
Every time you visit Facebook, you see hundreds of pieces of information from the social graph: not only posts, photos, and check-ins from your friends, but also the likes, comments, and shares for each. Because this information is always changing — there are millions of writes and billions of reads every second — the information you see can’t be prepared in advance. This experience is customized for every person who uses Facebook, in real time, for every piece of content he or she interacts with.
The social graph is made up of nodes and edges, or objects and associations, that all have a list of attributes. A typical query on the graph starts at a node and fetches all edges of a given type for that node. For example, the query could start at a node that represents you and fetch all your friends in a particular order, such as the order in which you friended them.
The way we query this information has evolved from memcached and MySQL into a system called TAO (The Associations and Objects server) which was optimized for a very high volume of single-hop queries. Since we started using TAO, the number of people who use Facebook has grown significantly, and we see a lot more content with much higher engagement. There are posts that receive millions of likes, while features such as Live video can get hundreds of thousands of comments, in several languages, in a matter of minutes. This makes it even more challenging to show people the pieces of information that are most relevant to them. While the simplifications built into TAO are useful a majority of the time, we needed additional optimizations for high-volume, multi-hop queries.
Dragon, a distributed graph query engine, is the next step in our evolution toward efficient query plans for more complex queries. Dragon monitors real-time updates to the social graph modeled as objects and associations and creates several different types of indices that improve the efficiency of fetching, filtering, and reordering the data. With Dragon, far less data is transferred over the network to the web tier, improving latency and freeing up CPU for other computation.
Indexing techniques
Let’s say Alice has thousands of Facebook friends, speaks both English and Spanish, and likes Shakira on Facebook. When Alice visits Shakira’s page, we display a “like sentence,” such as your friends Bob and Charlie and 104 million people like this page. If there is a post with hundreds of thousands of comments, we display the comments in the languages Alice speaks at the top.
TAO can fetch several thousand associations at the same time, which is acceptable for most queries but can cause increased latency when the amount of data queried is large. When Alice visits Shakira’s page, our current systems cache a subset of comments in RAM sorted by a single integer called timestamp (ts), and the application performs a filter by paging through thousands of comments to find the ones in the relevant languages and then reorders the data.
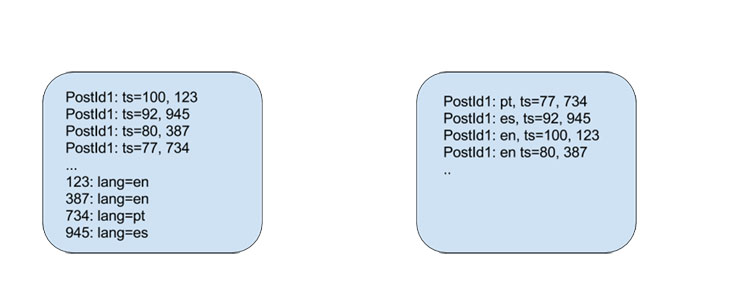
With Dragon, we specify an index and filter by the attribute of interest as we traverse the graph. When a query hits for the first time, Dragon falls back to TAO to set up the initial data in RocksDB on persistent storage. Dragon stores the most recent data or data that is likely to be queried the most often; pushing the code closer to storage allows queries to be answered much more efficiently. So, for example, when Alice visits Shakira’s page, it’s possible to compute a key involving <PostID, Language> and seek directly to the posts of interest. We can also do more complex sorting on persistent storage — for example, <Language, Score, CommentID> — to reduce the cost of the query.
While most people on Facebook don’t receive a high volume of comments on every post they make, many people tend to upload a lot of pictures. A typical photo upload on Facebook results in about 20 edges being written to MySQL and cached in RAM via TAO. These edges might include things like who uploaded the photo, where the photo was taken, whether anyone was tagged in the photo, and so on. The idea was to take advantage of the fact that most of this information is read-mostly, so we could do most of the work at write time. But this information required storage. Data size grew 20x over six years; about half the storage requirement was for data about edges — but only a small fraction of it described the primary relationship between two entities (for example, Alice → [uploaded] → PhotoID and PhotoID → [uploaded by] → Alice).
With Dragon, we write only this primary edge, and then create indices based on how we want to navigate. While indexing makes reads faster, it makes writes slower, so we create an index only when it makes sense. A post with 10 comments, for example, doesn’t need an index because it’s easy enough to scan through the comments individually with TAO. The combination of partial indexing techniques and a richer query language that supports a filter/orderby operator allows us to index a system that is roughly 150x larger while serving 90 percent of queries from the cache.
Socially aware inverted indices
We observed that people query friends’ basic profile information (such as names and birthdays) very often; this data is read-mostly, with very few writes. Such data is amenable to denormalization. By copying Alice’s basic profile information to all the hosts that are responsible for a friend, we can answer queries about friend names by talking to just one host. This comes with a trade-off between consistency and availability. While indexing makes reads faster, writes are slower. Each write needs to be replicated to all hosts that have a friend, with the possibility that some writes will fail.
Inverted indexing is a popular technique in information retrieval. When Alice likes Shakira, we store two edges (Alice → [likes] → Shakira and Shakira → [liked-by] Alice) on the host responsible for Alice. What we get is a distributed inverted index, because the Shakira likers aren’t limited to only one host. Querying such an index requires communication with all hosts in the cluster, which significantly increases latency and the cost of the query.
What’s unique in Dragon’s implementation is that the layout of these indices on storage is optimized based on a deeper understanding of query patterns (e.g., many queries are about friends), as opposed to accepting random sharding, which is common in these systems.
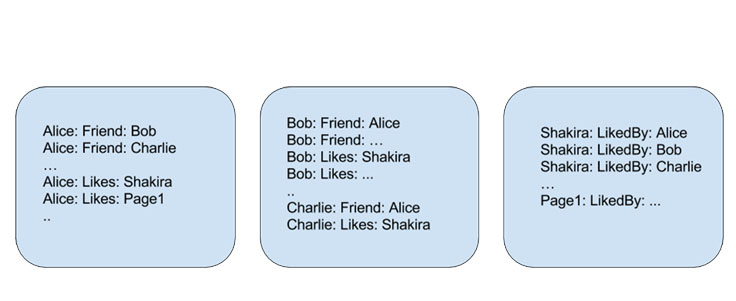
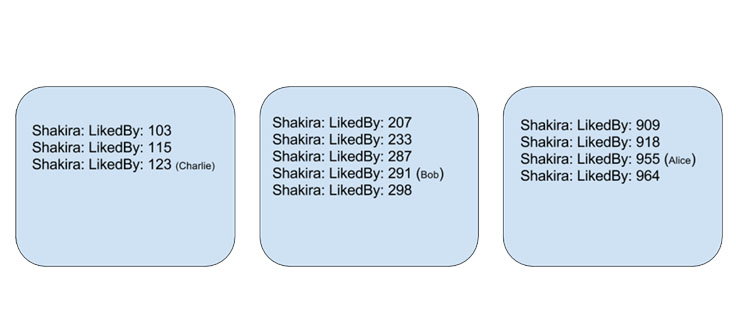
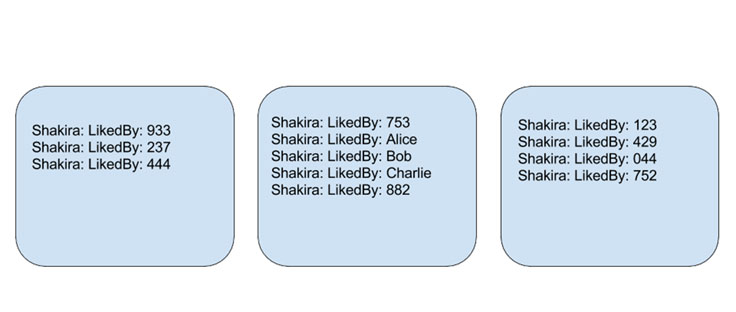
At this point, we’ve implemented this concept only for people, but this work is easily extensible to other types of objects in the graph. Early data indicates that this could reduce the storage device block reads by 30 percent and CPU usage by around 7 percent, compared with an earlier version of Dragon that did not use inverted indices. Most of the benefit can be attributed to the fact that Shakira likers now occupy a small number of storage device blocks compared with many when the forward index is randomly distributed.
Dragon comes in two flavors: an index-only variant that is optimized for queries about one object in the graph and sharded exactly like MySQL and TAO. The second flavor is optimized for queries on friend edges (“my friends who do X”), which are very common. This flavor requires an aggregator tier and an update service that’s capable of shuffling data from one sharding scheme to another. Both rely on a distributed log capable of replay with at-least-once semantics.
Friends, likes, and comments are some of the most common edges in the facebook graph. We try to leverage this locality via offline graph partitioning techniques. Our initial efforts at leveraging offline computation primarily involved balanced partitioning of the social graph based on friend edges. Along with fanout optimization techniques, we managed to achieve 3x lower fanout and a corresponding decrease in average latency compared with a randomly sharded service.
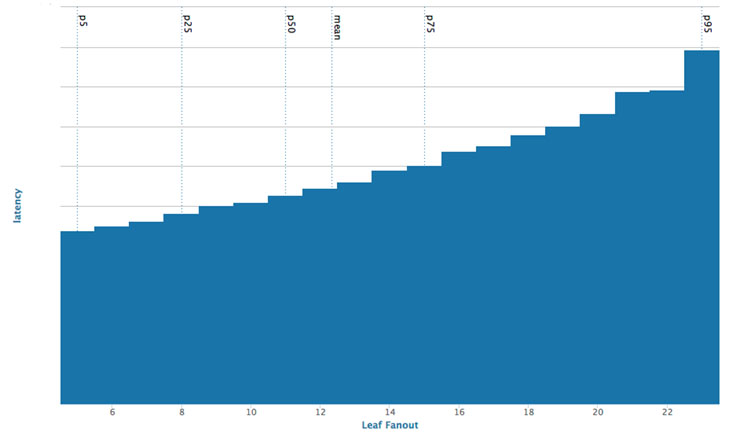
Such an algorithm presents both opportunities and challenges. The relationship between query time and number of friends is not linear, so we can query much larger batch sizes, which contributes to our efficiency. However, the total query time is dependent on the slowest query, so if one host takes on the order of 100 ms to respond (as opposed to roughly 10 ms), we see a higher latency. By using multi-core machines, it’s possible to use more than one CPU to parallelize query execution, so we can achieve the right balance and respond to large queries within a reasonable latency limit.
Functional programming primitives
Dragon supports 20 or so easy-to-use functional programming primitives to express filtering/ordering on edges in the graph, as well as a single graph navigation primitive called assoc.
(->> ($alice) (assoc $friends) (assoc $friends) (filter (> age 20)) (count))
Example 1: Compute the number of Alice’s friends of friends over the age of 20.
(->> ($me) (assoc $groups)
(->> (assoc $members) (count))
(orderby (count))
(limit $count $offset))
Example 2: Compute all my subscribed groups, order by member count, and paginate through it.
Dragon supports user-defined functions (UDFs) in Lua/JavaScript if there is a need to do more complex string manipulation or a need for regular expression support.
Summary
Dragon is backed by a demand-filled, in-process key-value store, updated in real time and eventually consistent. It uses a number of optimization techniques to conserve storage, improve locality, and execute queries in 1 ms or 2 ms with high availability and consistency.
Even though some of the ideas have been around for a while, Dragon combines them at scale and in novel ways to push down many complex queries closer to storage. It’s structured more as a distributed database engine that retrieves the requested results as efficiently as possible along with any ranking signals stored in the index. This allows applications to focus on business logic, privacy, static type checking, and sophisticated ranking systems instead of spending a lot of time worrying about the best way to retrieve graph data.
Thank you to the Dragon and Social Hash teams for their contributions.








