
As our global community has grown to more than 2.2 billion people, Facebook’s infrastructure has grown to span News Feed, Messenger, Instagram, WhatsApp, Oculus, and a range of other products. These products and the systems powering them run on millions of servers spread across multiple geo-distributed data centers.
As our infrastructure has scaled, we’ve found that an increasing fraction of our machines and networks span multiple generations. One side effect of this multigenerational production environment is that a new software release or configuration change might result in a system running healthily on one machine but experiencing an out-of-memory (OOM) issue on another. Facebook runs Linux as the host operating system on its machines. The traditional Linux OOM killer works fine in some cases, but in others it kicks in too late, resulting in the system entering a livelock for an indeterminate period.
We have developed oomd, a faster, more reliable solution to common out-of-memory (OOM) situations, which works in userspace rather than kernelspace. We designed oomd with two key features: pre-OOM hooks and a custom plugin system. Pre-OOM hooks offer visibility into an OOM before the workload is threatened. The plugin system allows us to specify custom policies that can handle each workload running on a host.
We find that oomd can respond faster, is less rigid, and is more reliable than the traditional Linux kernel OOM killer. In practice, we have seen 30-minute livelocks completely disappear. We wish to contribute oomd to the open source community to help others find a more flexible solution for OOM situations.
A novel approach to OOMs
Memory overcommit, where more memory is allocated for processes than the total available system memory, is a common technique for increasing memory utilization. Memory overcommit is based on the assumption that not all assigned memory is needed by running applications. This assumption is not always true: When demand exceeds total available memory, the Linux OOM killer tries to reclaim memory. The Linux OOM killer’s primary responsibility is to protect the kernel so that the machine stays up; it accomplishes this by killing some processes without heed to the importance of a given workload. Hence, whenever the OOM killer engages, there is a significant risk that applications running on the machine will be affected.
We based our custom oomd solution on two key developments:
Pressure Stall Information: PSI is a new utility, currently pending upstream integration, developed by Facebook engineer Johannes Weiner. PSI tracks three major system resources — CPU, memory, and I/O — and provides a canonical view into how the usage of these resources changes over time. PSI provides quantifiable measurements of overall workload performance by reporting lost wall time due to resource shortages. When PSI is deployed in production, we find that its metrics act as a barometer of impending resource shortage, allowing userspace to take proactive steps as needed.
Cgroup2: This successor to cgroup is a Linux kernel mechanism that organizes processes hierarchically and distributes system resources along the hierarchy in a controlled and configurable manner. Oomd makes use of cgroup2’s sophisticated accounting mechanisms to ensure that each workload is behaving appropriately. For example, cgroup2 reports accurate resource consumption for each workload as well as process metadata. Cgroup2 also has a PSI interface that oomd uses.
Solving an old kernelspace problem in userspace
Oomd constantly monitors PSI metrics to assess whether a system is under unrecoverable load. PSI alone is insufficient, so oomd also monitors the system holistically. This is in contrast to Linux’s OOM killer, which focuses primarily on the kernel’s concerns. Since OOM detection criteria can vary depending on workload, the plugin system supports customization to both the detection and process kill strategies.
Thanks to this new ability to monitor key system resource indicators, oomd is able to take corrective action in userspace before a system-wide OOM occurs. Corrective action is configured via a flexible plugin system that is capable of executing custom code. Thus, in addition to oomd’s default process SIGKILL behavior, application developers can customize their plugin with alternate strategies, such as sending a “back off” RPC to the main workload or dumping system logs to a remote service.
Within oomd, we use a generic kill mechanism called the kill list, which is an ordered list of “known offenders” — processes or services that ought to be the first to kill in the event of an OOM, provided certain criteria are met. The currently supported criteria are (1) how much memory pressure the target is generating, and (2) how much total memory the target is consuming. For example, if a workload creates an auxiliary service that holds an in-memory cache for certain hot objects, oomd’s kill list can be configured to kill the cache first, provided the cache is above a certain memory size.
Synthetic test results
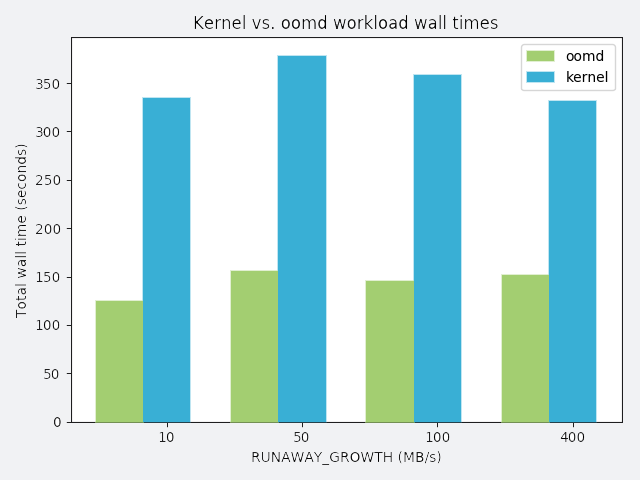
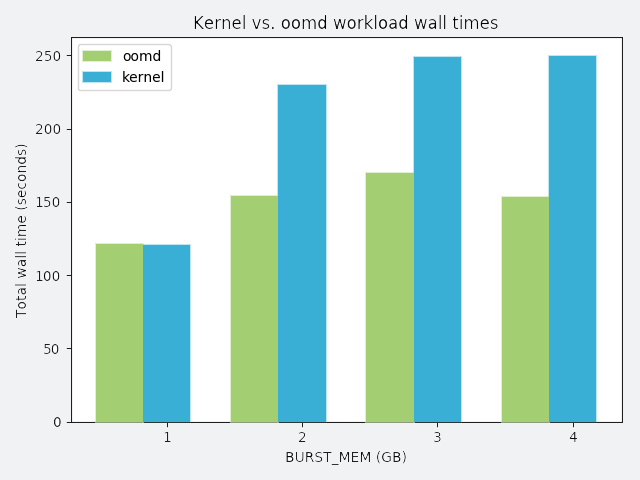
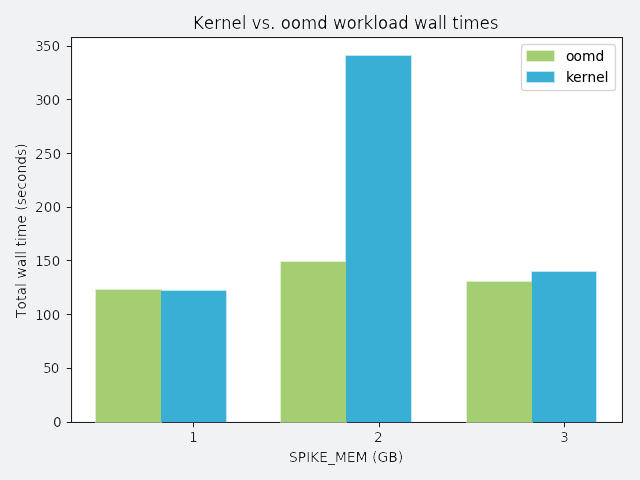
To demonstrate oomd’s effectiveness, we ran the following synthetic tests on a lab host. In each scenario, we ran all applications in an artificial cgroup, where maximum memory usage was constrained to 10 GB. The workload was a simulated application that requested 2 GB of memory allocated over 120 seconds. We considered the workload successful if it could allocate the entire 2 GB without being killed.
In the following graphs, the y-axis represents total wall time spent running the workload. Perfect performance implies 120 seconds of wall time. Anything greater than 120 seconds is considered degraded performance. Each workload competes with misbehaving processes, and each misbehaving process has a distinct misbehavior profile. The profile is described above each graph.
RUNAWAY_GROWTH: a process that slowly leaks memory
BURST_MEM: a process that repeatedly allocates a chunk of memory and frees it
SPIKE_MEM: a process that allocates a chunk of memory and sleeps
Conclusion
We describe oomd, a new userspace OOM killer that allows application developers to customize responses when a workload consumes all available system memory. Our tests demonstrate that oomd is a reliable and effective drop-in replacement to the default Linux kernel OOM killer. We have developed and deployed oomd in production at Facebook, and we’ve found that it has allowed us to decrease the frequency of livelocks on workloads ranging from build servers to rack switches to shared compute resources. We have open-sourced oomd so that the broader engineering community can benefit.
We would like to thank Thomas Connally for his contribution to this work.








