
We always want Facebook's products and services to work well, for anyone who uses them, no matter where they are in the world. This motivates us to be proactive in detecting and addressing problems in our production infrastructure, so we can avoid failures that could slow down or interrupt service to the millions of people using Facebook at any given time.
In 2011, we introduced the Facebook Auto Remediation (FBAR) service, a set of daemons that execute code automatically in response to detected software and hardware failures on individual servers. Every day, without human intervention, FBAR takes these servers out of production and sends requests to our data center teams to perform physical hardware repairs, making isolated failures a nonissue.
As our infrastructure continues to grow, we also have to be proactive in detecting and addressing problems at the rack level or for other failure domains such as network switches or backup power units. Given that multiple services can be collocated on a single rack, performing this type of maintenance on a daily basis would interrupt dozens of teams, some multiple times, throughout the year.
To help minimize disruption, we built an enhancement on top of FBAR called Aggregate Maintenance Handlers that provides a way to safely automate maintenance on multiple servers at once. For cases where automation isn’t enough, we also developed Dapper, a tool that enables manual intervention to ensure that scheduled maintenance can proceed safely. The rest of this post will explore how the Aggregate Maintenance Handlers work for various outage scenarios, including what happens when automation fails, and how Dapper is used to coordinate automated and manual processes.
Automating with Aggregate Maintenance Handlers
While FBAR includes methods to disable and reenable a single host at a time, executing these methods serially or in parallel was not a safe enough approach for the purpose of working on multiple hosts at once. The serial approach could be time-consuming or risk a service running out of capacity one server at a time. The parallel approach was prone to race conditions and could run a service out of capacity even faster.
Aggregate Maintenance Handlers offer a framework to automatically disable and enable servers in bulk, providing our engineers with full context on the maintenance work being performed and the full scope of servers affected.
Making decisions based on maintenance impact
Outages vary in size, length, and type: Some can affect a single rack, some can affect several; they can be long or short; some can affect only network connectivity while others can interrupt power supplies. Different services deal with different outages in different ways. When we schedule maintenance work, we give the Aggregate Maintenance Handler four pieces of information to determine the impact it will have on our overall infrastructure:
- Scope (a full list of servers affected by the maintenance)
- Maintenance type (network interruption, power interruption)
- Maintenance start time (e.g., 10:00 a.m. Pacific Standard Time)
- Maintenance duration (e.g., two hours)
Our engineers can then use this impact description to make decisions about automation and optimize how the outage should be handled. Let's look at three simplified examples:
- A stateless web server could handle a network or power interruption of any length by being removed from a load balancer pool. The only concern in this case would be to ensure that there are enough web servers still available to handle all requests.
- A cache machine serving a static index from memory could handle a lengthy network interruption by being taken out of a load balancer pool. Once the network is restored, the machine could immediately resume serving the index. A short power interruption, on the other hand, would require reloading the index into memory. Dealing with a reboot would require proactively replacing the server with one not affected by the same maintenance.
- A MySQL replica with a busy replication stream could handle a short power interruption. The host would be removed from a load balancer pool, data would be stored on disk, and the MySQL server would quickly catch up on replication after rebooting. Conversely, interrupting network connectivity for hours could cause it to fall too far behind, making a proactive replacement of the replica server a better option.
Taking into account the length and type of interruptions allows us to build a simple decision-making matrix for each service:

Handler disable/enable process
Once the appropriate maintenance has been selected and scheduled, the handler follows a four-step flow to disable the affected hosts:
- Preflight check
- Pre-disable
- Host-level disable
- Post-disable
Preflight check: The preflight check is called at the start of the disable process and checks whether there would be enough capacity available in the unaffected servers for the maintenance to be performed safely. It returns a true or false response that either allows the maintenance work to move forward or halts it, respectively. The preflight check can also be called independently as part of a scheduling process, giving teams more time to handle scenarios where the preflight check might return false.
Let's imagine the following six-rack row in a data center with the given constraints:

Now let's imagine two maintenance scenarios:
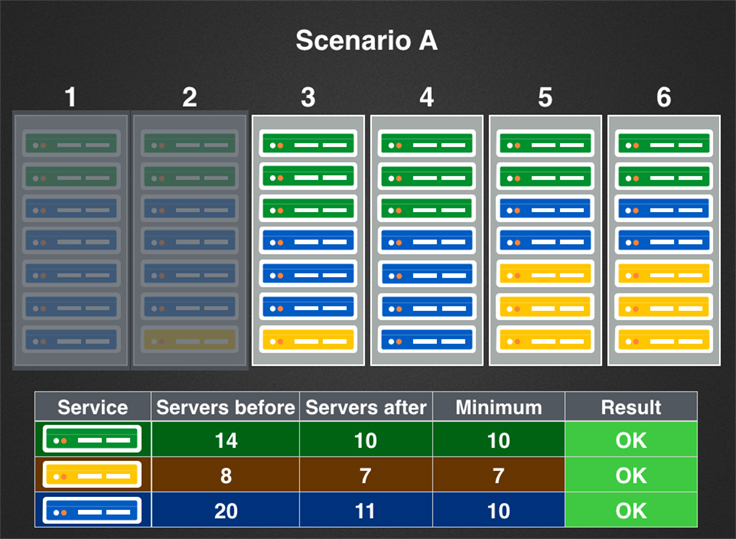

Preflight checks for the web servers would pass in both scenarios, but in scenario B, preflight checks would fail for both the cache and database servers, and the maintenance would not be allowed to proceed automatically. (This scenario is addressed in more detail in the next section.)
When all preflight checks pass, our Aggregate Maintenance Handlers allow us to wrap a smarter layer of code around pre-existing host-level disable/enable logic.
Pre-disable: This step is generally used to ensure that hosts currently considered spares in our pools are not accidentally reintroduced into production when multiple hosts are swapped out during host-level disable or bulk operations.
Host-level disable: In some cases, this is a no-op because hosts were bulk-disabled in the pre-disable step. In all other cases it becomes a parallel execution of host-level disable logic inherited from FBAR.
Post-disable: This step is used primarily to verify that pre-disable and host-level disables succeeded. It also allows the author to inspect the results of the host-level disable step and decide whether to ignore certain types of failures if they remain below a desired threshold.
This flow is represented in the following animation:

The enabling process is identical to the disable process: pre-enable, host-level enable, and post-enable. With automation, we can safely perform regular maintenance at the rack or multi-rack level while minimizing disruption to other engineering teams and the services that people on Facebook use.
Coordinating with humans: When automation isn't possible (or fails)
Although our goal is to be able to automate all of the maintenance work that needs to happen in our infrastructure, there are times where manual intervention is required to ensure that the maintenance can happen safely.
Failed preflight checks or no automation
In some cases, it's possible that the scheduled work affects large enough sets of servers that the preflight checks will refuse to allow the maintenance to proceed automatically. Our automation is intentionally conservative and prefers manual intervention over possibly risky larger-scale operations. In other cases, automation has not yet been implemented or has been temporarily disabled, either for reliability reasons or because a service is in a degraded state and we prefer to prevent automated changes from happening.
Failed automation
Even though we have a high success rate when we invoke our Aggregate Maintenance Handlers, there are still occasions where things go wrong. When a failure happens, our maintenance process notifies the service's owner that the automation has failed. Once they've manually confirmed that the hosts have been properly disabled, the maintenance is allowed to continue.
Mixing automation and manual work
To help coordinate automated and manual processes, we've developed Dapper, a tool that can be used by a variety of teams (e.g., data center teams, technical program managers, infrastructure engineers, production engineers) to schedule maintenance work by providing the impact description mentioned above (hosts affected, maintenance type, start time, and duration).
The workflow for maintenance executed by Dapper is as follows:

Lessons learned
We learned a few lessons early on as we were scaling from automated single-host repairs up to rack-level and multi-rack maintenance work.
Serial use of disable logic
Disabling hosts one at a time had two possible negative side effects. The first was running out of capacity at some point during the maintenance, resulting in the maintenance work being blocked until a human intervened:

Worse, when the swap logic for a service preferred to reuse hosts in the same rack, we could either accidentally reintroduce hosts back into production, or at best, run into an infinite loop:

Parallel use of disable logic
Swapping hosts in parallel rather than one at a time could possibly prevent some of the issues seen in the serialized approach, but introduced other problems. The most common problem was that invoking single-host logic in parallel would cause a race condition where individual operations would find a replacement host, but the aggregate result would cause a service to run out of capacity:

Expanding automation
The framework provided by Dapper and Aggregate Maintenance Handlers has grown beyond just physical maintenance work, expanding to include disabling and enabling hosts as part of software releases, or kernel, BIOS, and OS upgrades.
The production engineers working on Dapper are passionate about further expanding the reach of automation and building tools that allow Facebook's engineering teams to lower the burden of operations work, freeing them up to tackle bigger, more challenging problems.
For more on FBAR and Aggregate Maintenance Handlers, watch this presentation.








