This post discusses enhancements to our database backups. As we deploy these enhancements to production servers, we may write additional posts about other improvements made along the way.
This post discusses enhancements to our database backups. As we deploy these enhancements to production servers, we may write additional posts about other improvements made along the way.
Facebook users create a vast amount of data every day. To make sure that data is stored reliably, we back up our databases daily. We’re improving our backup system by moving from a logical to a custom physical backup model that increases the speed of backups significantly without increasing their size.
Moving from mysqldump to XtraBackup
We currently use mysqldump to perform daily database backups. mysqldump does a logical backup of the data, reading from each table using SQL statements then exporting the data into text files. The main drawbacks of mysqldump are that it is very slow (taking more than 24 hours to back up some of our hosts with larger databases) and that the SQL statements it uses cause random disk reads when the tables are fragmented, which increases load on the database server. We can run multiple instances of mysqldump concurrently to finish the backup in less time but that puts additional load on the server and is not desirable.
An alternative backup solution is to do a physical backup (we call this a binary backup), which reads the database files using the file system interface rather than SQL statements. Note that the files may not be transactionally consistent at the time of the copy. Making them consistent is deferred until a database is restored from the backup. Making it consistent is similar to what happens when a database server restarts from an abrupt shutdown, like when a power failure occurs while the server is busy.
We enhanced XtraBackup from Percona to meet our additional requirements:
- Support fast table-level restore
- Enhance full and incremental backups
- Support hybrid incremental backup
XtraBackup supports incremental backup where it only backs up data that changed after the last full backup. We can reduce the amount of backup space required by doing daily incremental backups and weekly full backups. XtraBackup can also do incremental on top of incremental backups, but we decided against them to avoid dealing with restore chain lengths of size greater than 2.
Table Level Restore
We created a PHP script that can restore a table under the same or different name, given the location of full and incremental binary backups. Currently, the script cannot construct the table schema from the backup, so it expects an empty table to exist with the proper table schema. Changes were made to XtraBackup to support the tool. The changes build on support in XtraBackup for exporting and importing tables. Table level restore is much faster than a full database restore as it only need to read log files and files for the table to be restored.
Tweaking Full and Incremental Backups
Facebook was an early adopter of incremental backup in XtraBackup. Initially it didn’t work on our databases that have both a large number of tables and a few large tables. We worked with Percona to fix these issues.
XtraBackup had local incremental backup functionality only, where the incremental backup is stored on the same host as the MySQL server. We enhanced it to support remote incremental backup by streaming the table deltas to the remote host. Note that doing a local incremental backup first and then copying it over to the remote host was not acceptable to us as it significantly increases writes on the local host.
XtraBackup reads from the database file in 1MB chunks. We found that using an 8MB IO size doubles the speed of incremental backups and makes full backups 40% faster.
Making Incremental Backups “Really” Incremental
XtraBackup’s incremental backup reads every database page to figure out which pages changed and writes the changed pages. We built a page tracker that reads transaction logs and tracks the modified pages using one bitmap per table. We then enhanced incremental backup to use the page tracker to avoid reading pages that didn’t change. We named this enhanced backup method really incremental.
Ironically, we found that really incremental backups were actually slower than incremental backups. This is because incremental backups always read the files using an 8MB IO size while really incremental backups read the files using variable IO sizes, anywhere from 16KB (one page size of InnoDB) to 8MB, depending upon how many consecutive pages were actually updated. So really incremental backups were effectively making many more IO calls than incremental backups in our environment, where 10-30% of pages are modified since the last full backup.
So we developed a hybrid incremental approach that tries to reduce IO calls while avoiding reading unmodified pages. For our workload the hybrid incremental approach makes 20-30% less IO calls than an incremental backup, with IO sizes ranging from 16KB to 8MB.
Net Impact
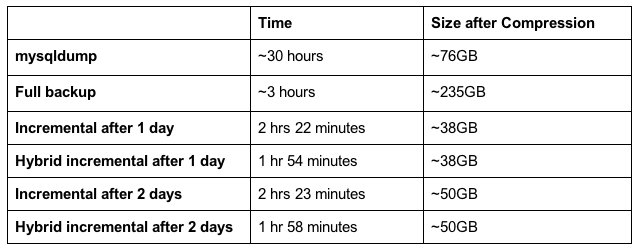
The table below describes the impact of these improvements with ~750GB data, split across multiple databases of almost the same size. Because it is slow, mysqldump was only run on a few databases and the results were extrapolated. We use gzip compression for mysqldump which is slow but achieves a great compression ratio.
QPress is used for binary backups. It is much faster than gzip but has a lower compression ratio. By doing daily incremental backups regularly and less frequent full backups, the total space requirement for binary backups is similar to that for mysqldump.