
Facebook and CNN joined forces to cover Barack Obama’s inauguration, and more recently, President Obama’s State of the Nation address. CNN provided the coverage, and Facebook provided a live feed allowing viewers to see in real time the reactions of friends and others watching. With such a historic event, the numbers were off the charts. Two million statuses were posted, with well over a million concurrent users at peak, and millions more participating throughout the day. The condensed usage meant more server load than we’d handled before. The status feed would automatically and constantly refresh, so you’d see new statuses and comments loaded immediately, as soon as they were posted. We also expected, and got, millions of concurrent users. This meant careful planning as to how we’d handle such a high request rate. We’re writing this blog post to share some of the problems we ran into and some of the tricks and strategies we used to deal with it all.
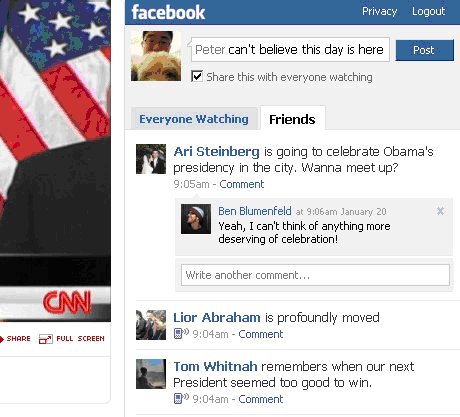
We served two types of requests from our backend corresponding to the two tabs we showed, with each request posing its own challenges. “Friends” tab requests were unique to each user, which meant they’d need to be dynamically generated on the fly for each user. “Everyone” tab requests were for shared content, which meant we could more aggressively cache a global feed rather than generating a response for each user. The rate of status updates for this tab however, was much much higher since it included everyone on CNN rather than just your friends. This meant we’d need to prepare for far higher cost in terms of rendering, cache usage, and downstream throughput than what we see from usage of the traditional feed on your home page. We served the “friends” request from our existing feed backend, which is designed to dynamically generate an up-to-the-second set of stories and comments.
One advantage we had here was that the periodic requests to get new statuses would commonly return an empty set since the rate of updates was much lower for friends than global feed. This allowed us to seriously optimize these requests to avoid much of the PHP initialization we normally do. If no new statuses were returned, we’d only load the bare essentials, making the request lighter on our web tier. This was the common case. Only when new statuses were available did we do the extra PHP includes needed for story construction and rendering. We similarly optimized the feed backend. Less statuses returned meant less processing to compute the response and less serialization since responses were smaller. This allowed us to handle many times the request rate on the backend than we do for traditional feed requests.
One interesting outcome we actually didn’t anticipate in our back-of-the-envelope calculations: users switching back and forth between tabs like maniacal channel surfers. When a user does this, we’d re-request the full set of 30 statuses. A mental note for the future is to also cache the bulk of these requests too. Live and learn. For “everyone” requests, we cached at several layers. A background script loaded statuses from the feed backend into memcache every few seconds. Requests then needed only hit a replicated memcache key to get the latest statuses. This obviously greatly reduced load on the expensive feed backend. Another method we employed to significantly reduce load and downstream traffic from our datacenters was to serve all “everyone” updates through our CDN. Traditionally CDNs are used for static content, but here since the data was public we used it for dynamic content by setting a short invalidation interval. The first time a user requested a batch of statuses, the CDN would request them from our backend with the same parameters and then cache the results. Though requesting via a CDN promised to be a huge performance win, it also introduced some issues that wouldn’t occur without caching. We use the maximum timestamp of the stories returned to determine what stories we request next. With caching, if there was a period with no new stories, the result would be cached forever and the user would make the same request with the same results in an infinite loop.
Another issue with CDN caching was that users could also theoretically get behind. For obvious reasons we couldn’t rely on the client’s clock. Since you could think of the CDN cached entries as a linked list with each entry tied to a time, a user whose browser was slow for one reason or another might not keep up with real time while traversing the “list”. We had to anticipate and devise strategies to work around several of these issues introduced by CDN caching. Designing all of this was one thing, making sure it worked at the scale we expected was another. Unlike most projects at Facebook, we couldn’t roll this out slowly to test for load issues. Further, we only had a couple hour window where peak performance was paramount. Given the huge turnout we expected, we had to make sure we could handle millions of concurrent users, and being Facebook, we were going to be over-prepared. We came up with conservative numbers for how many concurrent users we’d need to handle, made estimates for usage patterns, and designed dozens of levers and fallbacks in case the numbers came in even higher (or if things went wrong). The number of stories returned, the frequency of refreshes, and how many stories would be checked for new comments were just some of the thirty levers we had in place to react to capacity issues.
The bread and butter of our preparation was load testing. We “dark” launched the client a couple weeks before the inauguration, which meant deploying some Javascript code that would get executed transparently on users’ home.php. The code would make requests to our backend periodically, exercising our entire stack, including client, front end, and backend code. We could throttle the dark launch up and down to simulate different request rates and types and test various contingency mechanisms and failover levers we had in place. This was about as realistic a test as we could achieve, and allowed us to ferret out bugs and infrastructure and performance issues well before inauguration day. We also collected client stats, periodically sending them upstream to ensure clients were seeing what we’d expect (especially since much of the results were from the CDN’s cache and therefore invisible to us). In the end, thanks to several weeks of testing, we were able to make it smoothly through peak load without a hitch and not one feature being degraded. We hope you guys enjoyed using it as much as we enjoyed building it. Stay tuned for similar efforts in the future!








