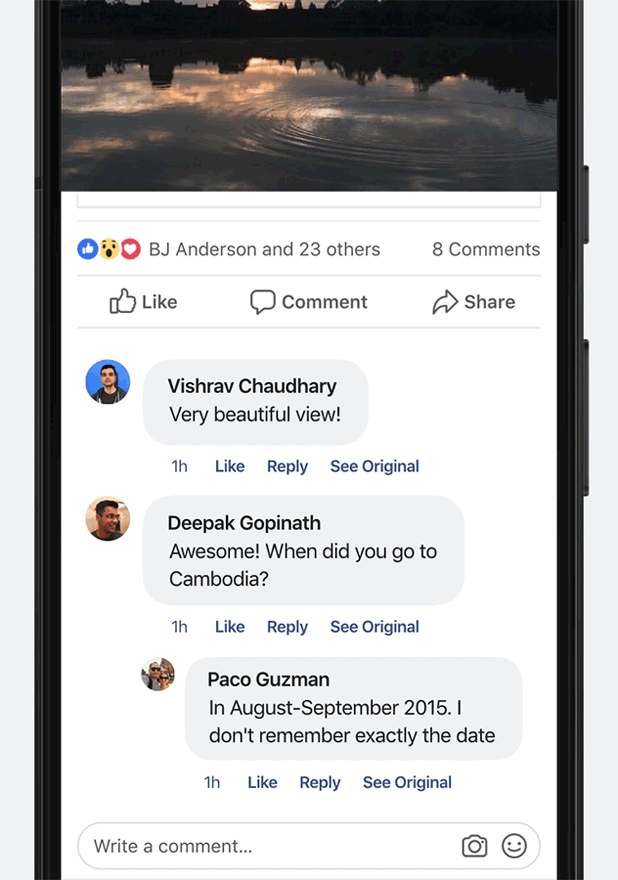
Translation systems for many of these languages are at an early stage, and the translations they produce are still a long way from professional quality. Nonetheless, the systems produce useful translations that convey the gist of the original meaning, and they give us a way to improve quality iteratively.

Examples of translations at each stage along the quality scale.
Low-resource translation experiments
Most of the translation systems require parallel data, or paired translations to be used as training data. Large collections of translations are available on the web, originating mainly from international organizations such as the United Nations, the European Union, and the Canadian Parliament. Unfortunately, these readily available parallel corpora exist for only a handful of languages.
The main challenge we faced in building translation systems for new languages consisted of achieving a level of translation quality that yields usable translations, in the absence of large quantities of parallel corpora. The lack of data is also challenging for NMT, which uses models with a large number of parameters and is more sensitive to the quality of data. To better understand what helps under low-resource settings, we conducted several experiments. We used BLEU scores (a metric that measures the degree of overlap between the generated translation and a professional reference) to measure translation quality. We trained NMT models using the open source PyTorch Translate framework, converted them to the ONNX format, and used them in the production Caffe2 environment. Overall, we experimented with three main strategies:
1) Increasing labeled in-domain data
Facebook posts and messages are very different from other types of text: They are generally shorter, less formal, and contain abbreviations, slang, and typos. To learn how to translate these, we need to provide the algorithms with good examples of social post translations. To this end, we manually label (professionally translate) public posts. To scale up to all the languages we covered, we automated several of our processes. For example, we automated the selection and preparation of these posts. Then we ranked them to maximize coverage (i.e., to ensure that we are getting translations we don’t already have). Then we automatically sent them for professional translation in weekly batches to different translation providers. In total, we manually labeled millions of words in 25 languages.
To measure the effectiveness of in-domain training data, we trained systems with and without it and measured the BLEU scores with and without. On average, we obtained +7.2 BLEU for each of the 15 languages in the experiment (the results vary from direction to direction). On average, we see +1.5 BLEU increase for every additional 10K sentence pairs of seed data.
2) Exploring semisupervised NMT
In addition to generating more in-domain data, we explored semisupervised and data augmentation methods to generate additional training data. These methods rely on lower-accuracy models that are used to generate artificial training data. For example, to train an Amharic-English system, we can train a basic translation system for English-Amharic, and use it to translate large quantities of monolingual English data into Amharic. Then, we use the artificially generated English-Amharic data as an additional source of training data for Amharic-English translations. This is known as back-translation, and it helps in 88 percent of cases, with an overall average of +2.5 BLEU.
Similarly, we explored using monolingual data in a technique known as copy-target. Here, we make a copy of portions of our training data, and we use the target side of the corpora to replace the source side. For an English-Hausa system, this means that we would take the English-Hausa data and replace the English portion of the data with Hausa (e.g., Hausa-Hausa data), and then use this artificial corpus as an additional source of training data. In our experiments, in 88 percent of cases this resulted in an average improvement of +2.7 BLEU.
The intuition behind these two techniques is that they help low-resource models do better training of their decoder (the component that produces the translation) and produce more fluent translations. However, in this low-resource setting, these two techniques have minor complementary effects. Thus, adding back-translation on top of copy-target yields only moderate gains (+0.1 BLEU).
Another technique we used was to build a translation detector that can tell when two sentences in different languages are translations of each other. Then, we can use this detector to mine translations from multilingual webpages. For example, we can look at Wikipedia pages about Facebook in English and Cambodian (Khmer) and automatically deduce that មូលដ្ឋាន-ស្នាក់ការកណ្ដាល is the translation for “headquarters.” We used this translation detector over CommonCrawl to mine for translation pairs in several languages. The data mined from the CommonCrawl as training helped in 70 percent of the experiments (an average gain of +0.4 BLEU).
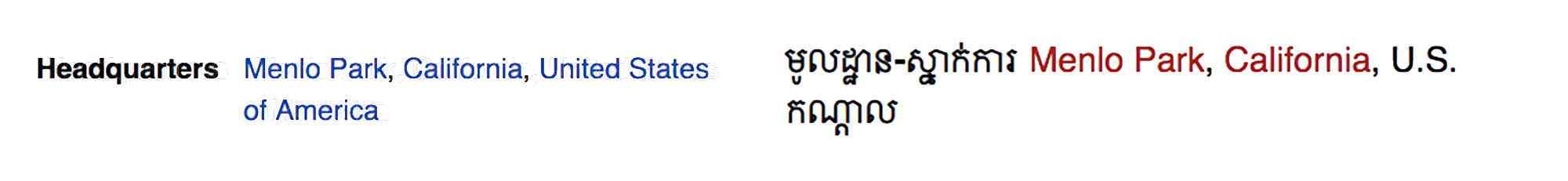
One caveat of using semisupervised methods is that they can introduce noise when the data they generate is not accurate. That is especially harmful to NMT. This was evident in our results where we observed a clear distinction between the value provided by human-generated translations vs. copy-target vs. back-translation vs. mined data. Another side effect of semisupervised methods is that they generate large quantities of data, much of which is out-of-domain. That is, these techniques produce approximate translations that are unlike how people write on Facebook. When used for training, these techniques can introduce bias, and make the resulting translations less like social media posts. Therefore, we also introduced in-domain data up-sampling. That is, we took the portions of our data that are social media posts (in-domain), and made several copies so that they would be well represented in our overall training data. This helped generate translations that are higher quality and more in line with how people write on Facebook. This technique gave an additional +0.4 BLEU on top of copy-target + back-translation and resulted in improvements on 100 percent of our experiments.
3) Utilizing multilingual modeling
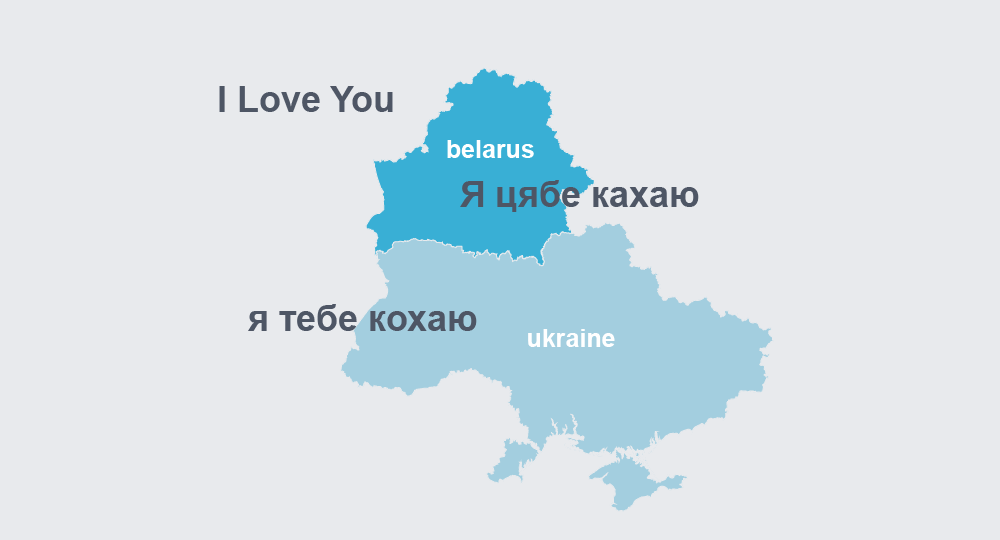
One of the most effective ways we found to improve the quality of a translation system for a specific dialect direction was to combine it with other related directions. For example, to improve translations from Belarusian to English, we leveraged the relationship between Belarusian and Ukrainian and built a multilingual system. In total, we tested seven different translation systems that had multilingual combinations, each of which combined a total of two to four source languages into a single system (e.g., Belarusian to Ukrainian and Ukranian to English). For languages with different scripts, we applied ICU (International Components for Unicode) transliteration to the source side so that we could share vocabularies between all source languages in the multilingual system.
The multilingual systems we experimented with were able to leverage similarities in dialects from the same language families. Multilingual systems beat bilingual baselines by +4.6 BLEU on average, improving seven out of 10 of the directions we experimented with. Note that out of the 15 directions we tested for the purpose of this experiment report, five were not suitable for our multilingual setup and were tested only in the bilingual experiments above.
What comes next?
We continue to move toward our goal of “no language left behind.” That means improving the quality of translations in all languages, moving beyond just useful and toward highly accurate, fluent, and more human-sounding translations. In the longer term, it also means expanding our supported directions to cover all languages used on Facebook. This will require a focus on improving translations for low-resource languages.
We are already investing in longer-term efforts to improve translation in low-resource settings through research on unsupervised translations and faster training, as well as collaboration with the academic community. We will continue to work with the recipients of the Facebook grants on low-resource NMT to keep pushing the state of the art in this area.








