We want people to experience our products in their preferred language and to connect globally with others. To that end, we use neural machine translation (NMT) to automatically translate text in posts and comments. Our previous work on this has been open-sourced in fairseq, a sequence-to-sequence learning library that’s available for everyone to train models for NMT, summarization, or other text-generation tasks.
As NMT models become increasingly successful at learning from large-scale monolingual data (data that is available only in a single language), faster training becomes more important. To scale to such settings, we had to find a way to significantly reduce training time. Until very recently, the training of this type of NMT model required several weeks on a single machine, which is too slow for fast experimentation and deployment.
Thanks to several changes to our precision and training setup, we were able to train a strong NMT model in just 32 minutes, down from 24 hours — or 45x faster. In a subsequent work, we demonstrate how this new, substantially faster training setup allows us to train much more accurate models using monolingual text.
Speeding up training
We first worked on reducing the training time of our model from nearly 24 hours to under 5 hours on a single NVIDIA DGX-1 machine with 8 Volta GPUs. Neural networks contain millions of parameters that are adjusted during training. These parameters are usually stored in 32-bit floating point precision. As a first step, we switched training from 32-bit to 16-bit precision, which reduces our GPU memory footprint and enables us to use the heavily optimized Tensor Cores provided by NVIDIA’s latest Volta GPU architecture. Training with reduced precision (16-bit) floating point can sometimes result in diminished model quality due to floating point “overflow.” In our work, we implemented a known procedure for automatically monitoring and guarding against overflow, and reduced training to 8.25 hours, down from nearly 24 hours, a 2.9x speed increase with no loss in model quality.
Next, we reduced the communication between GPUs by delaying model updates through so-called cumulative updates. We train our models synchronously so that each GPU maintains a full, identical copy of the model but processes different parts of the training data. Processing entails back-propagation, which is split into a forward pass and a backward pass (forward/backward) over the network to compute the required statistics to train the model. After processing each mini-batch, the GPUs synchronously communicate their results (the gradients) to each other. This causes potential inefficiencies: First, there is the time overhead in sending data between GPUs; second, faster workers have to wait for slower workers, so-called stragglers, before training can continue.
The latter is a particular challenge for models involving text, where different sentence lengths make the problem more severe than in computer vision, where training images typically have the same size. Our solution to both problems is to delay the synchronization point by having each worker process and accumulate results from several mini-batches before communicating with other workers. This reduces training to 7.5 hours with no loss in model quality.
Cumulative updates also increase the effective batch size, or the amount of data used at each step of training. In our setting, the batch size increases by a factor of 16. This enables us to double the learning rate, which leads to a training time of 5.2 hours, or a speedup of 4.6x over the original system.
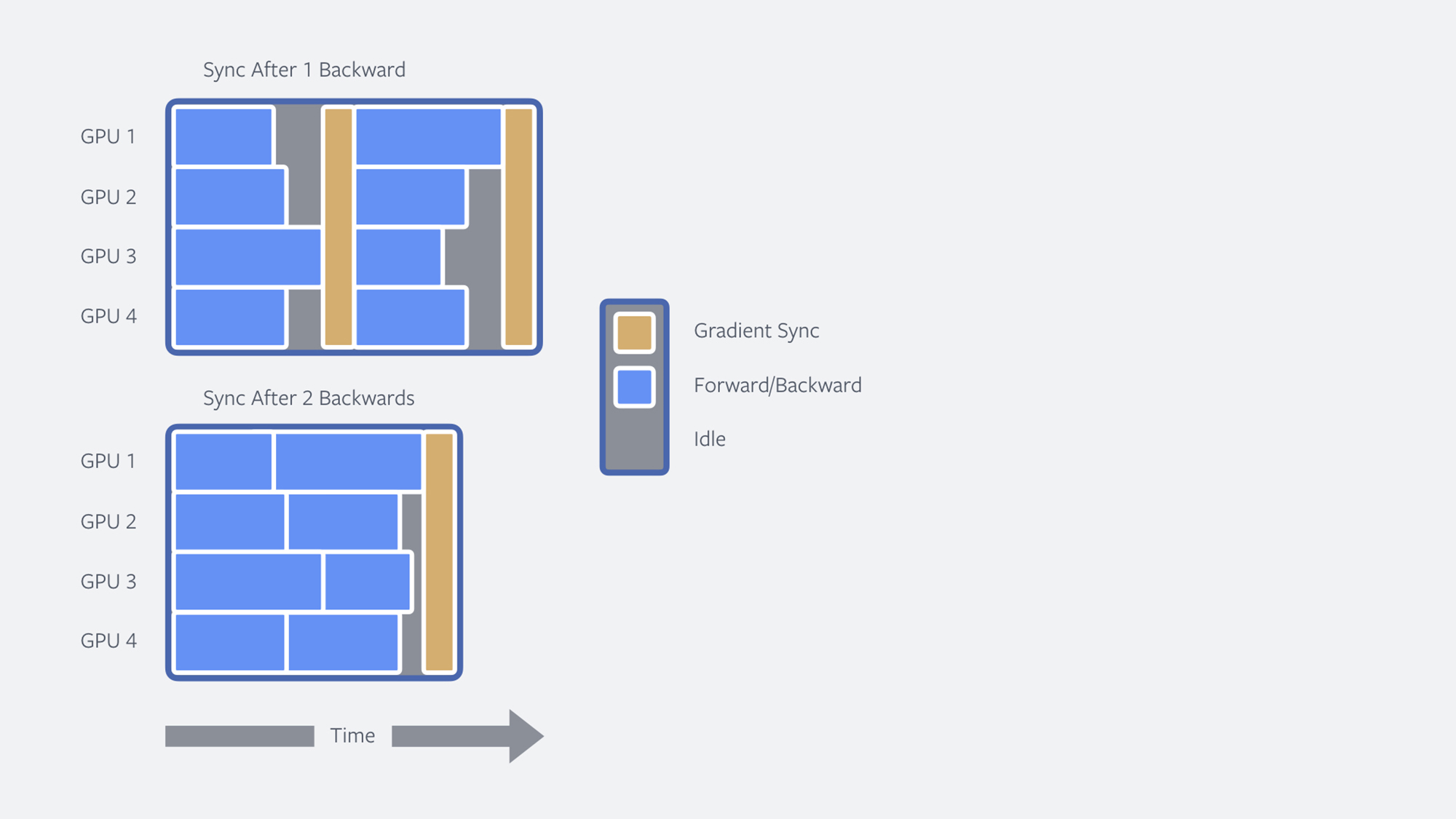
Figure: Accumulating gradients over multiple forward/backward steps speeds up training by (i) reducing communication between workers, and (ii) saving idle time by reducing variance in workload between GPUs.
Finally, we leveraged the extra GPU memory freed up by our earlier switch to 16-bit floating point to further increase the batch size per worker. By increasing the size of the mini-batches processed by each worker from 3.5K words to 5K words, we can reduce overall training time to just 4.9 hours, a 4.9x speedup over the original system.
Scaling out
Our optimizations for training on a single machine are also applicable when parallelizing training across multiple machines (aka distributed training). When we scaled training from a single DGX-1 machine to 16 machines (i.e., 128 GPUs), we found that we can train the same model in just 37 minutes — a 38.6x speedup compared with the original single machine setup.
When training across multiple machines, another optimization is to overlap GPU communication and the backward pass. After the backward pass, we have all the information to communicate with the other workers. Typically, backward and communication are performed sequentially, but we can save time by overlapping them when possible. In particular, we can begin synchronizing gradients across workers as soon as the backward step finishes for a subset of the neural network. GPU communication then overlaps with the backward pass. This reduces training time even further, by 14 percent, and brings the total training time down from nearly 24 hours to just 32 minutes, a total speedup of 44.7x.
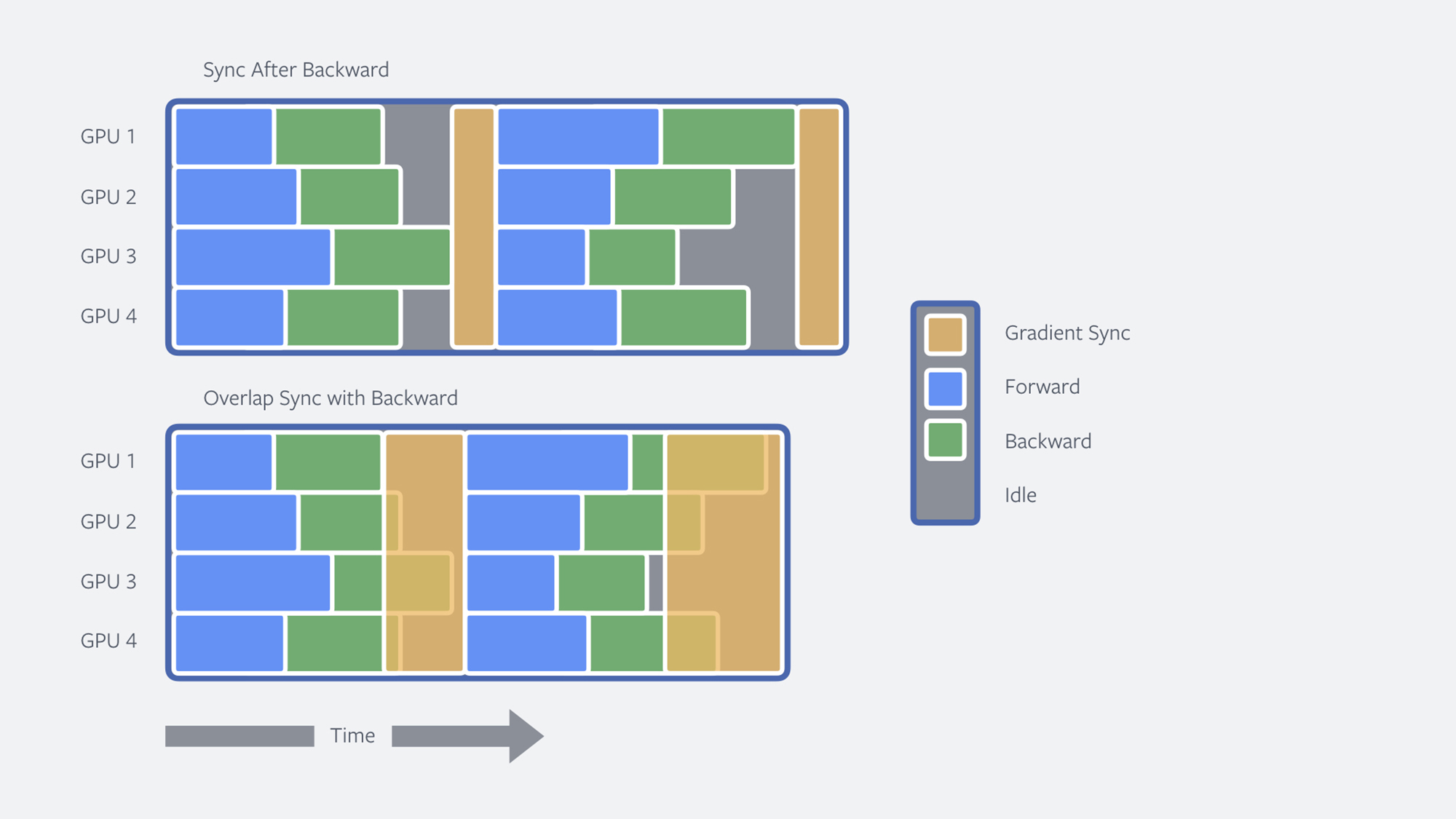
Figure: Illustration of how the backward pass in back-propagation can be overlapped with gradient synchronization to improve training speed.
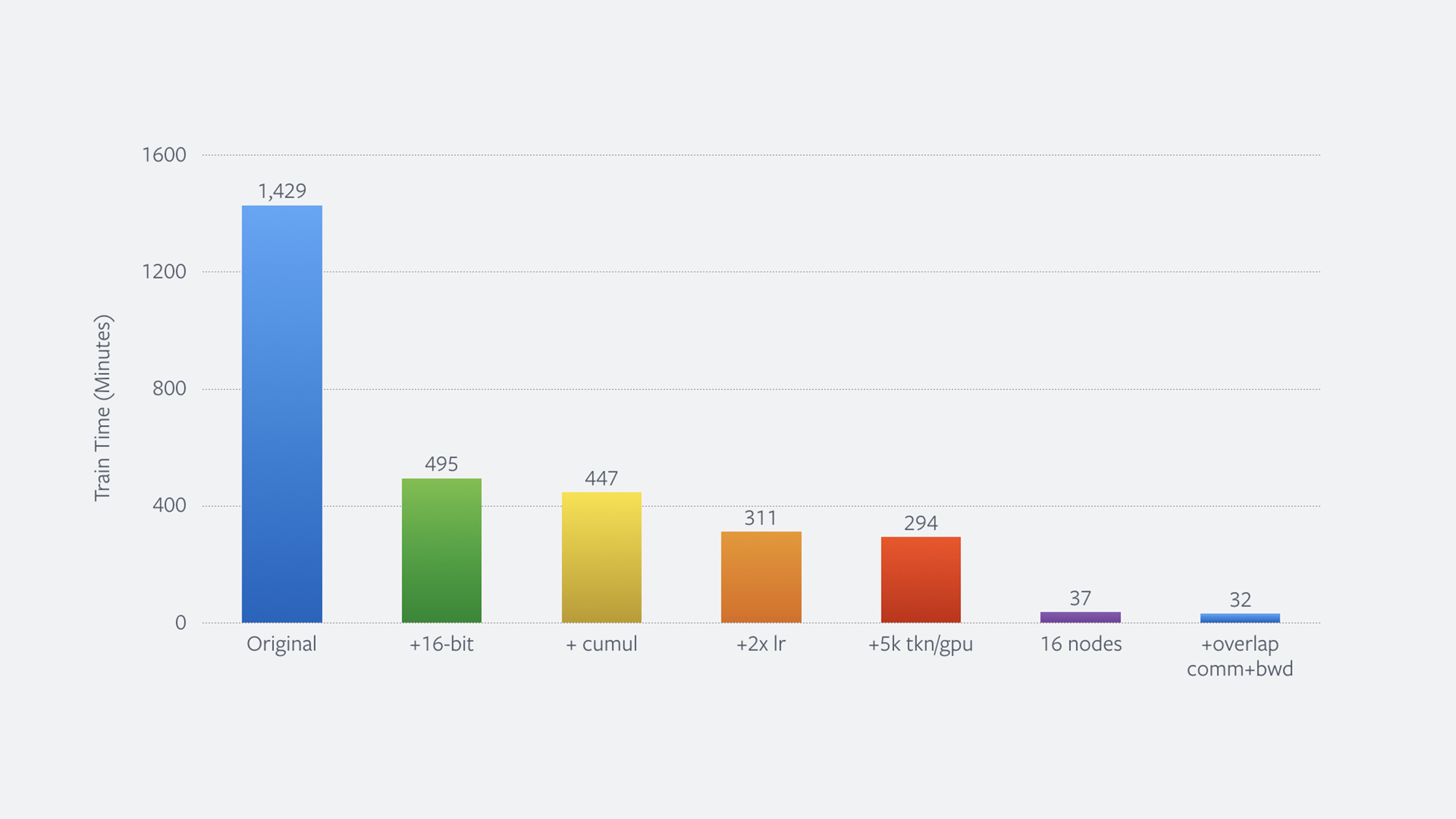
Figure: Total reduction in training time in minutes resulting from each improvement.
Training on (much more) untranslated data
Speeding things up enables us to train models on much larger data sets. Typically, training NMT models requires text that has been paired with reference translations, known as bilingual data. Unfortunately, bilingual data is very limited compared with the vast amount of monolingual data available on the web and elsewhere. In a second paper, we show how we can improve these models with text that is available in only the language we would like to translate to, and that using a vast amount of this data can lead to very large accuracy improvements.
One of the most effective techniques to improve NMT with monolingual data is back-translation. If our goal is to train an English-to-German translation model, then we first train a model for German to English and use it to translate all the monolingual German data. We then simply train the final English-to-German model on both the existing and new data. Our paper shows that it is important how the data is translated and that deliberately not always choosing the best translation, through sampling, is very beneficial.
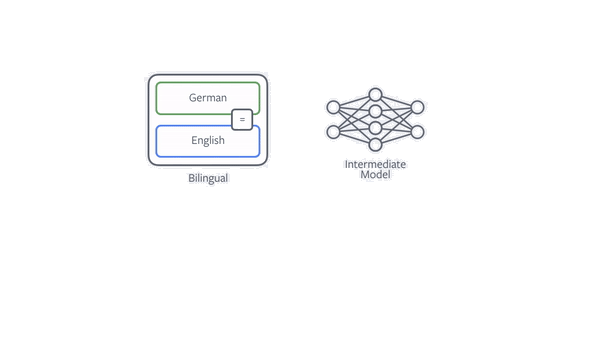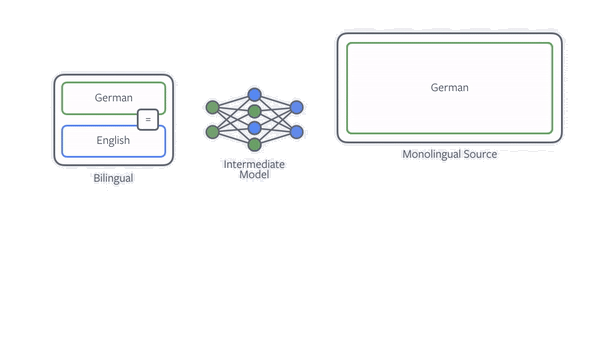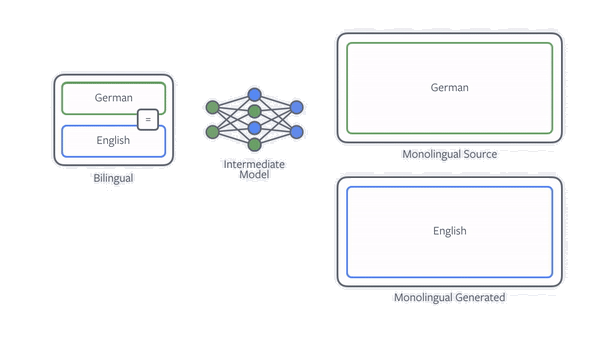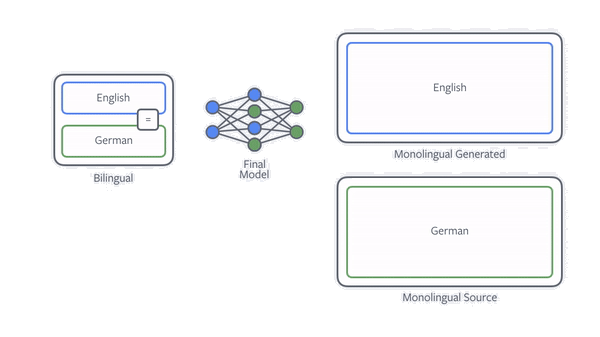
Figure: Animation illustrating back-translation.
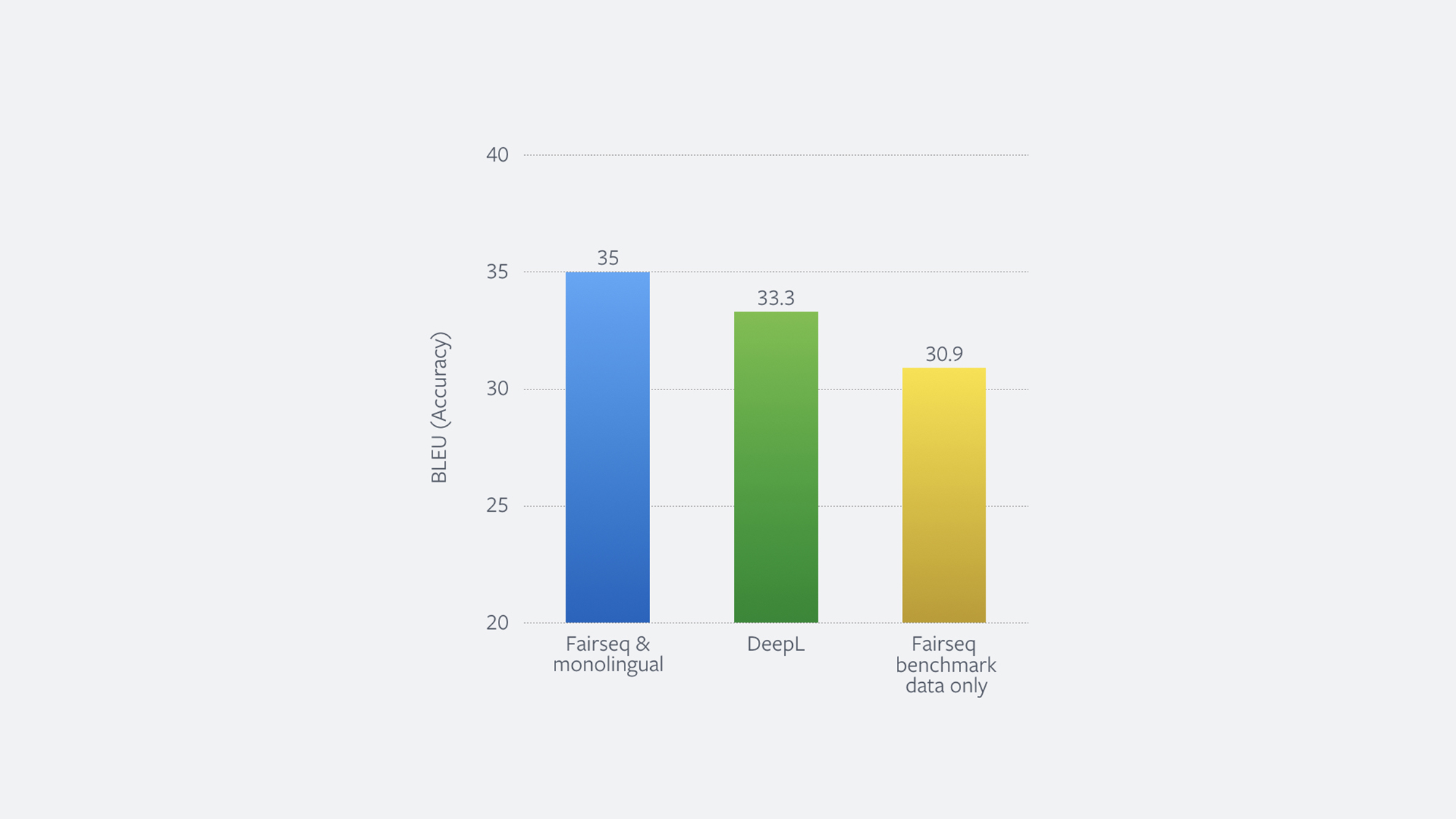
If we add 226 million back-translated sentences to the existing training data of 5 million sentences, then we can dramatically improve translation quality. The graph below shows the accuracy of this system on the test set of the standard WMT’14 English-German benchmark on the left (fairseq & monolingual data). This system can be trained in 22.5 hours on 16 DGX-1 machines. It also shows the accuracy of DeepL, a specialized translation service that relies on high-quality human translations, which previously reported the best performance on this benchmark.
Fast translation
We also improved the speed with which fairseq can translate once a model has been trained. In particular, we implemented clever caching, or removing finished sentences from the computation and batching by the number of words instead of sentences. This improved the speed by nearly 60 percent. The figure below shows a comparison with other popular tool kits. Simply changing from Float 32 to Float 16 improved speed by 40 percent.
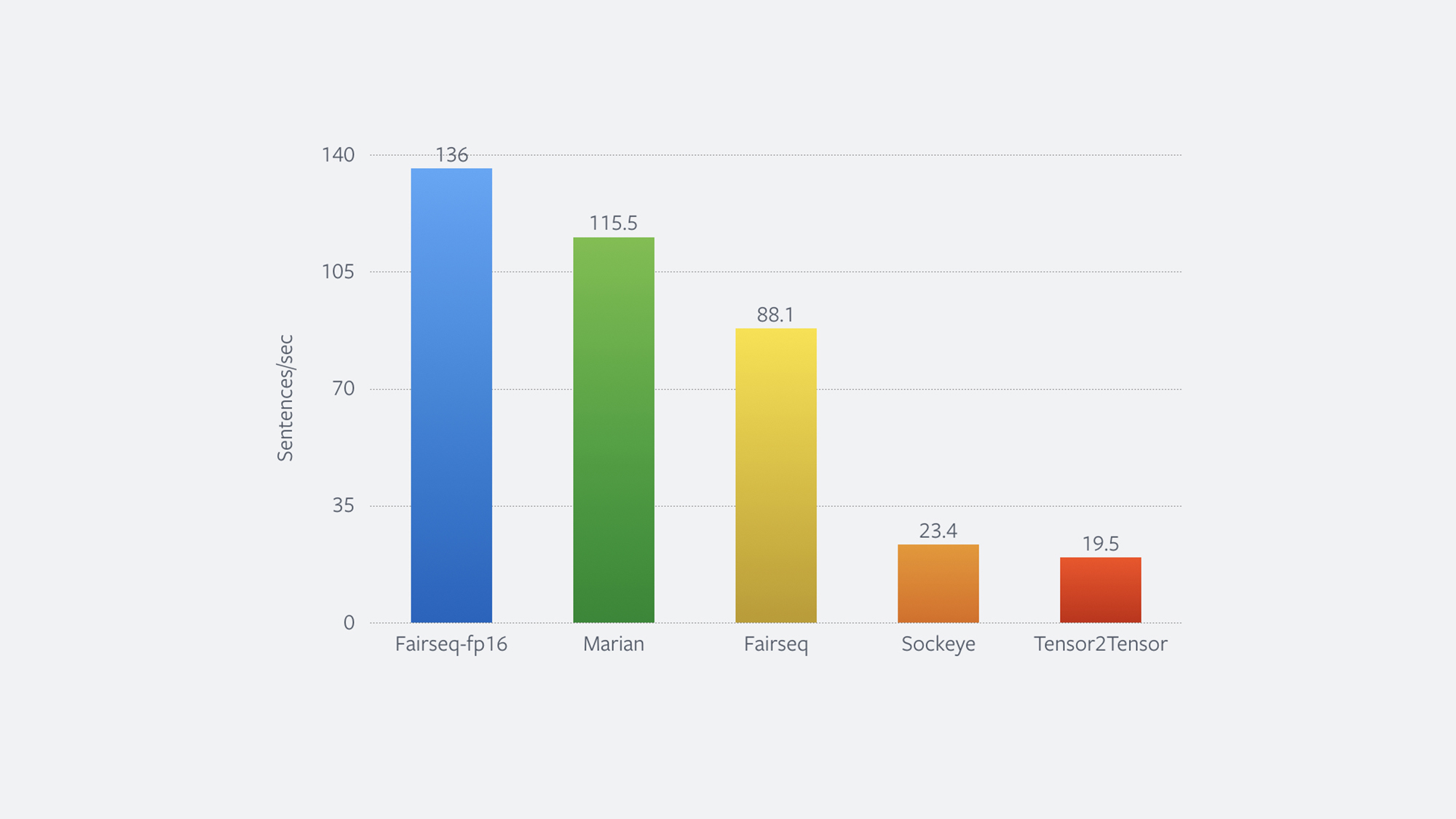
Figure: Translation speed measured on a V100 GPU on the test set of the standard WMT’14 English-German benchmark using a big Transformer model.
What’s ahead
Expanding and improving automatic translation continues to be a focus for us. To grow that research as quickly as possible, we have shared the code for distributed training, and it is available as part of our fairseq open source project so that other researchers can easily train NMT models faster as well. Enabling distributed training requires only a few changes to our training commands.
We are excited about the future discoveries that faster training will enable. Drastically reduced training time accelerates the experimental turnaround, which will make it easier to do research in better NMT models. We are also very excited about the potential of using unlabeled data for problems other than translation, such as question-answering or summarization.








