
What the research is:
We’ve built a data classification system that uses multiple data signals, a scalable system architecture, and machine learning to detect semantic types within Facebook at scale. This is important in situations where it’s necessary to detect where an organization’s data is stored in many different formats across various data stores. In these cases, a classification system enables organizations to automatically enforce privacy- and security-related policies, such as access control policies. Our new system scales to both persistent and nonpersistent user data, with no additional constraints on the type or format of data.
Traditional data loss prevention (DLP) systems solve this problem by fingerprinting the data in question and monitoring endpoints for the fingerprinted data. For an organization with a large number of constantly changing data assets, this approach is neither scalable nor effective for discovering which data is where. Instead, the approach described here focuses on scalable infrastructure, multiple data signals, machine learning (ML), and continuous training to solve this challenge.
How it works:
Data often flows through an organization in two ways, so we need two different strategies to detect and classify this data for automated policy enforcement:
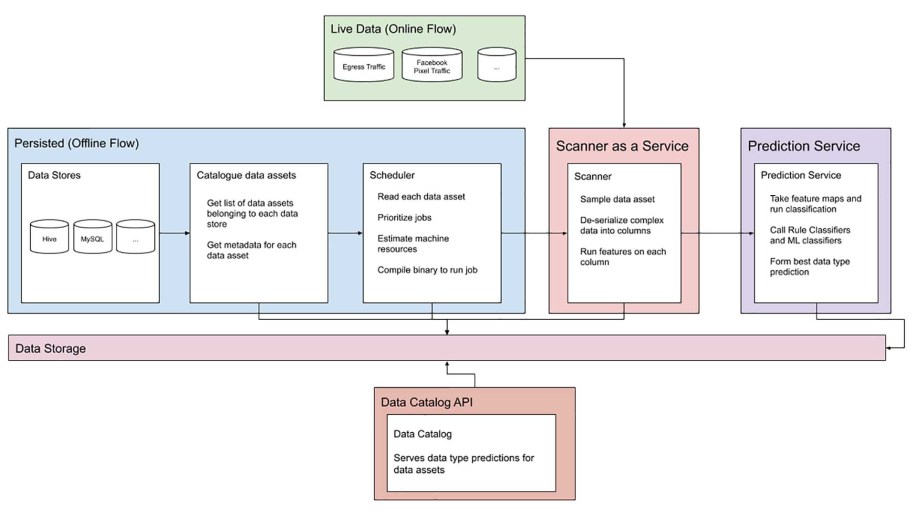
Persisted data: For data persisted in offline data stores, our system must first learn about the universe of data assets. The system collects basic metadata for each data store to form a catalog to efficiently retrieve data without overloading clients and other resources used by developers. It reads from our asset metadata, estimates the resources needed to scan each asset, and invokes a job to perform the actual scanning of the asset.
Each job is a compiled binary that performs a Bernoulli sample on the latest data available. These samples are broken down into individual columns, and features are extracted from each column. The prediction service ingests these features and invokes rule-based and machine learning classification to predict data label(s) for each column. Any downstream processes can either read these predictions from data sets that aggregate all scan job results or from a real-time data catalog API.
Online data: While the above happens for persisted assets, nonpersisted traffic is part of an organization’s data and also needs to be protected. For this reason, the system provides an online API for generating real-time classification predictions for nonpersisted traffic. This live prediction system is heavily used to classify egress traffic, incoming traffic to ML models, and any real-time data.
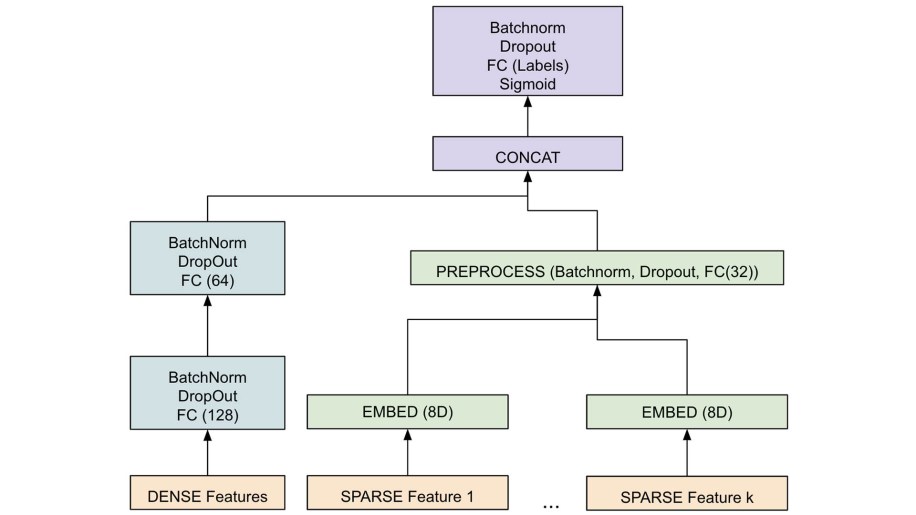
Heuristic rules and ML: Using manual heuristics exclusively results in subpar classification accuracy, especially for unstructured data. For this reason, we also built an ML system to deal with classification of unstructured data, such as user-generated content. A modularized PyTorch-based model allows us to quickly and independently change parts of the model — without hurting overall performance.
Why it matters:
Organizations generally have a well-defined set of privacy policies aimed at ensuring that people’s privacy is respected. Given these privacy expectations, it is important that organizations have visibility into which metadata is associated with a given piece of information. This visibility allows them to work quickly and make fewer mistakes by providing information to back any given decision.
Our system provides data type classifications for all data assets across dozens of data sources, which allows us to build enforcement systems to ensure that privacy and security policies are followed. Unlike traditional DLP-like systems with fingerprinted data, the design of our classification system provides the flexibility to easily add detection for additional data types while providing classification results with low latency on a tight memory constraint.
Looking ahead, we are working on support for unschematized data (files), classifying not only the data type but also the sensitivity level of data, and leveraging self-supervised learning for improving classification accuracy of data classes with few manual labels.








