
UPDATE: To continue our support of this public NTP service, we have open-sourced our collection of NTP libraries on GitHub.
Almost all of the billions of devices connected to the internet have onboard clocks, which need to be accurate to properly perform their functions. Many clocks contain inaccurate internal oscillators, which can cause seconds of inaccuracy per day and need to be periodically corrected. Incorrect time can lead to issues, such as missing an important reminder or failing a spacecraft launch. Devices all over the world rely on Network Time Protocol (NTP) to stay synchronized to a more accurate clock over packet-switched, variable-latency data networks.
As Facebook’s infrastructure has grown, time precision in our systems has become more and more important. We need to know the accurate time difference between two random servers in a data center so that datastore writes don’t mix up the order of transactions. We need to sync all the servers across many data centers with sub-millisecond precision. For that we tested chrony, a modern NTP server implementation with interesting features. During testing, we found that chrony is significantly more accurate and scalable than the previously used service, ntpd, which made it an easy decision for us to replace ntpd in our infrastructure. Chrony also forms the foundation of our Facebook public NTP service, available from time.facebook.com. In this post, we will share our work to improve accuracy from 10 milliseconds to 100 microseconds and how we verified these results in our timing laboratory.
Leap second
Before we dive into the details of our NTP service, we need to look at a phenomenon called a leap second. Because of the Earth’s rotation irregularities, we occasionally need to add or remove a second from time, or a leap second. For humans, adding or removing a second creates an almost unnoticeable hiccup when watching a clock. Servers, however, can miss a ton of transactions or events or experience a serious software malfunction when they expect time to go forward continuously. One of the most popular approaches for addressing that is to “smear” the leap second, which means to change the time in very small increments across multiple hours.
Building an NTP service at scale
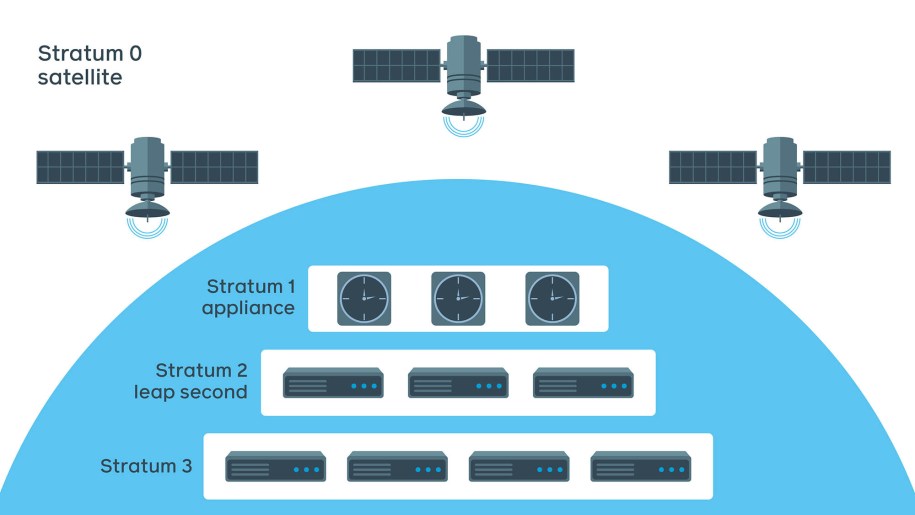
Facebook NTP service is designed in four layers, or strata:
- Stratum 0 is a layer of satellites with extremely precise atomic clocks from a global navigation satellite system (GNSS), such as GPS, GLONASS, or Galileo.
- Stratum 1 is Facebook atomic clock synchronizing with a GNSS.
- Stratum 2 is a pool of NTP servers synchronizing to Stratum 1 devices. Leap-second smearing is happening at this stage.
- Stratum 3 is a tier of servers configured for a larger scale. They receive smeared time and are ignorant of leap seconds.
There could be as many as 16 layers to distribute the load in some systems. The number of layers depends on the scale and precision requirements.
When we set out to build our NTP service, we tested the following time daemons to use:
- Ntpd: A common daemon, ntpd used to be included on most Unix-like operating systems. It has been a stable solution for many years and may be running on your computer right now.
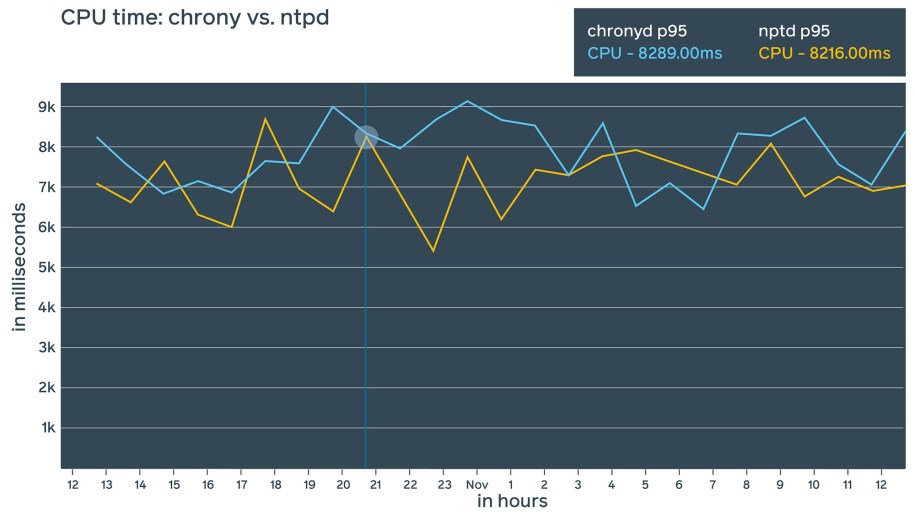
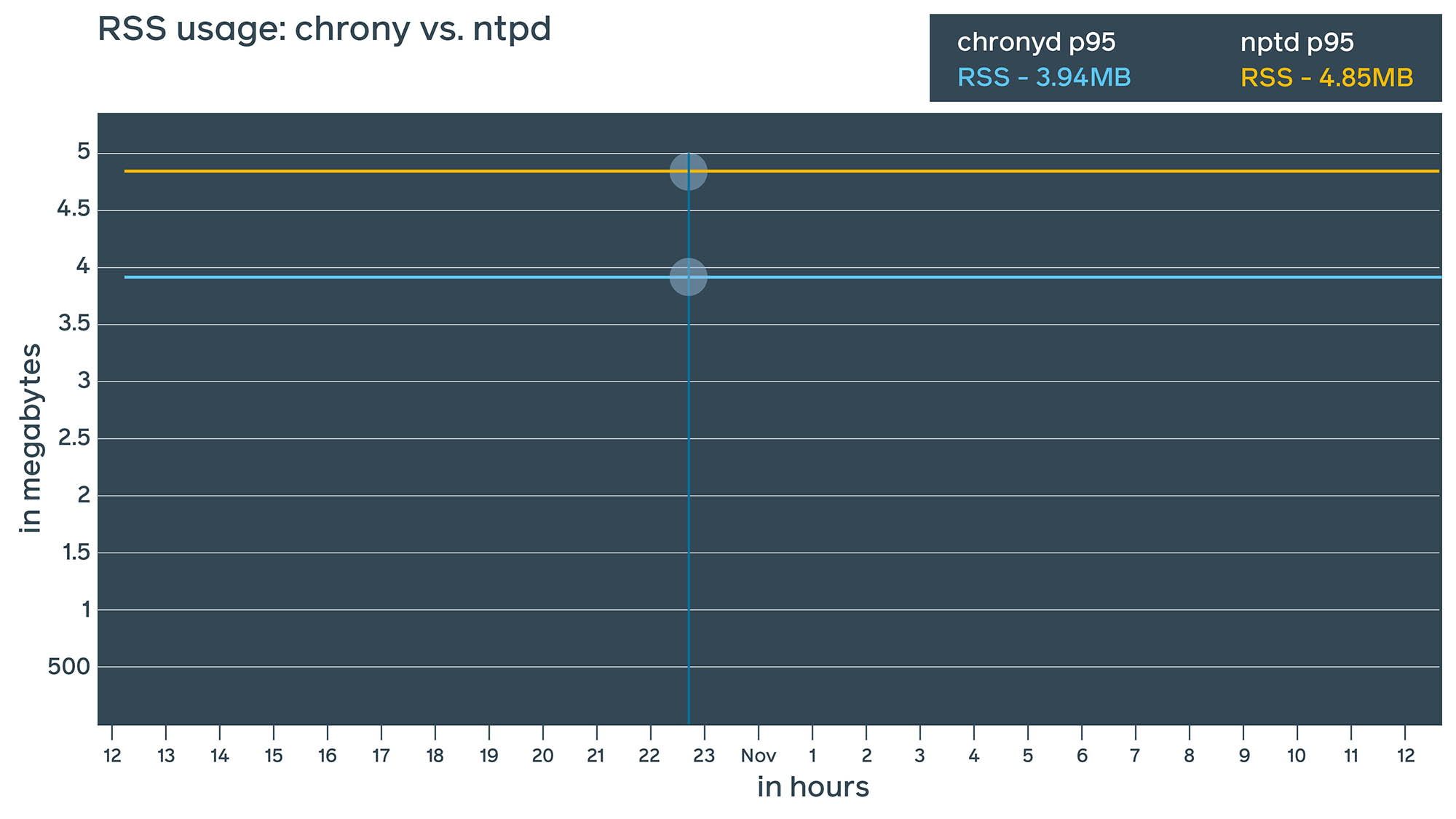
- Chrony: A fairly new daemon, chrony has interesting features and the potential to provide more precise time synchronization using NTP. Chrony also offers its own extended control protocol and theoretically could bring precision down to nanoseconds. From a resource consumption perspective, we found ntpd and chrony to be fairly similar, though chrony seems to consume slightly less RAM (~1 MiB difference).
Daemon estimates
Whether a system is using ntpd or chrony, each provides some estimated measurements. The daemon includes command line tools that display these estimates, as shown below. These estimates rely on many assumptions, such as:
- The network path between client and server is symmetric.
- When timestamps are added to the NTP packet and
send()is called, the operating system will dispatch it immediately. - Oscillator temperature and supplied voltage are constant.
Ntpd includes ntpq command line tool, which displays how out of sync it determines that time is:
[user@client ~]# ntpq -p
remote refid st t when poll reach delay offset jitter
=========================================================================
+server1 .FB. 2 u 406 1024 377 0.029 0.149 0.035
+server2 .FB. 2 u 548 1024 377 0.078 0.035 0.083
*server3 .FB. 2 u 460 1024 377 0.049 -0.185 0.114However, can we trust these numbers? If ntpd reports that the time is off by 0.185 ms, is that accurate? The short answer is no. Server estimates the offset based on multiple timestamps in a packet. And the actual values are supposed to be within a 10x bigger window. In other words, a result saying time is off by 0.185 ms means it’s probably within +/-2 ms (so, 4 ms in total). However, our testing demonstrated that accuracy is generally within 10 ms with ntpd.
We had technical requirements for better precision. For example, multi-master databases translate microseconds and even nanoseconds of precision directly into their theoretical throughput. Another example for which moderate precision is required is logging — in order to match logs between nodes of a distributed system, milliseconds of precision is often required.
Let’s see what happens if we replace ntpd with chrony:
[user@client ~]# chronyc sources -v
210 Number of sources = 19
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current synced, '+' = combined , '-' = not combined,
| / '?' = unreachable, 'x' = time may be in error, '~' = time too variable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^+ server1 2 6 377 2 +10us[ +10us] +/- 481us
^- server2 2 6 377 0 -4804us[-4804us] +/- 77ms
^* server3 2 6 377 59 -42us[ -46us] +/- 312us
^+ server4 3 6 377 60 +11ns[-3913ns] +/- 193us
Pay attention to those last three numbers. Backwards, from right to left:
- The very last number is the estimated error. It’s prefixed with +/-. This is how much chrony evaluates the maximum error. Sometimes it’s 10s of milliseconds, sometimes it’s 100s of microseconds (100x difference). This is because when chrony synchronizes with another chrony, it uses the extended NTP protocol, which dramatically increases precision. Not too bad!
- Next is the number in the square brackets. It shows the measured offset. We can see approximately 100x difference here as well, except for server4 (we will talk about this one later).
- The number to the left of the square brackets shows the original measurement, adjusted to allow for any slews applied to the local clock since that first measurement. Again, we can see 100x difference between ntpd and chrony.
Let’s see how it looks in the graph:
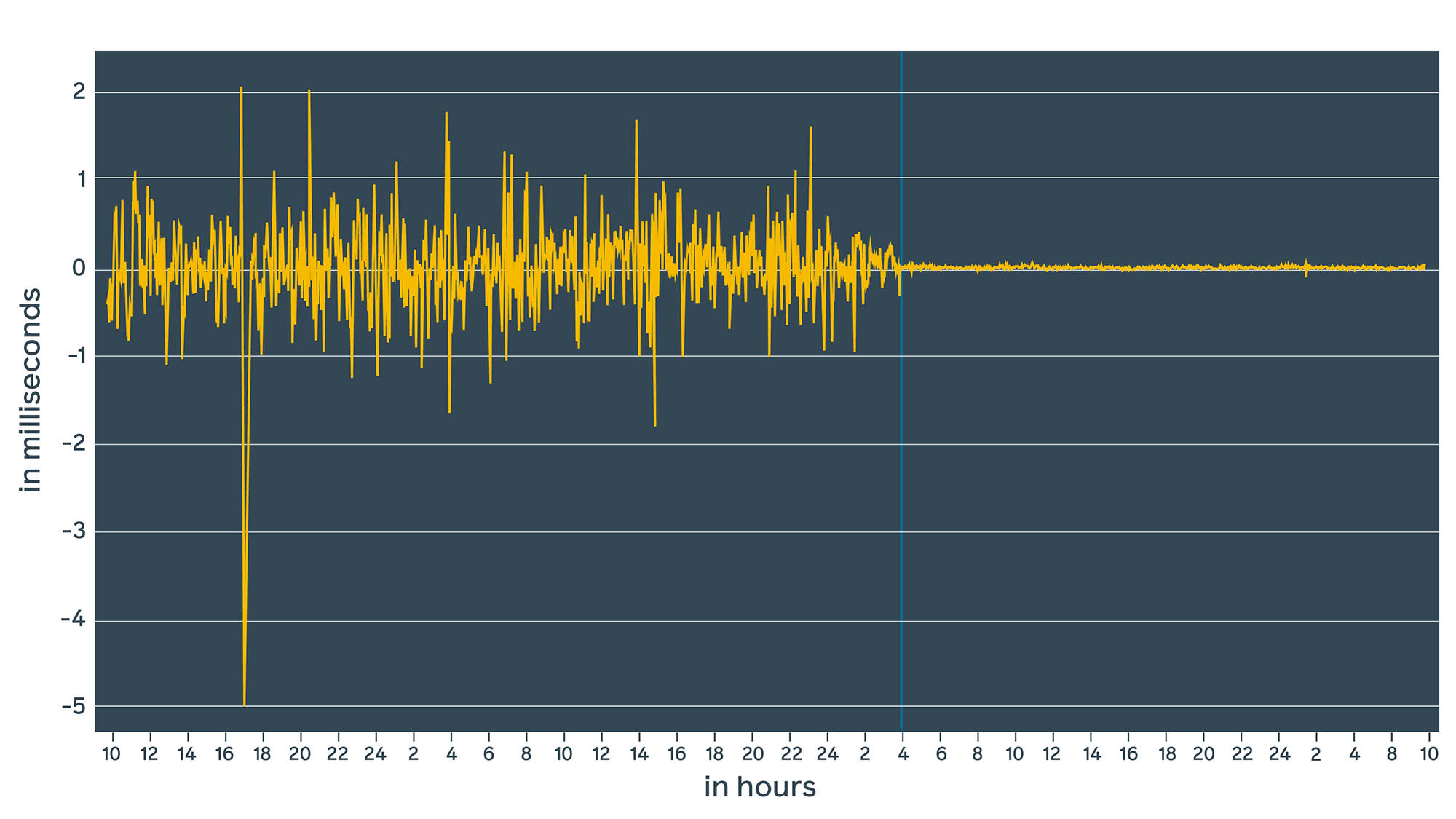
The vertical blue line represents the moment when ntpd was replaced with chrony. With ntpd, we were in the range of +/-1.5 ms. With chrony, we are in the range of microseconds. More importantly, estimated error (window) dropped to a range of 100s of microseconds, which we can confirm with lab measurements (more on this below). However, these values are estimated by daemons. In reality, the actual time delta might be completely different. How can we validate these numbers?
Pulse per second (1PPS)
We can extract an analog signal from the atomic clock (actually the internal timing circuitry from a Stratum 1 device). This signal is called 1PPS, which stands for 1 pulse per second; it generates a pulse over the coaxial cable at the beginning of every second. It is a popular and accurate method of synchronization. We can generate the same pulse from an NTP server and then compare to see how off the phases are. The challenge here is that not all servers support 1PPS, so this requires specialized network extension cards.
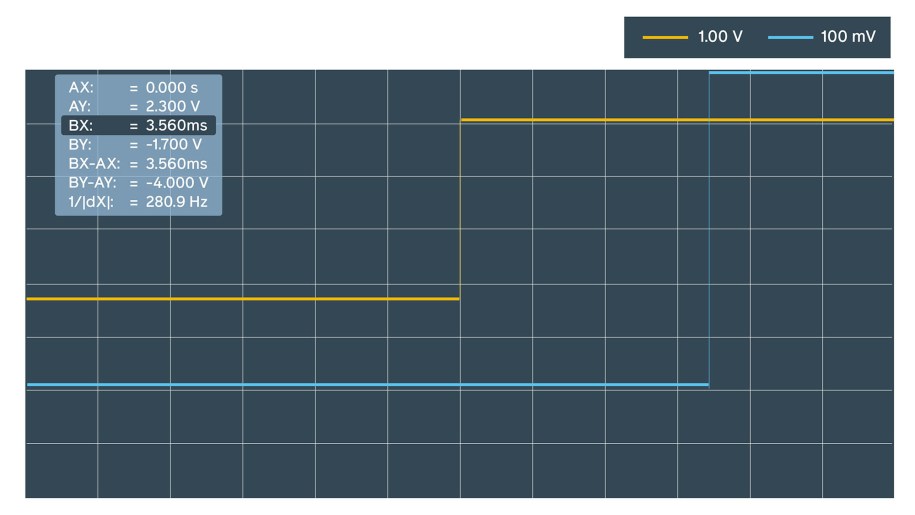
Our first attempt was pretty much manual. It involved an oscilloscope to display a phase shift.
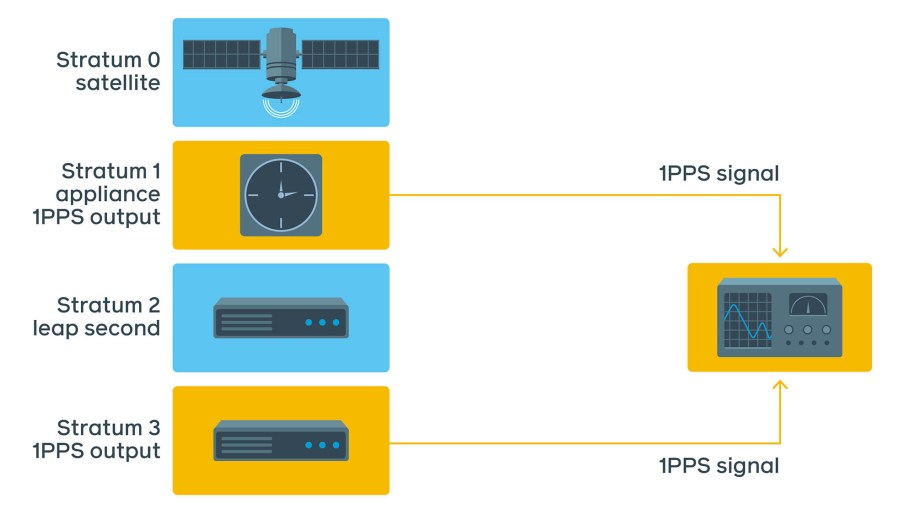
Within 10 minutes of measurements we estimated the offset to be approximately 3.5 ms for ntpd, sometimes jumping to 10 ms.
This test would be extremely hard and impractical to implement at Facebook scale. A better test involves connecting 1PPS output of the test server back into 1PPS input of the Stratum 1 device itself and monitoring the difference.
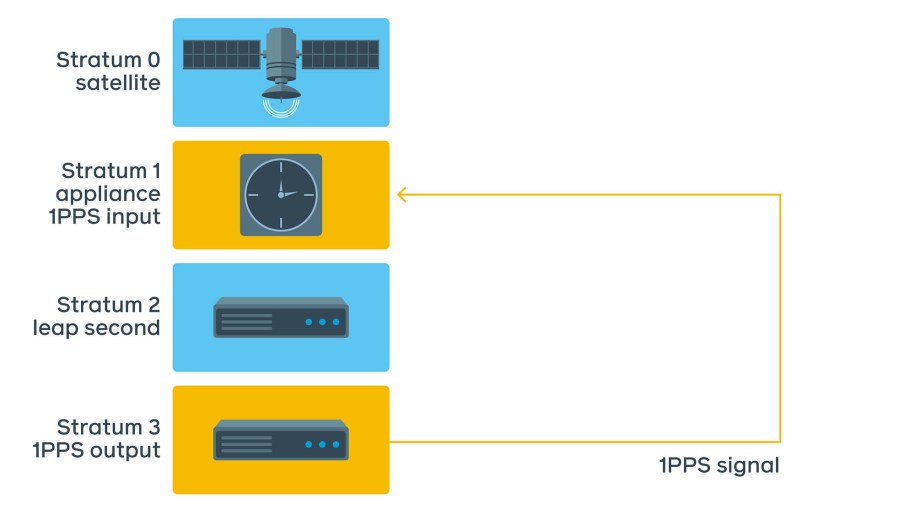
This method has all the upsides of the previous 1PPS measurements but without the downsides of operating an oscilloscope in a data center. As this test runs continuously, we are able to take measurements and verify the real NTP offset at any point in time.
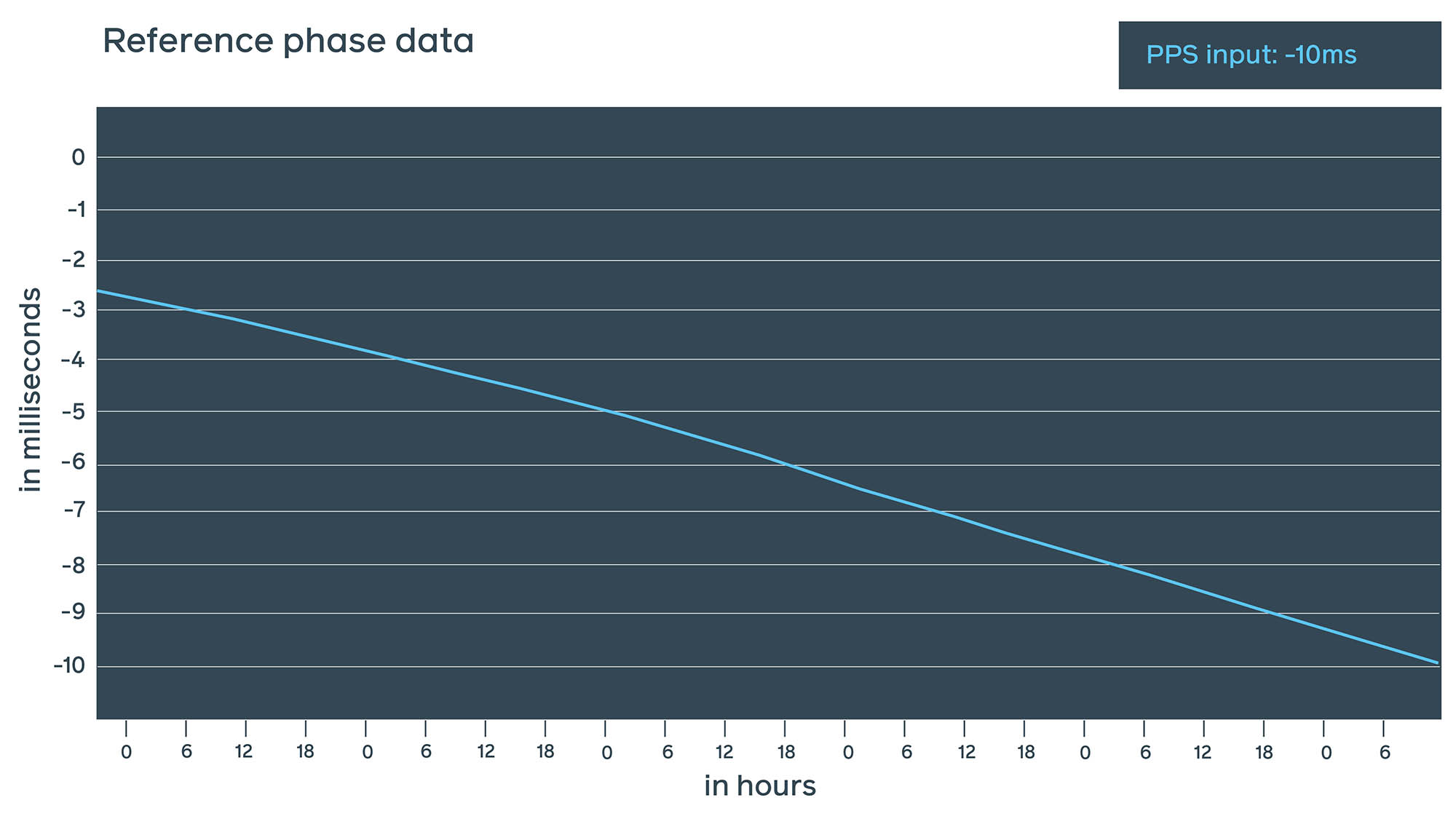
These two measurements give us a very good understanding of a real NTP offset with a very small estimated error by 1PPS in just nanoseconds, mostly added by the cable length.
The disadvantages of these methods are:
- Cabling: Coaxial cable is required for such measurements. Doing spot checks in different data centers requires changes in the data center design, which is challenging.
- Custom hardware: Not all network cards have 1PPS outputs. Tests like these require unique network cards and servers.
- Stratum 1 device with 1PPS input.
- 1PPS software on the server: To run the test, we had to install ntpd on our test server. This daemon adds extra error as it works in user space and is scheduled by Linux.
Dedicated testing device
There are devices on the market that can perform accuracy checks. They contain GNSS receivers, have an atomic clock, have multiple 1PPS and network interfaces, and also act as NTP clients. This allows us to perform the same checks using NTP protocol directly. The received NTP packet is recorded with a very accurate timestamp from the atomic clock/GNSS receiver.
Here is the typical setup:
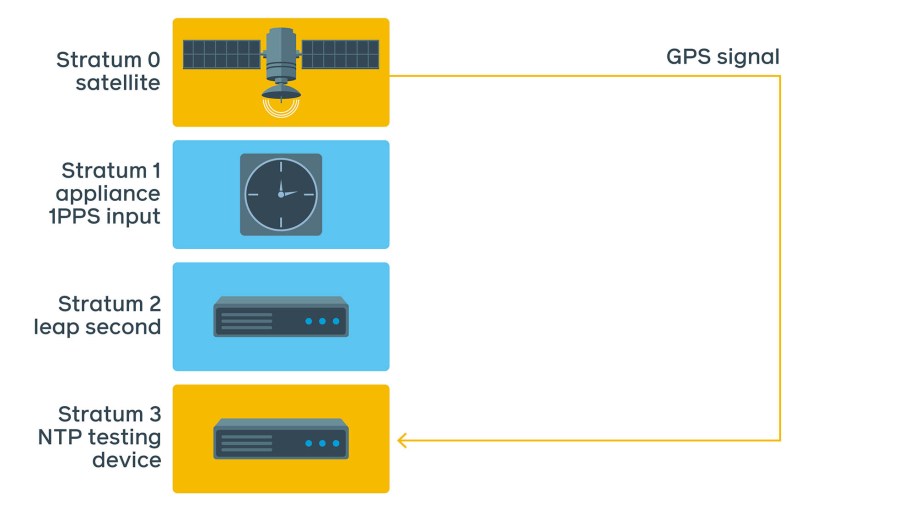

Our initial ad-hoc test setup is shown above. There are several advantages when measuring with this device:
- It does not require extra 1PPS cabling. We still need to discipline the atomic clock, but this can be done using GNSS or the Stratum 1 device itself and a short cable when in the same rack.
- It uses the atomic clock’s data to stamp transmitted and received network packets. This makes the operating system’s influence negligible, with the error rate in nanoseconds.
- It supports both NTP and PTP (Precision Time Protocol).
- The device is portable — we can move it between locations to perform spot checks.
- The device uses its own format for data points, but it can export data to CSV, which enables us to export data to our internal data standard.
NTPD measurements
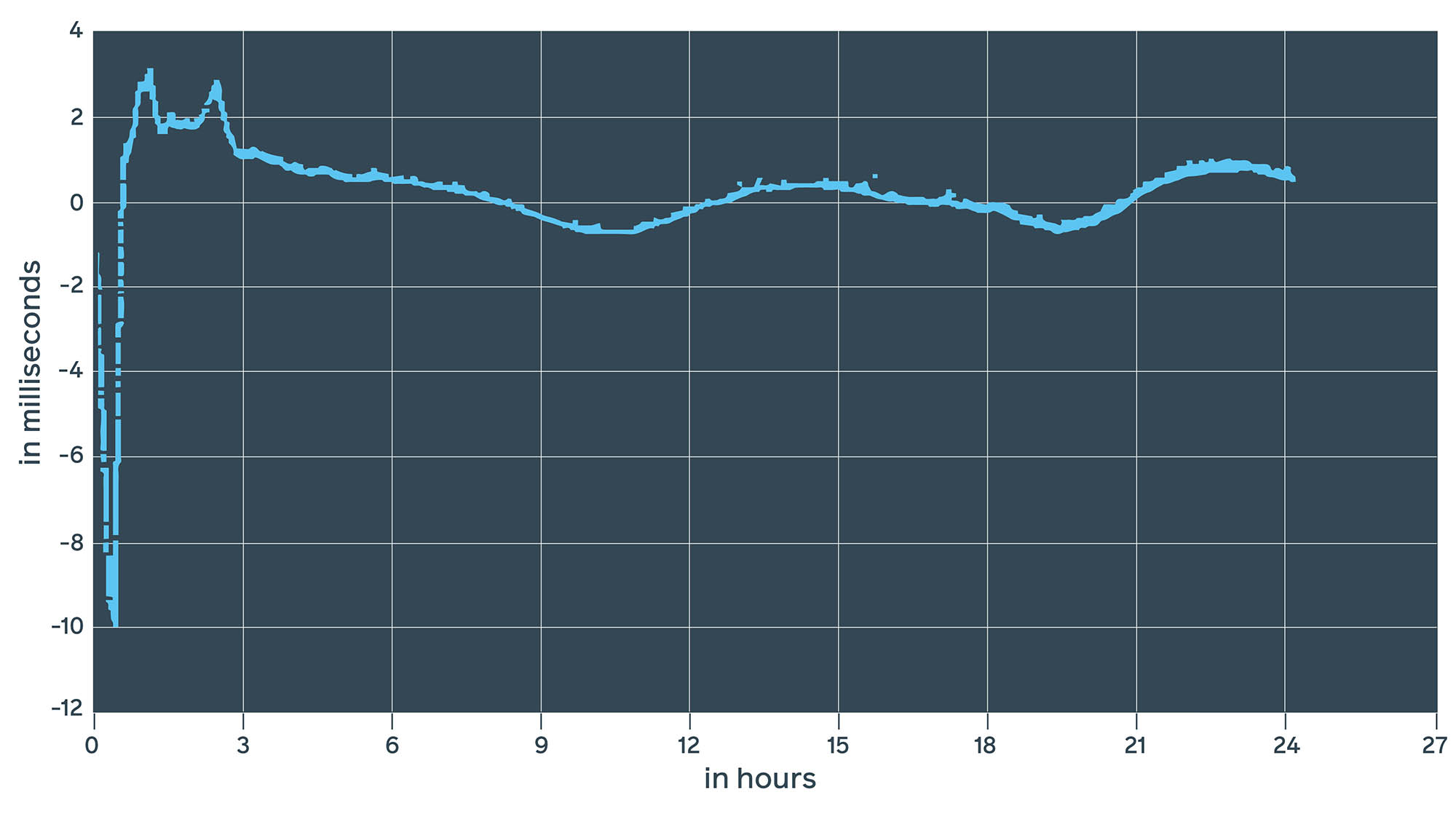
This looks pretty similar to what we’ve seen with daemon estimates and 1PPS measurements. At first, we see a 10 ms drop, which is slowly corrected to +/-1 ms. Interestingly enough, this 10 ms drop is pretty persistent and repeats after every restart.
Chrony measurements
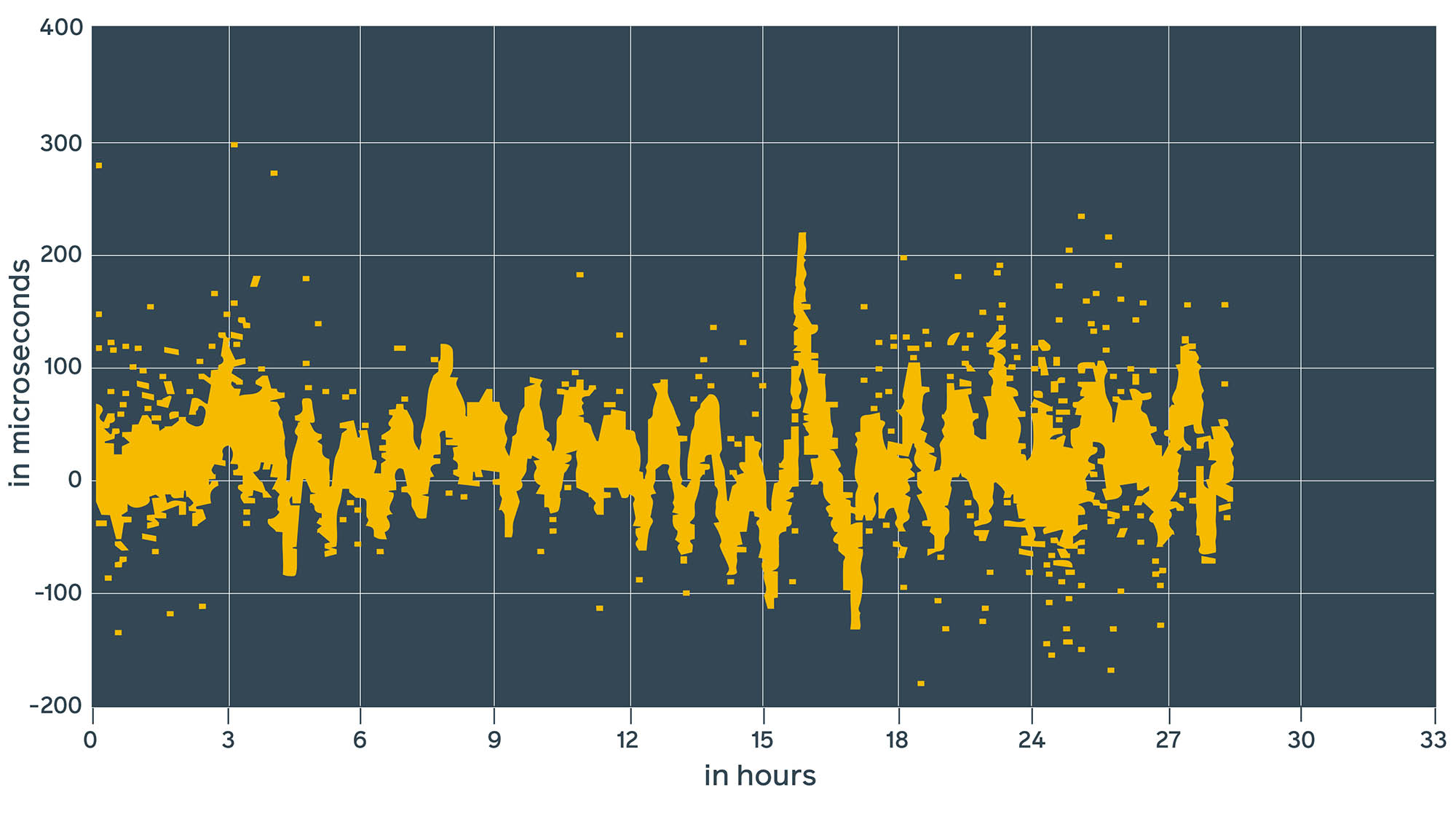
This looks pretty similar to the chrony daemon estimates. It’s 10 to 100 times better than ntpd.
Chrony with hardware timestamps
Chrony has greatly improved the offset, which can be seen from the estimated 1PPS and lab device values. But there is more: Chrony supports hardware timestamps. According to the documentation, it claims to bring accuracy to within hundreds of nanoseconds.
Let’s look at the NTP packet structure in the NTP client-server communication over network. The initial client’s NTP packet contains the transmit timestamp field.
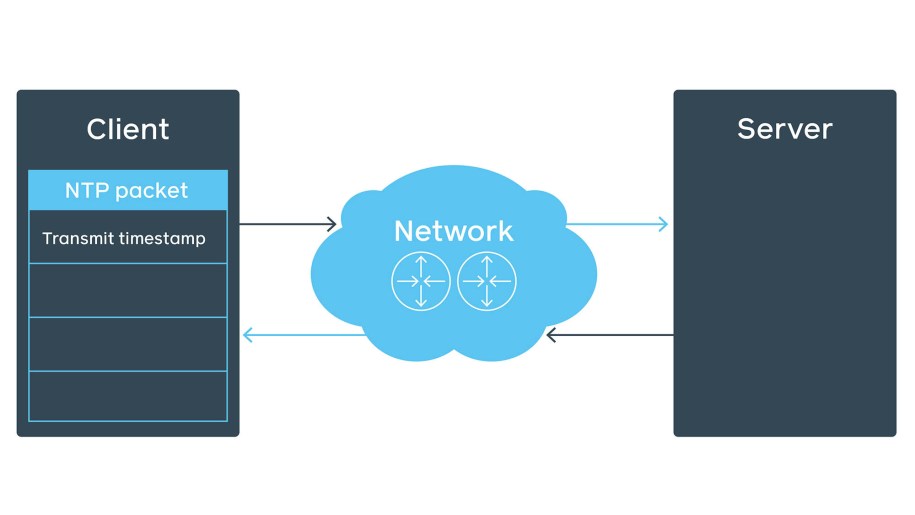
The server fills the rest of the fields (e.g., receive timestamp), preserves the client’s transmit timestamp as originate timestamp, and sends it back to the client.
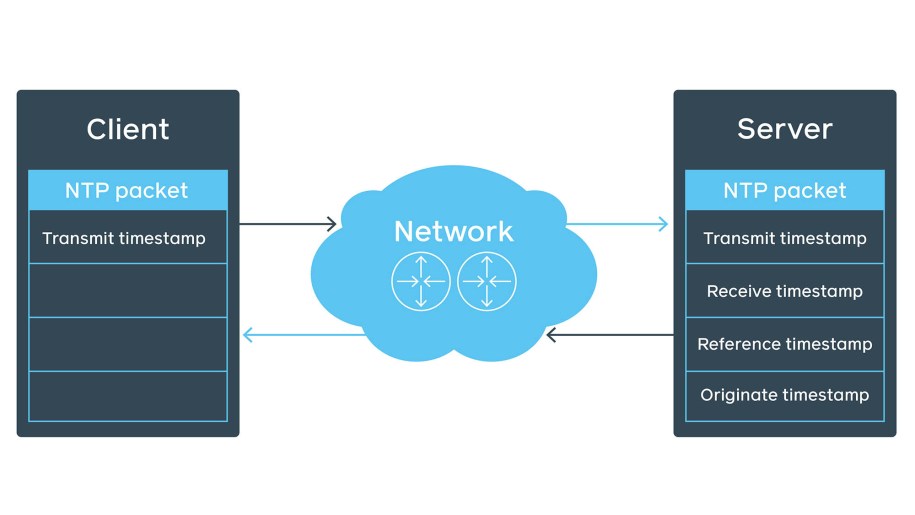
This behavior can be verified using tcpdump:
08:37:31.489921 IP6 (hlim 127, next-header UDP (17) payload length: 56) client.36915 > time1.facebook.com.ntp: [bad udp cksum 0xf5d2 -> 0x595e!] NTPv4, length 48
Client, Leap indicator: clock unsynchronized (192), Stratum 0 (unspecified), poll 3 (8s), precision -6
Root Delay: 1.000000, Root dispersion: 1.000000, Reference-ID: (unspec)
Reference Timestamp: 0.000000000
Originator Timestamp: 0.000000000
Receive Timestamp: 0.000000000
Transmit Timestamp: 3783170251.489887309 (2019/11/19 08:37:31)
Originator - Receive Timestamp: 0.000000000
Originator - Transmit Timestamp: 3783170251.489887309 (2019/11/19 08:37:31)
...
08:37:31.490923 IP6 (hlim 52, next-header UDP (17) payload length: 56) time1.facebook.com.ntp > server.36915: [udp sum ok] NTPv4, length 48
Server, Leap indicator: (0), Stratum 1 (primary reference), poll 3 (8s), precision -32
Root Delay: 0.000000, Root dispersion: 0.000152, Reference-ID: FB
Reference Timestamp: 3783169800.000000000 (2019/11/19 08:30:00)
Originator Timestamp: 3783170251.489887309 (2019/11/19 08:37:31)
Receive Timestamp: 3783170251.490613035 (2019/11/19 08:37:31)
Transmit Timestamp: 3783170251.490631213 (2019/11/19 08:37:31)
Originator - Receive Timestamp: +0.000725725
Originator - Transmit Timestamp: +0.000743903
...The client will get the packet, append yet another receive timestamp, and calculate the offset using the following formula from the NTP RFC #958:
c = (t2 - t1 + t3 - t4)/2
However, Linux is not a real-time operating system, and it has more than one process to run. So, when the transmit timestamp is filled and Write() is called, there is no guarantee that data is sent over the network immediately:
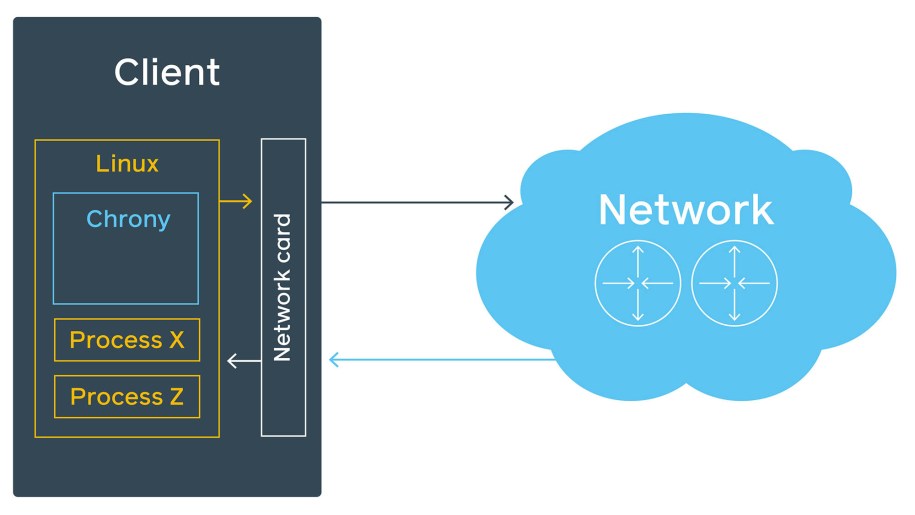
Additionally, if the machine does not have much traffic, an ARP request might be required before sending the NTP packet. This all stays unaccountable and gets into estimated error. Luckily, chrony supports hardware timestamps. With these, chrony on the other end can determine with high precision when the packet was processed by the network interface. There is still a delay between the moment the network card stamps the packet and when it actually leaves it, but it’s less than 10 ns.
Remember this chronyc sources output from before?
^+ server4 2 6 377 60 +11ns[-3913ns] +/- 193usChrony reports an offset of 11 ns. This is the result of hardware timestamps being enabled on involved parties. However, the estimated error is in the range of hundreds of microseconds. Not every network card supports hardware timestamps, but they are becoming more popular, so chances are the network card already supports them.
To verify support for hardware timestamps, simply run the ethtool check so you can see hardware-transmit and hardware-receive capabilities.
ethtool -T eth0
Time stamping parameters for eth0:
Capabilities:
hardware-transmit (SOF_TIMESTAMPING_TX_HARDWARE)
hardware-receive (SOF_TIMESTAMPING_RX_HARDWARE)
hardware-raw-clock (SOF_TIMESTAMPING_RAW_HARDWARE)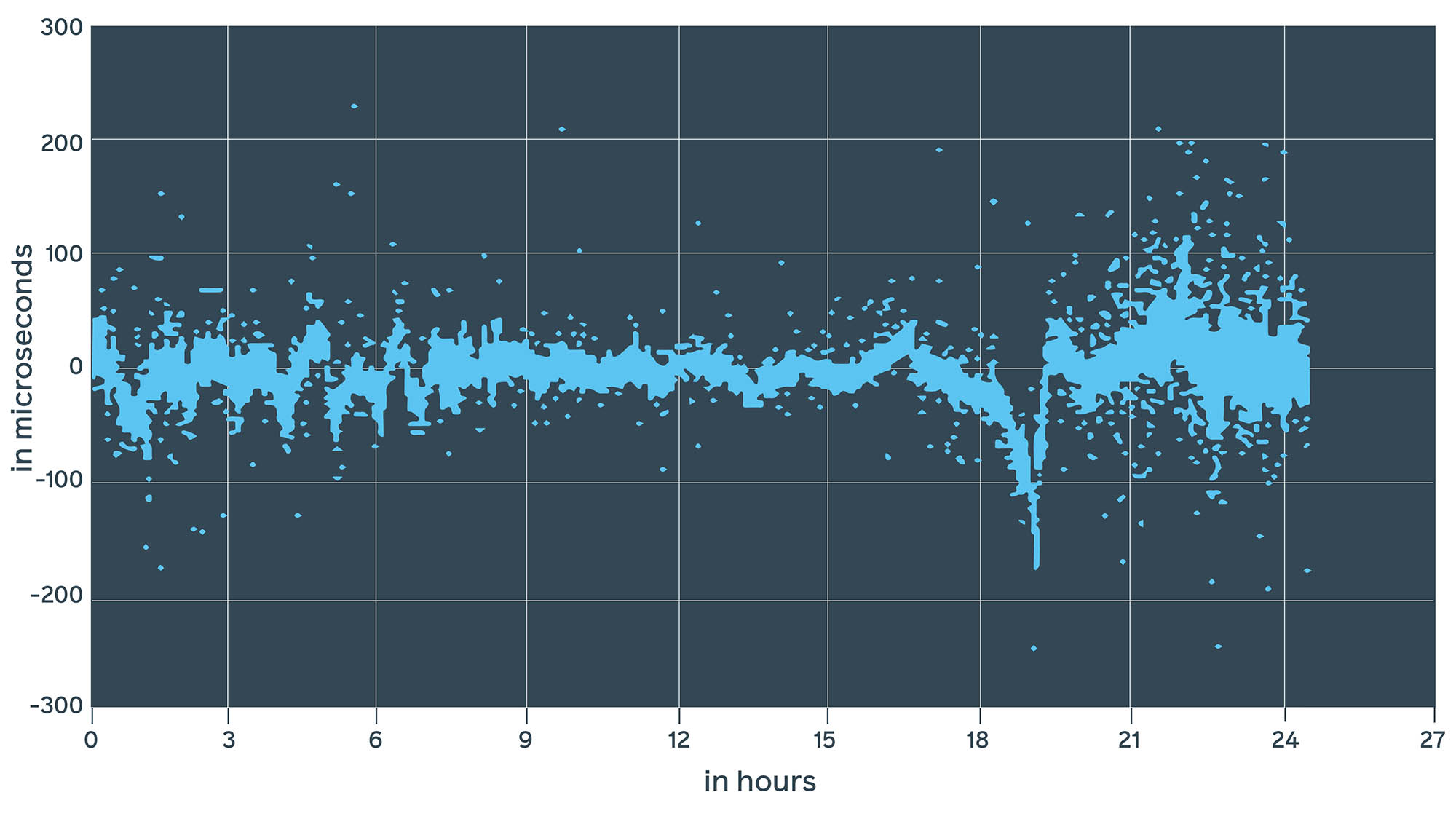
By using the lab device to test the same hardware, we were able to achieve different results, where ntpd showed between -10 ms and 3 ms (13 ms difference), chrony showed between -200 µs and 200 µs, and in most cases, chrony with enabled hardware timestamps showed between -100 µs and 100 µs. This confirms that daemon estimates might be inaccurate.
Public services
All these measurements were done in our internal controlled data center networks. Let’s see what happens when we run this device against our public NTP service and some other well-known public NTP service providers:
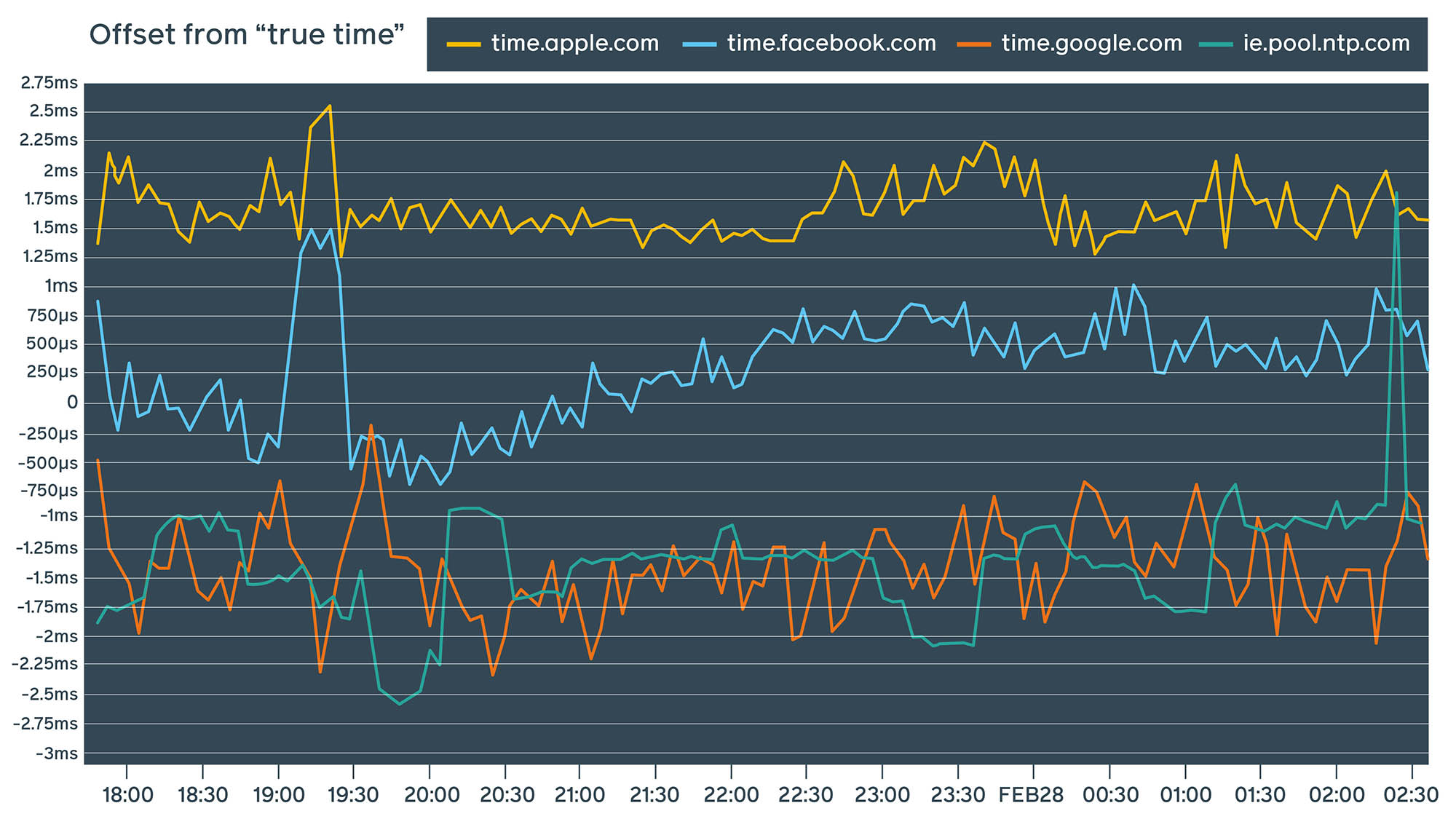
The results of these measurements depend heavily on the network path as well as the speed and quality of the network connection. These measurements were performed multiple times against services from different locations and across a variety of Wi-Fi and LAN networks not associated with Facebook. We can see that not only is our public NTP endpoint competitive with other popular providers, but in some cases, it also outperforms them.
Public NTP design decisions
Once we succeeded in bringing internal precision to the sub-millisecond level, we launched a public NTP service, which can be used by setting time.facebook.com as the NTP server. We run this public NTP service out of our network PoPs (points of presence). To preserve privacy, we do not fingerprint devices by IP address. Having five independent geographically distributed endpoints helps us provide better service — even in the event of a network path failure. So we provide five endpoints:
- time1.facebook.com
- time2.facebook.com
- time3.facebook.com
- time4.facebook.com
- time5.facebook.com
Each of these endpoints terminates in a different geographic location, which has a positive effect on both reliability and time precision.
time2.facebook.com network path:
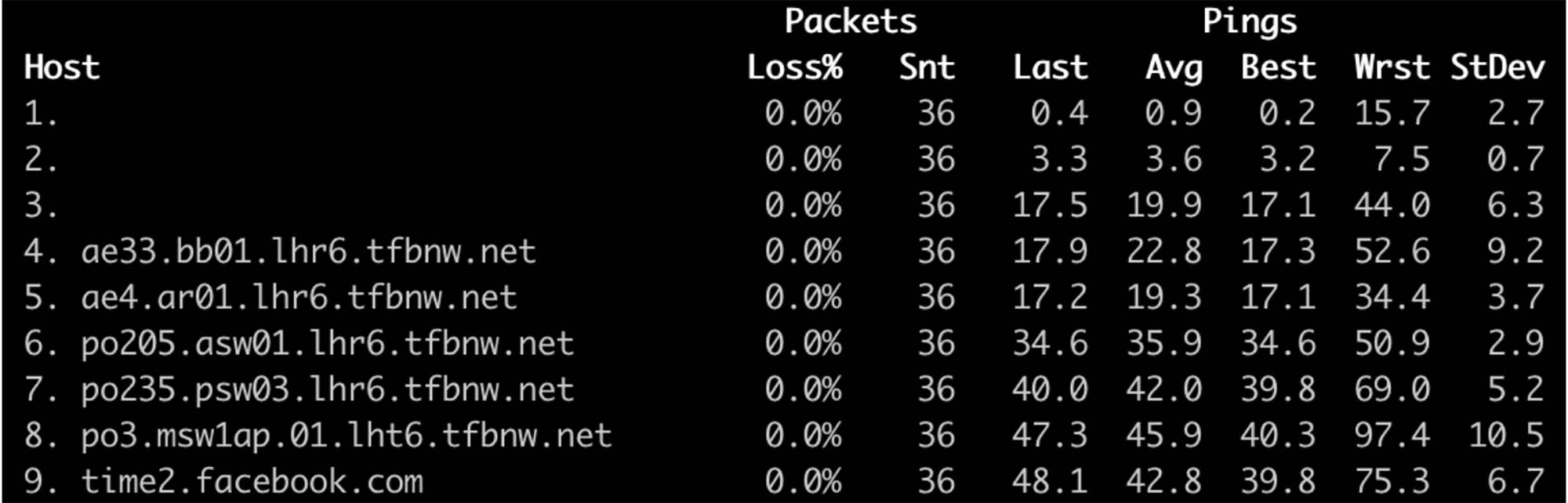
time3.facebook.com network path:
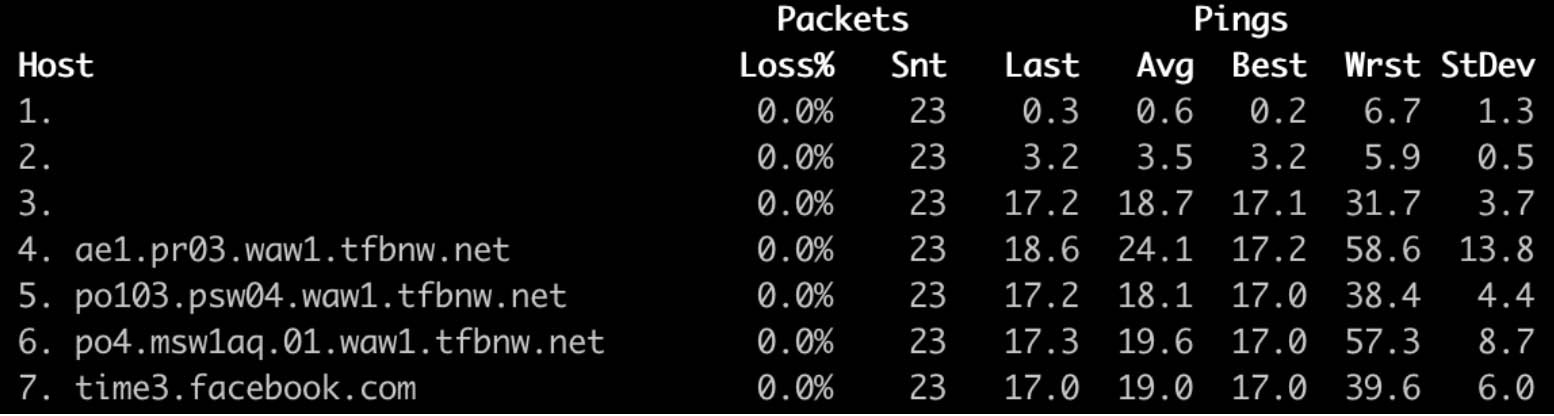
Leap-second smearing
Ntpd uses a leap-seconds.list file that’s published in advance. Using this file, smearing can start early and the time will be correct by the time the leap second actually occurs.
Chrony relies on the leap-second indicator published by GNSS hours in advance. When the leap second event actually happens at 00:00 UTC, it starts to smear throughout a specified time period. With Facebook public NTP, we decided to go with the chrony approach and smear the leap second after the event over approximately 18 hours.
As smearing happens on many Stratum 2 servers at the same time, it’s important for the steps to be as similar as possible. Smoother sine-curve smearing is also safer for the applications.
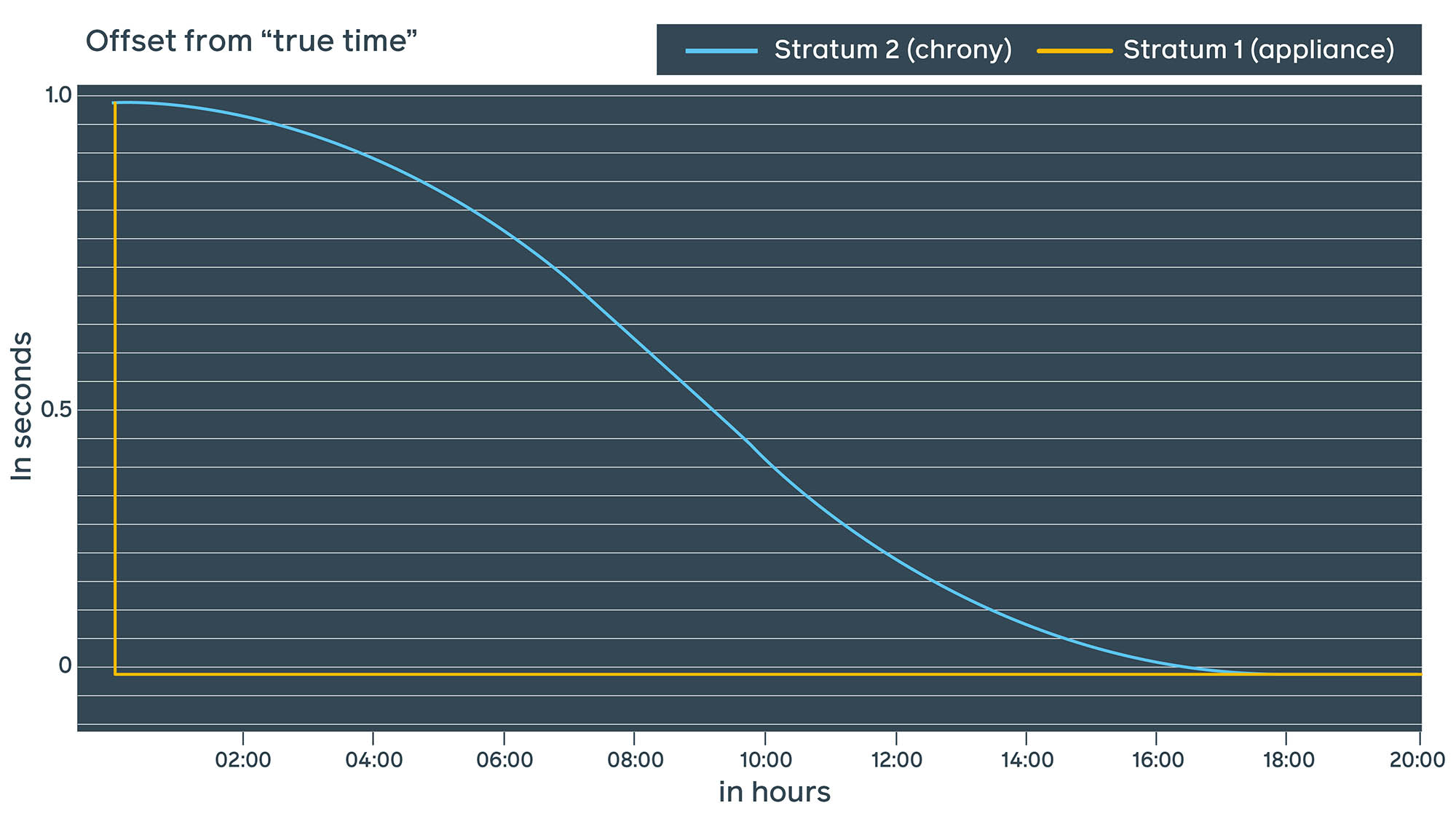
What we’ve learned
Measuring time is challenging. Both ntpd and chrony provide estimates that are somewhat true. In general, if you want to monitor the real offset, we recommend using 1PPS or external devices with GNSS receivers and an atomic clock.
In comparing ntpd with chrony, our measurements indicate that chrony is far more precise, which is why we’ve migrated our infra to chrony and launched a public NTP service. We’ve found that the effort to migrate is worth the immediate improvement in precision from tens of milliseconds to hundreds of microseconds.
Using hardware timestamps can further improve precision by two orders of magnitude. Despite its improvements, NTP has its own limitations, so evaluating PTP can take your precision to the next level.
We’d like to thank Andrei Lukovenko, Alexander Bulimov, Rok Papez, and Yaroslav Kolomiiets for their support on this project.








