
This week we’re publishing a series of posts looking back at the technologies and advancements Facebook engineers introduced in 2017. Read our previous posts from this week about data centers, connectivity, and building immersive experiences.
Facebook engineers write, edit, test, and ship thousands of code changes every day. In 2017, we made several optimizations across this workflow that have helped minimize the amount of time engineers spent waiting on machines, even as the number of engineers and amount of code continues to scale. For Android engineers in particular, we reduced time waiting on machines by 79%.
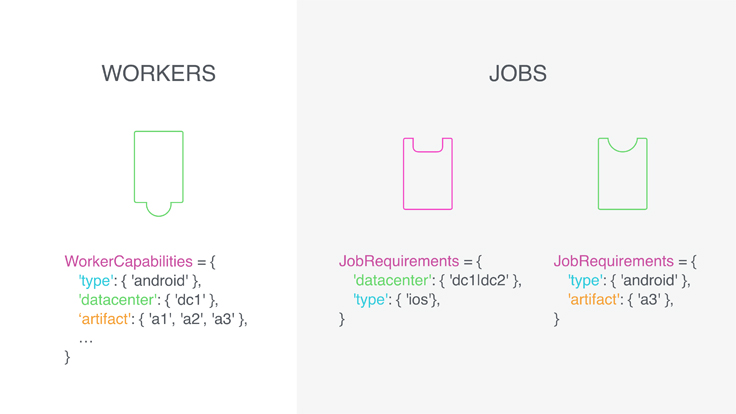
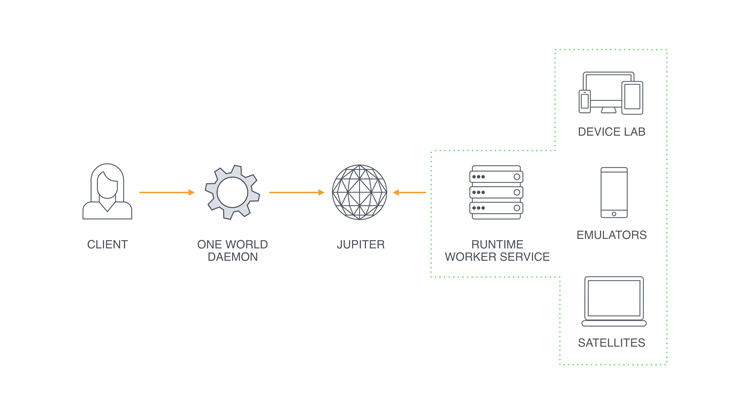
The development cycle relies on a variety of backend services to handle jobs like installing dependencies and running tests. Earlier this year, we built and deployed Jupiter, a high-performance job-matching system that pairs these tasks with the machines best equipped to handle them. Once in production, Jupiter reduced the latency of job assignments from minutes to milliseconds.
Engineers can iterate through the development cycle not just once, but several times a day or more. Our open source build tool Buck was designed for fast iteration, allowing engineers to compile and run code changes quickly. But as the codebase scaled, compilation times crept up and efficiency improvements became more incremental. By questioning some fundamental assumptions about the way software development works, we completely reimagined Java compilation, reducing the amount of code that Buck rebuilds on each cycle by 35 percent and reducing build times by 30 percent.
Every code change is run through a series of automated tests on hundreds of devices and emulators in our mobile device lab before they ship. We built a new management system for remotely managing these Android devices, iPhones, web browsers, and emulators with a simple API to more easily run and monitor tests. That system, known as One World, has grown to manage tens of thousands of remote resources and executes more than 1 million jobs each day.
One of the tests our code runs through is our open source static analyzer Infer. This year, we expanded the types of bugs that Infer looks for, and wrote a new declarative language for Infer that lets engineers easily write checkers for new types of bugs without needing deep expertise in static analysis. The Infer team developed the ability to detect concurrency bugs at scale, making significant progress toward solving an intractable problem in computer science. This new capability was instrumental in migrating our Android News Feed to a multi-threaded model, which improved scroll performance across the app’s surfaces.
All of these advancements played a part in helping engineers write high-quality code quickly. Shipping the code to production just as fast was equally important. In April, we transitioned to a continuous deployment model, where we push a few hundred code changes every couple of hours, 24/7.
At Facebook, we’re big believers in sharing our tools and code with the broader community. This year, we shipped several new, modern frameworks that boost performance while simplifying the code engineers need to write. We released complete rewrites of React, our declarative front-end library, and Relay, which pairs React components with GraphQL queries.
We open-sourced Litho, a declarative framework for building efficient UIs on Android. Litho seamlessly prepares UI components ahead of time, runs layout code in background threads, and renders incrementally to provide the best experience for users. We later added Sections, a way to structure data and translate it into Litho lists.
Litho was one of our most active new open source projects this year, garnering more than 4,000 followers and 1,500 commits from external developers. React and React Native remain our most popular open source projects, surpassing 82,000 and 56,000 followers this year, respectively. We released Yarn 1.0, a stable version of the JavaScript package manager we released in 2016 in conjunction with Google, Exponent, and Tilde. Yarn is now responsible for 3 billion package downloads per month and is used in more than 175,000 projects on GitHub.
One of the burgeoning areas of our open source program is machine learning. We open-sourced several new projects this year, including Fairseq, a learning toolkit for Torch tailored to neural machine translation, and ParlAI, a new platform for dialog research that unifies data sets and learning systems for training and testing dialog models. We released ELF, a flexible platform for game research, which aims to help develop AI models that can plan, reason, navigate, solve problems, collaborate, and communicate. In collaboration with other companies, we announced the Open Neural Network Exchange (ONNX), a standard for representing deep learning models that enables them to be transferred between frameworks.
Overall, we released 113 new open source projects across the stack in 2017, bringing our total portfolio to nearly 450 active projects. These projects collectively had more than 100,000 commits, almost a third of which came from external contributors. This healthy and vibrant ecosystem is a testament to our belief that working in the open allows us to innovate more quickly and move the entire industry forward.
That wraps up our 2017 year in review! We’re excited to take on new challenges in 2018 and look forward to sharing our solutions here.








