
Messages have been part of Facebook for many years, beginning as direct messaging similar to email (available in your inbox the next time you visited the site) and then eventually evolving into a real-time messaging platform that provides access to your messages on a number of mobile apps or in a browser. But until recently the back-end systems hadn’t evolved much from early iterations, and Messenger’s performance and data usage started to lag behind — especially on networks with costly data plans and limited bandwidth. To fix this, we needed to completely re-imagine how data is synchronized to the device and change how data is processed in the back end to support our new synchronization protocol.
The version of Messenger we released at the end of last year was the first taste of a “mobile first” experience for Facebook Messenger. For the past year, while our app developer teammates have been improving the UI and expanding Messenger’s feature set, the Messaging infrastructure team has been working to make the platform more reliable on the back end and use less data. As a result, we created a new Messenger sync protocol that decreased non-media data usage by 40% and developed a new service called Iris to power it. By reducing congestion on the network, we’ve seen an approximately 20% decrease in the number of people who experience errors when trying to send a message.
The clients
The original protocol for getting data down to Messenger apps was pull-based. When receiving a message, the app first received a lightweight push notification indicating new data was available. This triggered the app to send the server a complicated HTTPS query and receive a very large JSON response with the updated conversation view.
Instead of this model, we decided to move to a push-based snapshot + delta model. In this model, the client retrieves an initial snapshot of their messages (typically the only HTTPS pull ever made) and then subscribes to delta updates, which are immediately pushed to the app through MQTT (a low-power, low-bandwidth protocol) as messages are received. When the client is pushed an update, it simply applies them to its local copy of the snapshot. As a result, without ever making an HTTPS request, the app can quickly display an up-to-date view.
We further optimized this flow by moving away from JSON encoding for the messages and delta updates. JSON is great if you need a flexible, human-readable format for transferring data without a lot of developer overhead. However, JSON is not very efficient on the wire. Compression helps some, but it doesn’t entirely compensate for the inherent inefficiencies of JSON’s wire format. We evaluated several possibilities for replacing JSON and ultimately decided to use Thrift. Switching to Thrift from JSON allowed us to reduce our payload size on the wire by roughly 50%.
The server
Messaging data has traditionally been stored on spinning disks. In the pull-based model, we’d write to disk before sending a trigger to Messenger to read from disk. Thus, this giant storage tier would serve real-time message data as well as the full conversation history. One large storage tier doesn’t scale well to synchronize recent messages to the app in real time. So in order to support this new, faster sync protocol and maintain consistency between the Messenger app and long-term storage, we need to be able to stream the same sequence of updates in real time to Messenger and to the storage tier in parallel on a per user basis.
Iris is a totally ordered queue of messaging updates (new messages, state change for messages read, etc.) with separate pointers into the queue indicating the last update sent to your Messenger app and the traditional storage tier. When successfully sending a message to disk or to your phone, the corresponding pointer is advanced. When your phone is offline, or there is a disk outage, the pointer stays in place while new messages can still be enqueued and other pointers advanced. As a result, long disk write latencies don’t hinder Messenger’s real-time communication, and we can keep Messenger and the traditional storage tier in sync at independent rates.
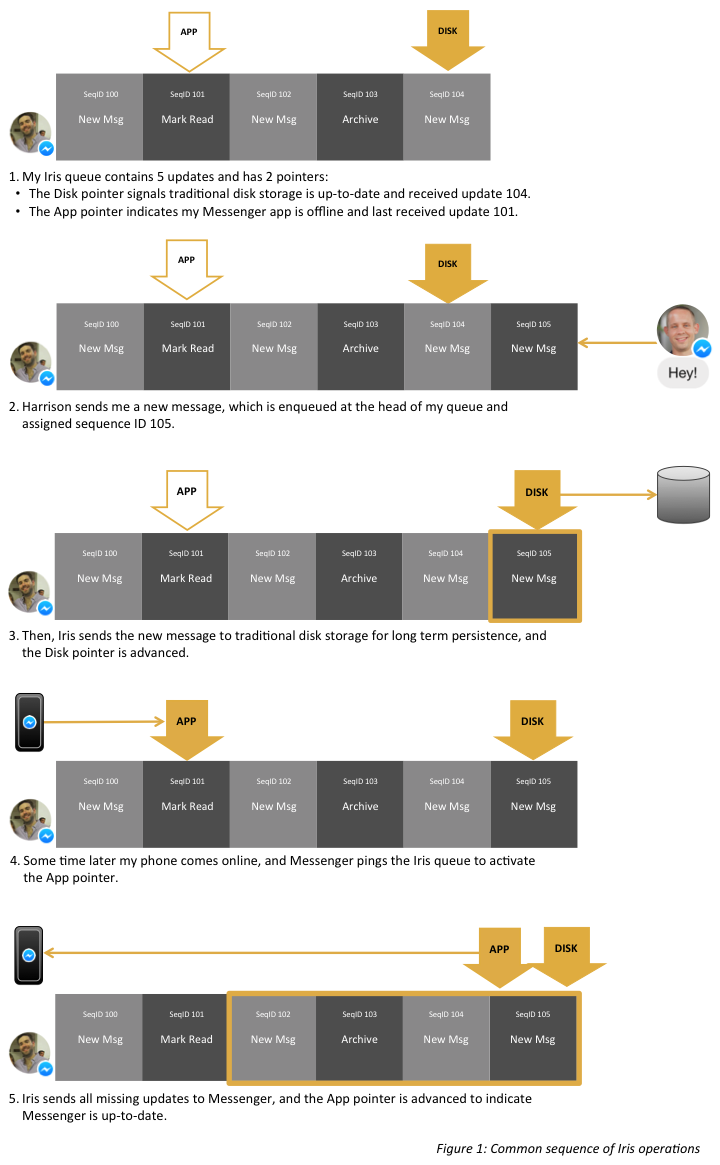
Effectively, this queue allows a tiered storage model based on recency:
- The most recent messages are immediately sent to online apps and to the disk storage tier from Iris’s memory
- A week’s worth of messages are served by the queue’s backing store in the case of disk outage or the Messenger app being offline for a while
- Older conversation history and full inbox snapshot fetches are served from the traditional disk storage tier
We looked at several existing technologies to support the queue’s backing store, but couldn’t find anything that met our needs in terms of scale, reliability, speed, and flexibility. Ultimately, we opted to build the queue storage on top of MySQL and flash. For MySQL we decided to use semi-sync replication, which can give you durability across multiple servers. By leveraging this technology, we can handle database hardware failures in under 30 seconds, and the latency for enqueueing a new message is an order of magnitude less than writing to the traditional disk storage. Since we enqueue a message once to MySQL and then push it to apps and disk in parallel, Messenger receives messages faster and more reliably.[1]
Results
The benefits of this new infrastructure are quite remarkable. The new sync protocol reduces Messenger’s non-media data usage by about 40%. Additionally, reducing congestion on the network leads to roughly a 20% decrease in the number of people who experience errors when trying to send a message.
Lessons learned
When building a high-quality real-time mobile application, it’s important to remember that the network is a scarce resource that must be used as efficiently as possible. Every byte wasted has a very real impact on the experience of the application. By sending less data and reducing HTTPS fetches, apps receive updates with lower latency and higher reliability. Extending desktop-focused infrastructure for a mobile world could work well, but building new mobile first infrastructure with protocols designed for pushable devices offers even better experiences.
Footnotes
[1] For more information on the improvements required in MySQL availability and performance to have it serve this new protocol, please see Harrison Fisk’s presentation at the @Scale 2014 conference.
Thanks to all the engineers who have contributed to this project, including Andrew Lutsenko, Andy Chen, Brian Tang, Changle Wang, Domas Mituzas, Harrison Fisk, Jeff Ferland, Olivia Bishop, Pierre-Luc Bertrand, Sachin Kulkarni, Thomas Georgiou, and Ting Yang.








