
- Adopting AV1 for real-time communication at Meta has been a multi-year effort spanning codec selection, device eligibility, rate control, and error resilience.
- We’re sharing the technical and operational challenges while deploying AV1 and expanding coverage, and how we addressed them for real-time communication.
- We’re presenting several technologies for improving AV1 call quality, including rate control and error resilience.
The AV1 video codec, first standardized by AOMedia in 2018, has rapidly evolved and gained widespread industry support. Today, leading companies like YouTube, Netflix, and Meta stream video using AV1 at scale. Meta introduced AV1 for real-time video calls on high-end devices in 2023, aiming to deliver superior call quality. Since then, we have made notable progress in expanding AV1’s reach and improving the experience for AV1-powered calls. Today, AV1 is enabled on the majority of mobile devices in Meta Real-Time Communication (RTC) applications such as Messenger and WhatsApp.
Why Is Meta Interested in Adopting AV1 for RTC?
The motivation for switching to a more advanced video codec is straightforward — it delivers the same visual quality while using much less bandwidth. In offline tests, we observed at least a 20% bitrate reduction with AV1 compared with H.264/AVC under our product settings on low-end and mid-range devices. If devices can accommodate higher encoding complexity, the bitrate reductions are even greater. For real-time video calls, this means people on slower or limited networks can enjoy significantly better video quality. This is important to our users because, to meet low-latency requirements, the RTC product must handle bitrate fluctuations. In real-world networks — especially in emerging markets — video bitrates for RTC products typically range from 10 kbps to 400 kbps. Maintaining good video quality below 100 kbps remains challenging.
To evaluate the user experience across codecs, we enabled AV1 in the Messenger app and conducted a side-by-side comparison using two Android phones. In the examples below, AV1 is displayed on the right and H.264/AVC on the left, both limited to 100 kbps. The H.264/AVC video appears noticeably blurry, while the AV1 video remains much clearer — highlighting the significant advantage of AV1 for video calls under bandwidth constraints.
| H.264/AVC (left) versus AV1 (right). |
An increased focus on screen content, needs support from high-quality computer generated content encoding. Traditionally, video encoders aren’t that well suited to complex content such as text with a lot of high-frequency content, and people are very sensitive to reading blurry text. AV1 has a set of coding tools — palette mode and intra-block copy — that drastically improve performance for screen content.
Palette mode is designed according to the observation that the pixel values in a screen-content frame usually concentrate on the limited number of color values. It can represent the screen content efficiently by signaling the color clusters instead of the quantized transform-domain coefficients. In addition, for typical screen content, repetitive patterns can usually be found within the same picture. Intra-block copy facilitates block prediction within the same frame, so that the compression efficiency can be improved significantly. AV1 has the benefit of providing these two tools at the main profile.
The Challenges in Adopting AV1
While the comparison clearly illustrates AV1’s advantages, there are significant challenges to its adoption in RTC. Unlike video on demand (VOD), RTC systems must manage end-to-end video latency, which ideally should remain below 300 milliseconds. If latency exceeds this threshold, people begin to notice delays in the conversation.
Maintaining both high video quality and low latency is challenging. For example, multi-pass encoding techniques — which can improve quality — introduce additional delay. On the decoder side, extensive buffering further increases latency. Additionally, any sudden spikes in bitrate can cause video freezes during calls, degrading the user experience.
RTC products must also dynamically adapt to network conditions during a call. Two challenges are fluctuations in network bandwidth and packet loss.To cope with bandwidth changes, the video encoder adjusts parameters such as resolution and frame rate. However, switching resolutions typically requires a new key frame, which can cause a sudden bitrate spike and temporary video freezing. Similarly, packet loss can trigger retransmissions or force the encoder to send another key frame, both of which may lead to video freezes. Effectively managing these issues helps enable delivery of high-quality, uninterrupted video calls.
Additionally, the RTC client must perform both real-time encoding and decoding, both of which consume significant power — making power efficiency important, especially on mobile devices.
Encoder and Decoder Selection
Choosing the right encoder and decoder is the most critical step in adopting a new codec. The computational complexity of video codecs is a significant consideration for mobile devices. While AV1 offers improved compression efficiency through advanced coding tools, these benefits come at the burden of increased computational demands, particularly during encoding.
To assess this increased complexity, in an offline experiment we integrated an open-source AV1 encoder and measured power consumption on a Pixel 8 device during a video call. The results showed a 14% increase in power usage compared to H.264/AVC — a significant challenge for mobile deployment. To address this, we adopted an internal low-complexity encoder that has similar power consumption as H.264 baseline, as detailed in the next section.
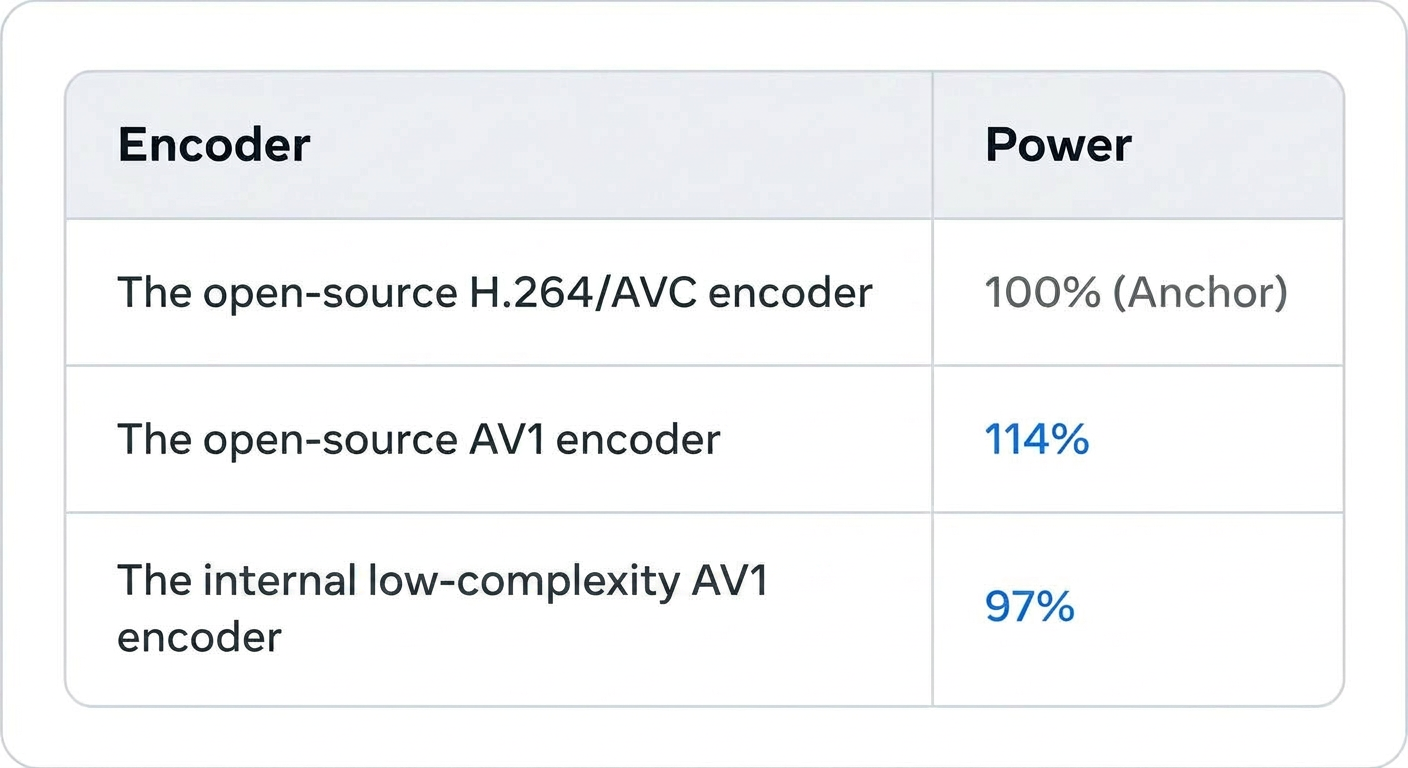
Beyond power, AV1 encoding also increases memory usage compared to H.264/AVC, leading to app crash regressions that further complicate mobile adoption.
Low-Complexity Encoder
A strong encoder should balance visual quality against computational complexity. Low complexity encoding helps enable AV1 encoding on mid-range and low-end devices.
Compared to older codecs like H.264/AVC, newer codecs such as AV1 deliver better compression efficiency. However, these benefits are thought of to come only with higher computational complexity — this represents an obstacle to extending AV1 coverage to low-end devices.
However, a newer codec should not necessarily require a higher-complexity encoder. Because modern codecs support a larger set of coding tools, a well-designed encoder has more opportunities to find better trade-offs between quality and complexity. These trade-offs are also referred to as presets. Ideally, the encoder offers multiple presets, spanning a range from high to low complexity while still maintaining a consistent compression efficiency gain. An ultra-low-complexity preset comparable to H.264/AVC could enable shipping AV1 on low-end phones.
To address this, we adopted a low-complexity encoder implementation of AV1 for the RTC use cases. In addition to optimizing the quality of the high-complexity preset, we developed an ultra-low-complexity preset. This new preset delivers encoding complexity comparable to H.264/AVC. With it in place, we designed a mechanism that adjusts the encoder preset based on device capabilities, enabling us to ship AV1 to a much broader range of devices.
Decoder Selection
After selecting the encoder, the next step is choosing the decoder. Although video decoders are generally less complex than encoders, we found that decoding complexity remains significant on mobile devices and video calling usecases, especially low-end models. In our initial A/B tests, some low-end devices could not perform real-time decoding, resulting in video freezes and audio/video synchronization issues.
We compared several open-source decoders and, after A/B testing, we selected dav1d for its superior power efficiency and reliability. Our experiments also showed an increase in talk time with the dav1d decoder.
Binary Size
Integrating the AV1 encoder and decoder into the mobile app introduces another challenge: binary size. Using libAOM as an example, AV1 support adds 1.7 MB to the application (600 kB compressed). While this may sound negligible, it’s a major challenge for a company that serves billions of users. Binary size affects update success rates, application startup time, and software health metrics like memory usage and crash rates which can negatively impact user experience. A larger binary leaves more people on older app versions and delays incoming call setup. For example a 600 kB increase could consume an entire year’s binary size budget for a large organization.
We explored several approaches to reduce the binary size.
- Our initial approach was to use a dynamic-download framework to deliver AV1 as a separate component. However, download failures — whether from poor network conditions, device issues, or random occurrences — degraded the user experience, making this approach insufficient.
- We then focused on direct binary size optimizations. For example, the quantization matrix (QM) tool accounts for about 10% of the encoder’s library size; optimization could halve it. We also contributed size reductions optimizations to the dav1d project.
This strategy extends to end-to-end pipeline optimization, removing unused tools from the library entirely. For instance, removing QM frees 60 kB of binary space. At the application level, we can share codec libraries across features — such as video message transcoding — and leverage built-in platform codec support to avoid bundling additional libraries.
Expanding AV1 Coverage
After selecting the encoder and decoder, the next challenge was identifying which devices are eligible to use AV1. Compiling eligible iOS models was straightforward given the limited number of variants, but Android posed a far greater challenge due to the vast number of device models.
We initially tried selecting devices based on memory, release year, and Android OS version, but none of these strategies proved sufficiently reliable. Ultimately, we leveraged Meta’s in-house ML-based device eligibility framework to generate a reliable list of eligible Android devices.
AV1 Device Eligibility
We created a machine learning (ML)-based device eligibility framework to support advanced video and audio features based on device capability:
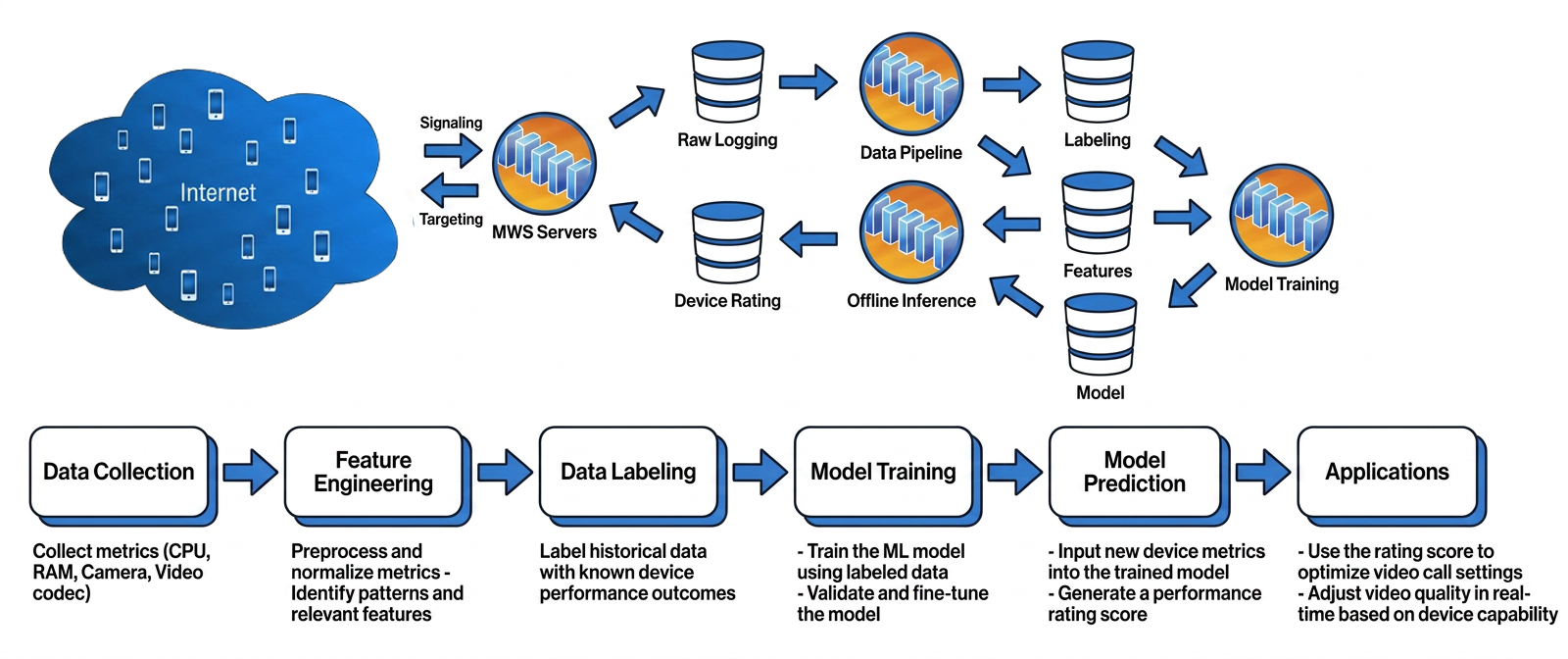
The idea is to use large-scale real-world statistical data to categorize device capabilities, rather than relying on lab data. This helps us scale our device eligibility system and make more accurate decisions. We propose an ML-based device eligibility approach that uses low-level performance statistical metrics collected through our logging pipeline to assess a device’s AV1 capability. The model takes these measurements as input features and outputs an rtc_score, which quantifies the device’s overall AV1 performance. This score then informs decisions such as optimizing call settings and determining whether a device can run the AV1 codec efficiently.
In 2025, we iteratively refined our model using AV1-specific data and significantly expanded device support. Our first milestone, Model V1.1, rolled out in August 2025 and broadened AV1 traffic across an increasing set of devices. That additional traffic contributed to a dedicated AV1-only dataset that became both larger and more representative over time. With this richer data, we built Model V2, introducing a two-tier approach that differentiates between higher-end and lower-end devices—reflecting the reality that entry-level phones and flagship devices can have very different AV1 encoding capabilities. Across these iterations, we substantially increased AV1 enablement across the device landscape, with an approach designed to keep improving as traffic grows and more data becomes available.
As AV1 traffic continues to grow, we expect iterative optimization will further improve both call duration and quality.
Codec Complexity Adaptation
Device eligibility lets us identify capable devices, but we discovered an additional challenge: During A/B tests, we observed calls with significant audio/video sync regressions, primarily caused by devices unable to encode or decode video in real time. Surprisingly, even a 2023 smartphone with an octa-core processor could not handle encoding at 320×180@15fps. This issue affected both H.264 and AV1, though it was more prevalent with AV1. We suspect these devices throttle CPU frequency during calls, reducing their effective capability.
As a result, enabling AV1 purely based on device name is not sufficient. We needed a more robust mechanism to adjust codec complexity based on both local and peer device status. We developed three mechanisms: adaptive encoder preset adjustment, encoding latency-aware codec switching, and decoding latency-aware codec switching.
Adaptive Encoder Preset Adjustment
We designed multiple encoder presets ranging from low to high complexity. A monitoring mechanism continuously tracks encoding latency during calls to select the appropriate preset. If encoding latency becomes too high — meaning the device is close to being unable to encode in real time — we reduce encoder complexity. Conversely, if the device can sustain higher complexity, we increase the preset to achieve better quality.
Local Device Encoding Latency-Aware Codec Switch
If lowering the encoder preset still does not reduce encoding latency to an appropriate level, we apply codec switching. In this case, the device switches to H.264/AVC, which may be less computationally intensive than AV1 for that specific content. To enable this, we negotiate support for both codecs at call setup, and the client continuously monitors device conditions to determine the most appropriate codec. Encoder preset and codec selection are decided jointly to optimize call quality and prevent codec-selection oscillation.
Peer Device Decoding Latency-Aware Codec Switch
Because AV1 also has higher decoding complexity, we want to ensure the peer device can decode AV1 frames in real time. This is especially important when a high-end phone calls a low-end phone: the sender may be able to encode AV1, while the receiver may not be able to decode it in real time.
To address this, each device continuously feeds back its video decoding latency during the call. If the sender detects that the peer cannot decode AV1 in real time, it switches back to H.264/AVC.
Together, these mechanisms adaptively adjust both the encoder preset and the codec based on encoding and decoding latency. Beyond latency, we also consider other device health signals, such as battery level. For example, when the battery is low, we switch to H.264/AVC. This helps maintain call quality and extends call duration.
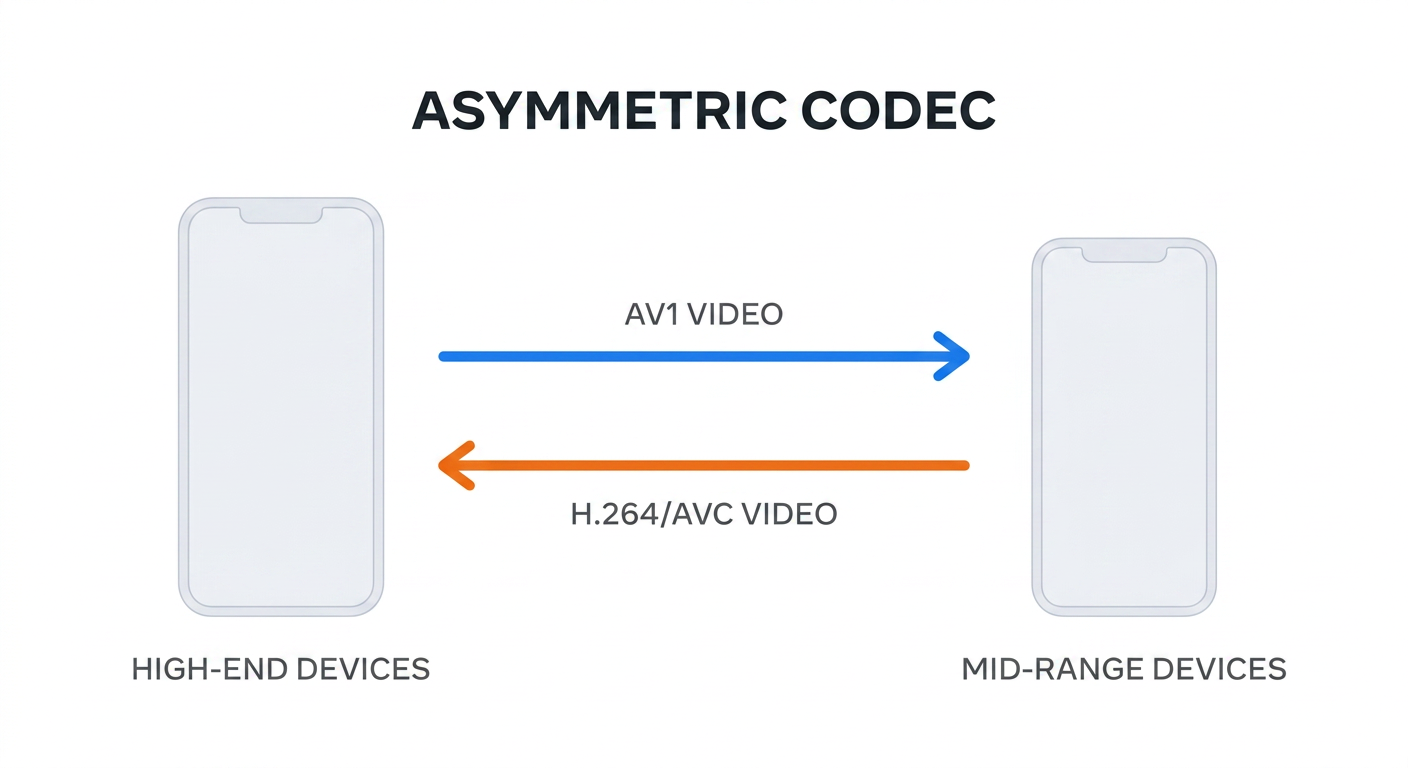
Asymmetric Codec Design
With the improved codec-selection strategy, we rolled out AV1 support to mid-range and low-end Android devices. While some mid-range devices cannot perform real-time AV1 encoding, many can decode AV1 in real time. This enables an asymmetric codec design: mid-range devices continue to encode and send H.264/AVC, but can receive AV1 from high-end peers. As a result, we significantly increased AV1 coverage across Android devices.
Improving AV1 Call Quality
The preceding sections described our framework for enabling AV1 on a wide range of devices. With this system in place, AV1 now powers the majority of mobile devices in Meta RTC (Real-Time Communication) applications. . The next challenge is further improving AV1 call quality.
As discussed earlier, RTC products must dynamically adapt to network conditions during a call. Two notable challenges are fluctuations in network bandwidth and packet loss. Accurate rate control helps address bandwidth changes. Error-resilient strategies play an important role in ensuring reliable quality in the presence of packet loss.
Accurate Rate Control
In RTC, maintaining a constant bitrate (CBR) is important. Any instantaneous bitrate overshoot can lead to congestion and video freeze on the peer’s side. RTC applications are sensitive to instant bitrate overshoots, so simply checking average bitrate is insufficient. We use Video Buffering Verifier (VBV) delay as a metric to evaluate CBR accuracy.
VBV Delay
The Video Buffering Verifier (VBV) is a leaky-bucket-based measurement used to ensure that an encoded video stream can be correctly buffered and played back at the decoder.
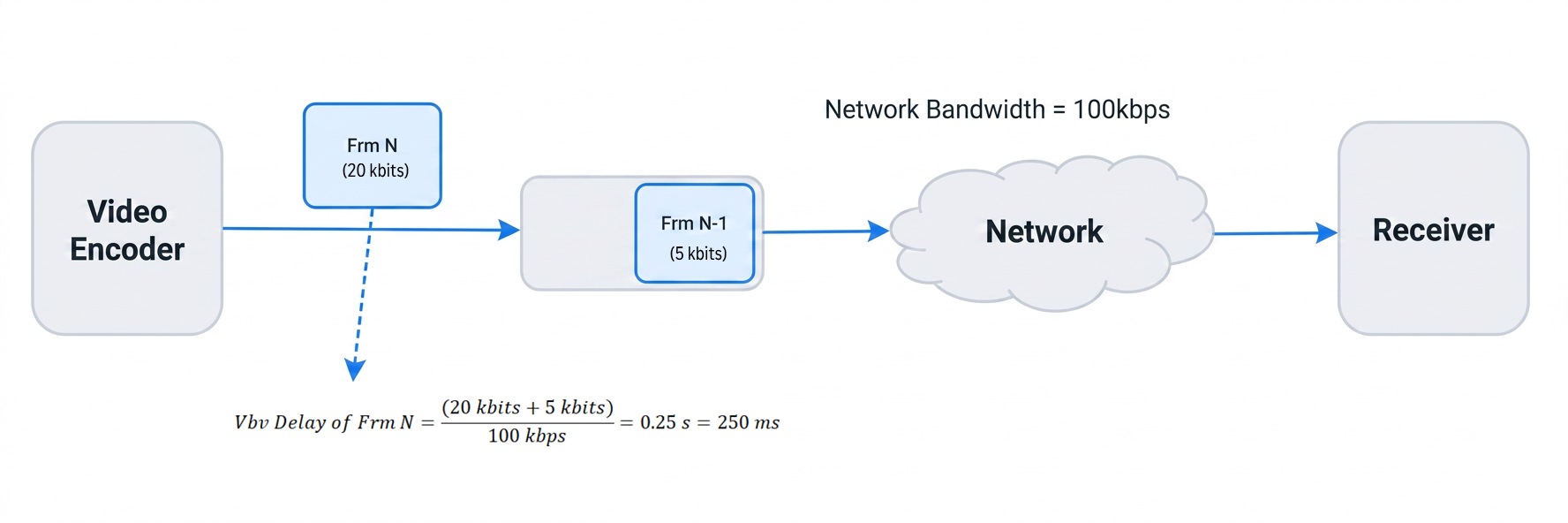
We use a similar method to measure CBR rate control accuracy. The figure below shows an example:
Assume the current network bandwidth allocated to video is 100 kbps and we ask the encoder to encode frames at 100 kbps. The encoder encodes Frame (Frm) N at 20 kbits. At the same time, Frame (Frm) N-1 has not been fully transmitted, and 5 kbits remain in the buffer (likely from an overshoot on Frame N-1).
Sending Frame N would therefore take at least (20 kbits + 5 kbits) / 100 kbps = 0.25 s = 250 ms. Consider a system in which the desired VBV delay for RTC is below 200 ms. In this example, encoder overshoot and a large VBV delay are likely to lead to a poor user experience—for example, higher latency, network congestion, or video freezes. This highlights the importance of accurate rate control for RTC use cases.
Rate Control Optimization
We made several rate-control improvements to ensure the encoder does not overshoot. During encoding, the encoder tracks VBV buffer status and uses it to guide bitrate allocation. When an overshoot occurs, it reduces the rate of subsequent frames to keep VBV delay under control. In our experience, many video encoders do not handle this well, allowing VBV delay to grow and potentially cause network congestion.
Similarly, encoders often allocate a high bitrate to intra-only (key) frames to maintain quality consistency between key frames and inter frames. Some encoders even “boost” key-frame quality to improve reference-frame quality. In RTC, however, we want to avoid bitrate spikes. The encoder therefore strictly controls key-frame bitrate and reduces the rate of subsequent frames to compensate for any overshoot.
Rate control in RTC also presents challenges:
- Frequent target bitrate changes. The client may update the encoder target bitrate frequently. A robust encoder must keep VBV delay under control — especially when the target bitrate drops sharply.
- Frequent resolution changes. The client may also change resolution often during a call. A rate-control algorithm should therefore remain stable and effective under frequent resolution changes. In addition, AV1 supports a useful feature to address this issue, called Reference Picture Resampling (RPR), which allows resolution changes without generating a key frame. This can reduce bitrate spike significantly and improve the video freeze.
Because the video encoder interacts closely with the network congestion-control module, we found that preventing undershoot is as important as preventing overshoot. In our early versions of the rate-control algorithm, we used conservative rate allocation to avoid overshoot, but this increased the tendency to undershoot. Undershooting can mislead bandwidth estimation, slow bitrate ramp-up, and ultimately degrade video quality. We therefore revised the algorithm to address undershoot and improve bitrate accuracy.
Overall, an accurate rate-control algorithm that produces a stable bitrate — without significant overshoot or undershoot — can substantially improve video-call quality.
Error Resilience
RTC imposes strict latency constraints, while modern video codecs rely on long, tight chains of inter-frame dependencies. When a packet is lost, the receiver must send a NACK and wait a round trip for retransmission. If that fails, the dependency chain breaks and the video freezes. The receiver then requests a keyframe, which costs another round trip, but because keyframes are roughly 10x larger than typical P-frames, they can congest the network and increase packet loss, creating a problematic cycle. To mitigate this, we tuned AV1 for fast recovery and drift containment under packet loss by leveraging temporal layers (TL) and Long-Term Reference (LTR) frames.
Temporal Layer (TL)
Temporal layers are a form of temporal scalability used in modern video codecs (including AV1) where the encoder organizes frames into a time-based hierarchy. The base layer (temporal layer 0) provides a lower frame rate on its own, while enhancement layers (temporal layer N) add intermediate frames to reach higher frame rates when conditions allow. Figure 4 shows the two-layer structure we use for AV1.
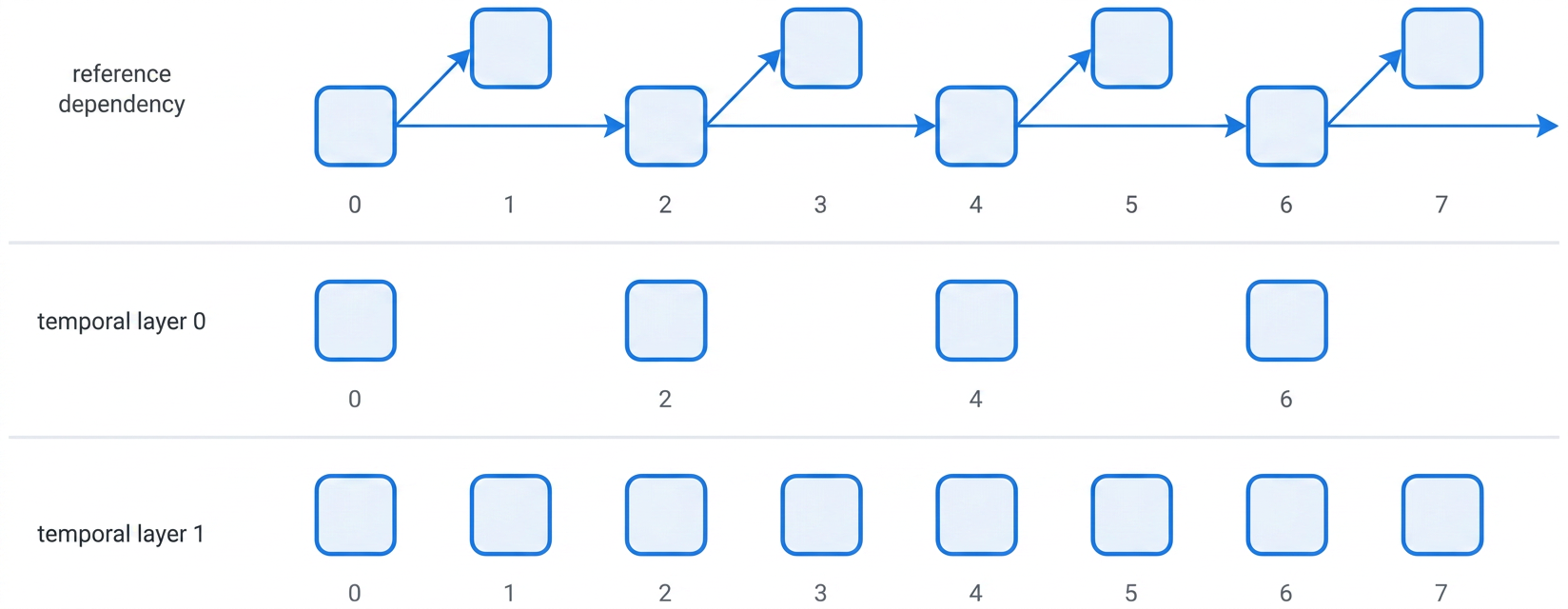
A notable property of this structure is that the base layer maintains continuity, without relying on enhancement-layer frames.If enhancement-layer packets are lost or arrive too late, decoding can still proceed using the base layer without stalling. We take advantage of this by prioritizing robustness by layer: We apply FEC to protect base-layer data rather than spending redundancy on enhancement data. We also treat enhancement-layer retransmissions more conservatively — when round trip time (RTT) is low, retransmitting a missing enhancement packet can help; when RTT is high, we may skip retransmissions without breaking the decode flow.
There is a trade-off: Compared to a tightly dependent prediction chain (where each frame references the immediately preceding frame), a temporal-layer structure is typically less compression-efficient, so leaving TL enabled all the time can degrade quality at a given bitrate. But TL’s benefits show up mainly under lossy or unstable networks, which are only a subset of real-world calls. For that reason, we enable TL adaptively. The sender monitors network feedback, turns TL on when loss rises, and turns it back off once conditions recover. This gives us resilience when we need it without sacrificing efficiency when we don’t.
Long-Term Reference (LTR)
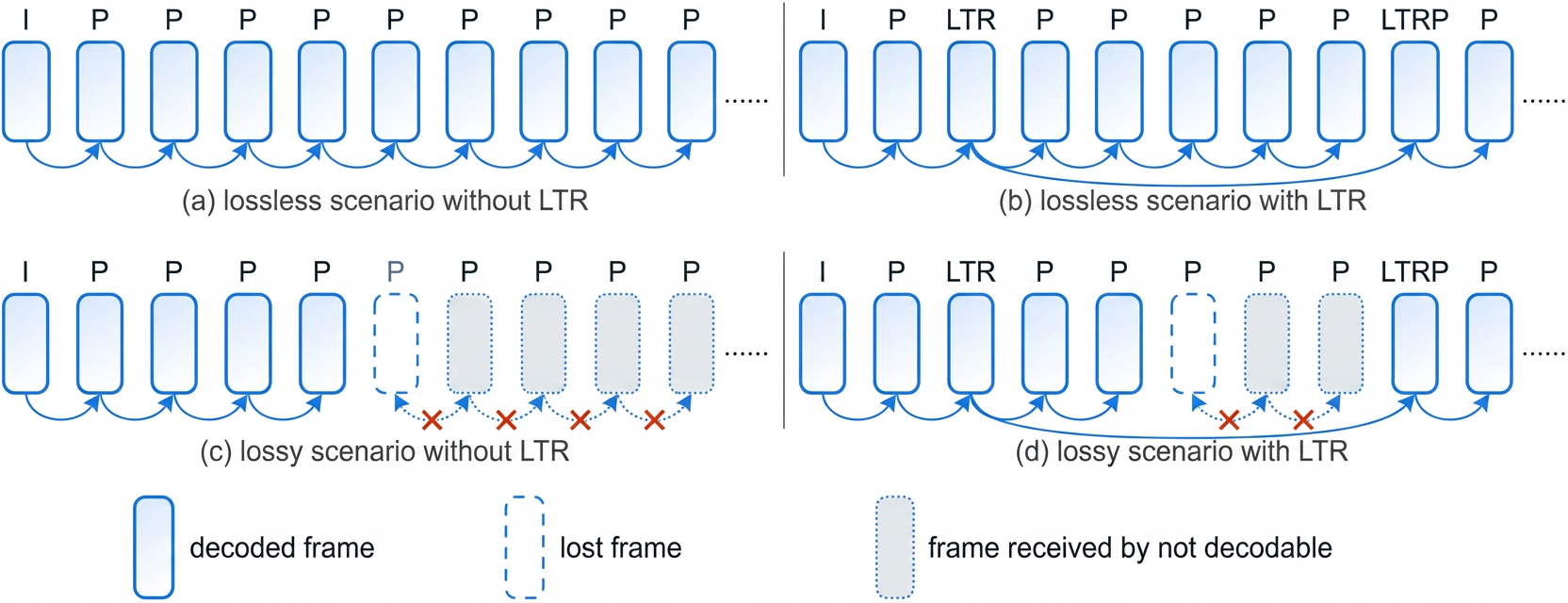
LTR is an error-resilience feature that allows a video encoder to store reference frames in the buffer longer than regular reference frames and send LTR-predicted (LTRP) frames as requested. When the decoding chain is broken due to frame loss, an incoming LTRP frame—predicted from a previously decoded LTR frame—instantly resynchronizes sender and receiver, recovering from the loss. Figure 5 illustrates how LTR and LTRP frames work in lossless and lossy scenarios.
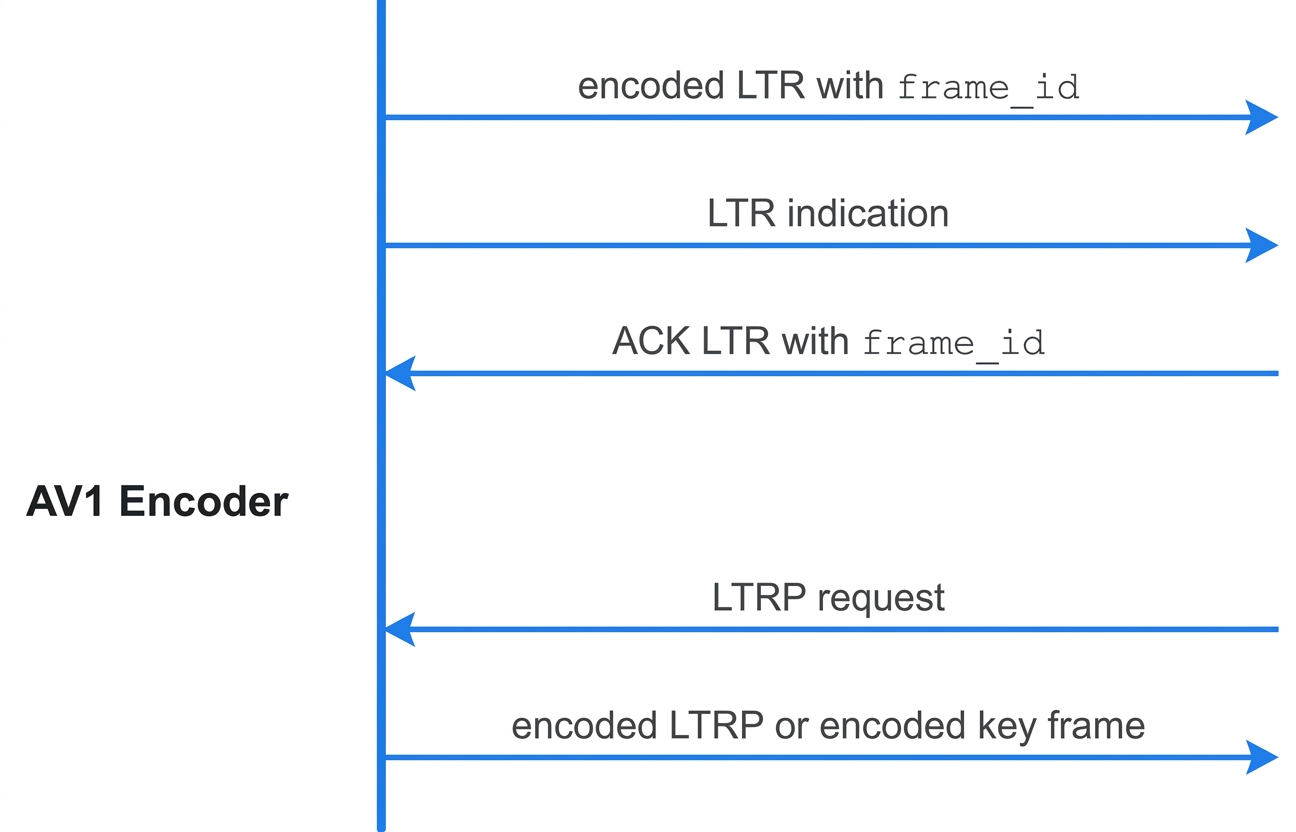
Implementing LTR requires close coordination with the network layer. Figure 6 shows how the AV1 encoder interacts with the network layer. The encoder periodically emits LTR frames and pins them in its bounded reference buffer of size 4, evicting the oldest pinned LTR when a new one is added. From the network layer’s perspective, however, an encoded LTR frame looks the same as any other frame, so the network cannot tell when to send an ACK back to the encoder. To make this reliable, the encoder sends an explicit LTR indicator when handing the frame to the network layer. This differs from H.264, where LTR and non-LTR reference frames are distinguished by bitstream syntax — the network layer can parse the H.264 slice header to recognize an LTR frame and ACK the sender upon receipt.
The explicit LTR indicator is a binary flag carried in our proprietary RTP header extension, which we use to transport per-frame metadata on the primary channel. We also expose the frame_id to the network layer through LTR bitstream syntax. ACK feedback is sent via a separate proprietary RTP header extension. Each ACK includes the corresponding frame_id, allowing the sender to unambiguously identify which LTR was received. When servicing an LTRP request, the encoder always uses the most recently ACKed LTR as the prediction reference.
The network layer requests an LTRP frame from the encoder in two cases. The first is reactive recovery, when the receiver experiences a freeze and sends an RPSI to request an LTRP. The second is proactive protection, when the sender detects elevated packet loss via a feedback channel and asks the encoder to send LTRPs periodically. While the proactive path can be somewhat redundant, it significantly improves reliability and reduces freezes. From the encoder’s perspective, the reason does not matter — it simply receives an LTRP request and responds based on whether it has an ACKed LTR reference in the buffer. If an LTR is available, the encoder produces an LTRP frame. If not, it assumes resynchronization is needed and sends a key frame instead.
While LTR is more efficient for loss recovery than forcing a key frame or relying on retransmissions, it can reduce overall coding efficiency because an LTRP frame may reference an older LTR with weaker temporal correlation, making motion prediction less accurate. We mitigate this by leveraging an existing encoder design choice — the encoder already emits a periodic, slightly higher-quality frame to improve overall quality. We simply mark that frame as LTR, so the LTR remains high quality even as it ages.
Meta’s Ongoing Journey With AV1
Adopting AV1 for real-time communication at Meta has been a multi-year effort spanning codec selection, device eligibility, rate control, and error resilience. By combining a low-complexity encoder with ML-based device eligibility, adaptive codec switching, and robust error-resilience mechanisms, we have enabled AV1 on the majority of mobile devices — delivering meaningful quality improvements, especially for users on bandwidth-constrained networks. This initiative complements our ongoing efforts to expand AV1 for VOD applications. As device capabilities continue to improve and ML models leverage more data, we expect AV1 coverage and call quality to keep advancing.
Meanwhile, we are working on extending AV1 to group calls. Unlike 1:1 calls, participants in group calls must decode multiple video streams, which makes increasing AV1 coverage in group calls more challenging. While software AV1 implementations aid the steady expansion of AV1 coverage, higher quality and improved features will likely require AV1 hardware support.
The benefits of AV1 are clear, and most content and RTC service providers are moving to AV1 as their flagship codec. We encourage SoC vendors to invest in HW AV1 across all device tiers to meet the AV1 requirements to deliver an improved viewer experience, device battery savings and enhanced network operator infrastructure efficiency.








