
The Hadoop Distributed Filesystem (HDFS) forms the basis of many large-scale storage systems at Facebook and throughout the world. Our Hadoop clusters include the largest single HDFS cluster that we know of, with more than 100 PB physical disk space in a single HDFS filesystem. Optimizing HDFS is crucial to ensuring that our systems stay efficient and reliable for users and applications on Facebook.
How the HDFS Namenode works
HDFS clients perform filesystem metadata operations through a single server known as the Namenode, and send and retrieve filesystem data by communicating with a pool of Datanodes. Data is replicated on multiple datanodes, so the loss of a single Datanode should never be fatal to the cluster or cause data loss.
But the loss of the Namenode cannot be tolerated. All metadata operations go through the Namenode, so if the Namenode is unavailable, no clients can read from or write to HDFS. Clients can still read individual data blocks from Datanodes if the Namenode is down, but for all intents and purposes, if the Namenode is unavailable, HDFS is down, and users and applications that depend on HDFS won’t be able to function properly.
The HDFS Namenode is a single point of failure (SPOF)
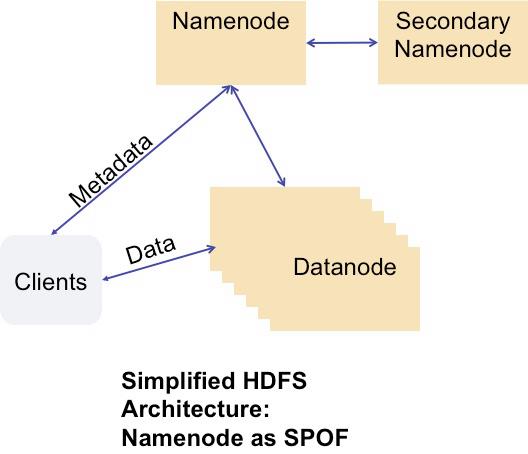
At Facebook, we wanted to know the extent of the “Namenode-as-SPOF” problem and build a system that would allow us to get past the limitations of the Namenode as a SPOF. Keep the picture above in mind–we’ll get back to it. But before we do, let’s talk a bit about HDFS usage at Facebook, to give you more context about what we’ve been working on and what problems we’ve been facing.
The Data Warehouse use case
At Facebook, one of largest deployments of HDFS is in our Data Warehouse. The Data Warehouse use case is a traditional HadoopMapReduce workload: a small number of very large clusters running MapReduce batch jobs. The load on the Namenode is very heavy because the clusters are very large, and both clients and Datanodes send a very high amount of metadata traffic to the Namenode. In a Data Warehouse cluster, it is not uncommon for the Namenode to be under heavy CPU, memory, disk and network pressure. When we cataloged Data Warehouse failures, we found that HDFS caused 41% of incidents.

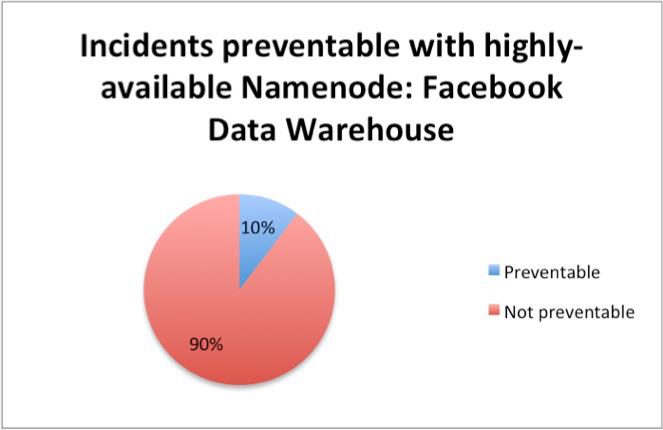
The HDFS Namenode, while a major component of HDFS, is a small but significant part of our overall Data Warehouse. While only 10% of the overall Warehouse issues and unplanned downtime would have been preventable if we had some kind of a highly-available Namenode, eliminating the Namenode as a SPOF is still a huge win because it allows us to perform scheduled maintenance on hardware and software. In fact, we estimate that it would eliminate 50% of our planned downtime, time in which the cluster would be unavailable.
So what would a High Availability Namenode look like, and how would it work? Let’s look at a new diagram, showing a highly available Namenode:
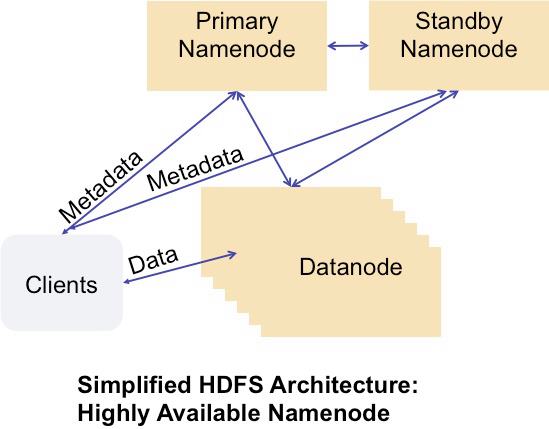
In this configuration, clients could talk to either a Primary or Standby Namenode. Likewise, Datanodes would be able to send block reports to either Primary or Standby Namenode. That’s essentially what we’ve done with Avatarnode, our solution to a highly available Namenode.
Avatarnode: A working solution for Namenode failover
To address the architectural shortcomings of the single Namenode, almost two years ago we began work at Facebook on the Avatarnode. The Avatarnode, which Facebook has contributed back to the community as open source, offers a highly-available Namenode with hot failover and failback. After countless hours of testing and bug-fixing, the Avatarnode is now in production at Facebook running our largest Hadoop Data Warehouse clusters thanks in large part to Dmytro Molkov.
The Avatarnode is a two-node, highly available Namenode with manual failover. Avatarnode works by wrapping the existing Namenode code in a Zookeeper layer. The fundamental concepts in Avatarnode are:
- There is a Primary and a Standby Avatarnode. Either Avatarnode can adopt either the Primary or the Standby “Avatar.”
- The host name of the current master is kept in Zookeeper
- A modified Datanode sends block reports to both the Primary and the Standby.
- A modified HDFS client checks Zookeeper before beginning each transaction, and again in the middle of a transaction if one fails. This allows writes to complete even if a Avatarnode failover takes place in the middle of a write.
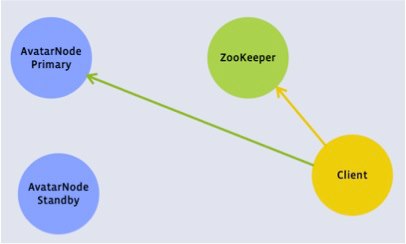
Avatarnode client view
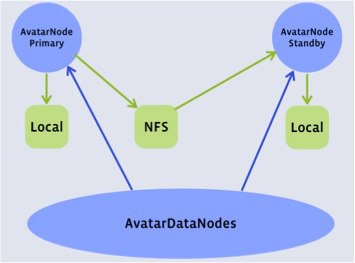
Avatarnode datanode view
For those curious about the name, Dhruba Borthakur, one of our HDFS developers, came up with it around the time the James Cameron film “Avatar” came out (I suppose we should be glad it was not 1998, or we could have had “Titanicnode”).
The Avatarnode is running our most demanding production workloads inside of Facebook today, and will continue to lead to substantial improvements in reliability and administration of HDFS clusters. Moving forward, we’re working to improve Avatarnode further and integrate it with a general high-availability framework that will permit unattended, automated, and safe failover.
Whether your system has hundreds of nodes or thousands, HDFS is the most scalable and most reliable open-source distributed filesystem available. The failure data we collected is representative of a wide variety of use cases, and we’ve open sourced Avatarnode as one of our best solutions to Namenode as SPOF. Because of work done by the Hadoop community, and the companies that support Hadoop contributors, all HDFS users and administrators can benefit from these efforts. You can check out Facebook’s release of Hadoop, which includes Avatarnode, on GitHub.
Andrew Ryan has been working with Hadoop at Facebook since 2009. During that time he’s helped grow our Hadoop and HDFS infrastructure from a single 600TB cluster in one datacenter to over 100 HDFS clusters in many datacenters.








