
People use our apps and services every day for a wide spectrum of use cases, including sharing pictures; following the latest news and sports updates; sharing life-changing events, such as the birth of a child; or marking themselves safe via Safety Check. Now, more than ever, people are also using our services to stay connected and to bridge gaps created by social distancing around the world. All of these actions being taken by the billions of people around the world who use Facebook, Instagram, and WhatsApp result in user interactions for our systems to process. These interactions result in millions to billions of parallel requests that can be processed in the background without requiring the user interactions to wait for a response. We call these asynchronous (or async) requests.
Some of these async requests can be executed at different times, for instance, notifications about a new message, a post from a friend, or a Facebook Live stream starting. Some of these may be more time-sensitive than others. To manage the different levels of urgency for different types of async requests, we built a system called Async. The original Async was a simple system, but as our apps and services have grown, we needed to scale to manage a greater volume of requests. At Systems @Scale, we are sharing how we’ve reimagined Async to scale to handle billions of requests as efficiently as possible.
Early version
In the original version of Async, all the asynchronous requests were processed and stored in a centralized database. Dispatchers would then query and sort the requests stored in those databases. Later, when the dispatcher pulled jobs from the database and sent them to the worker servers, the sorting operation would provide some basic prioritization based on the request’s desired execution time.
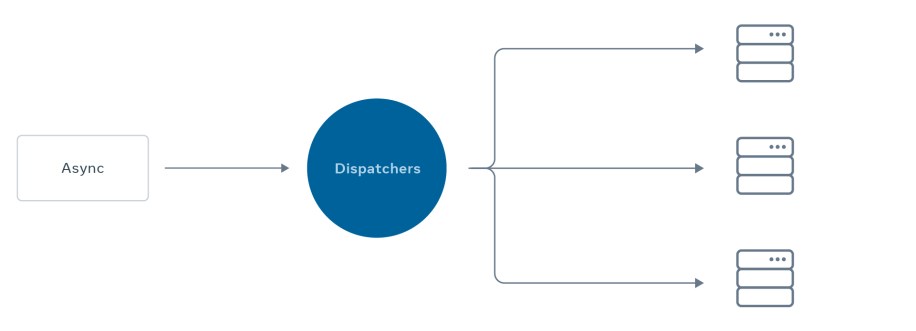
At that time, we had three priorities, and inside each priority queue, it was first come, first served. The system was processing far less traffic at that time, and everything worked well. When new use cases were introduced, we simply added more workers.
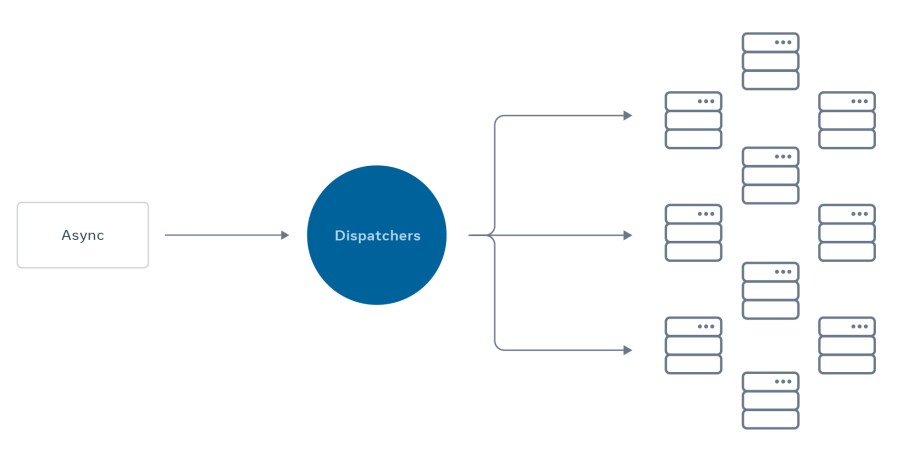
Unfortunately this solution didn’t scale. The simple prioritization was … too simple. With the first-come, first-served strategy, large use cases would dominate the service and smaller use cases would have to wait in the queue for a chance to run. If a use case stalled due to a bug or misconfiguration, the use cases after it might get stuck indefinitely and never leave the queue. Adding more workers wasn’t solving the issue — it wasn’t a scalable solution. During peak hours, every job would have to compete for a spot, which caused high loads on those machines. Then, during off-peak hours, many machines would sit idle. There were underutilized servers and use cases that weren’t running at the expected time. The system was well designed for smaller scale use, but it couldn’t keep up with rapid growth.
Building to scale
As we expanded to more use cases from more engineers, our early system couldn’t keep up. As the system began to get bogged down, engineers began building their own solutions. This not only duplicated efforts but also led to more code to maintain and a bigger surface for potential issues, which led to a higher volume of alerts. We needed to rethink Async to keep our sites and apps fast and reliable for the people using them, even as we continued to add new use cases and see new traffic peaks.
There are several challenges that come with managing requests at this scale. Some of the most important ones include how to architect the system to serve a huge volume of traffic. The core challenges we needed to address were:
Prioritization
The first question is which request to run first. Notification of someone asking for help through Safety Check during a natural disaster or a notification that someone liked a post with a picture of someone’s dog? How does the system determine which action to complete first? What about a notification for a Facebook Live or a notification that your account was logged in from an unrecognized device? To help the system understand what to prioritize, we introduced the concept of delay tolerance, or how long each request can be delayed.
Capacity optimization
The service needs to be able to handle high volumes of traffic with high capacity utilization. For instance, our daily traffic has both peak and off-peak times. If we were to allocate enough machines to handle the peak hours, many of those machines would be idling during off-peak hours. For crisis response use cases, it’s hard to predict the traffic early enough to allocate capacity in advance. One way we manage the different levels is by classifying them into one of three categories: daily traffic, major events, and incident response. We then use queues, time shifts, and batching to better optimize the capacity of our machines.
- Daily traffic: One example of daily traffic is people looking at their News Feed each day, commenting on and reacting to posts. Another example is local churches streaming their masses at about the same time every Sunday. Whether it’s daily or weekly, this type of traffic is relatively predictable.
- Major events: Events like New Year’s Eve, the World Cup, and Facebook Live streams from public figures generally mean more people watching and interacting with one another on our apps. This type of traffic is semi-predictable — we know about the events in advance and can anticipate and prepare for spikes ahead of time.
- Incident response: These events are similar to major events, but we cannot plan for them. Incident response traffic is generally short-lived with a dramatic spike in traffic that returns to previous levels within minutes or hours.
Capacity regulation
How can we make sure each use case gets its fair share? What if one use case schedules 10x traffic when launching a feature? What if a job suddenly consumes high CPU and memory due to a bug? To regulate how much of the capacity is consumed by each use case, we introduced policies that prevent any one job taking more resources than it should.
Async today
The reliability of a system is the sum of the lowest reliability of its dependencies. Several products and internal systems depend on us, including the new Voting Information Center and COVID Information Center. In rethinking Async, we decided to use a common approach — a multitenant architecture — to keep our servers as busy as possible. Today, Async’s multitenant system is a pool of servers that are shared across many use cases with different traffic patterns. This is useful for sharing workloads, but requires finding ways to prioritize hundreds of billions of requests per day and to optimize and regulate capacity.
In addition, as we add new products, we’ll continue to introduce new use cases and edge cases. Managing traffic with heterogeneous behaviors and expectations only increases the level of complexity, and that directly affects the system’s performance and reliability. Building these solutions required making trade-offs to accommodate all use cases in a fair way. To achieve this, we built in the following solutions:
Delay tolerance
When we started rethinking Async, the biggest pain was that not all jobs, even at the same priority level, were equal. The more use cases we onboarded, the more granularity we needed to prioritize according to the business needs. Some could tolerate a few minutes in delay, while others had to be executed as soon as possible. For instance, a notification that someone liked a picture you posted yesterday can be delayed a few seconds. But a notification about a time-based event, like someone you follow going live on Instagram, should be delivered immediately so the notification is received before the event ends.
We can infer a more detailed priority by understanding how long each of these asynchronous requests can be delayed. To help with this, we added the concept of delay tolerance: For each job to be executed, we try to execute it as close as possible to its delay tolerance.
Optimize capacity
There are two major pain points in the capacity area. One is that we cannot process urgent jobs quickly enough when the service is overloaded. The other is that many machines are idling during off-peak times. To improve that, we added three features: queueing, time shifting, and batching.
Queueing
Once we introduced the delay tolerance concept, we had room to optimize the system. When the service is overloaded, we defer jobs with a long delay tolerance so that the workload is spread over a longer time window. Queueing plays an important role in selecting the most urgent job to execute first.
The early Async service used a single table in MySQL to represent a queue. The dispatcher pulled jobs from the table, selected a dynamic number of jobs based on the current workload, and pushed the rest back to MySQL. We called this back-and-forth “push back.” During peak hours, the dispatcher spent more time on this push back instead of sending jobs to the worker. To fix this push back issue, we introduced a multiple-queue system:
- Each use case has its own queue, ordered by the deadline of the job execution.
- The dispatcher compares every queue’s header (or first item) and picks up the most urgent job — based on priority and deadline.
- When the header of one use case queue is selected, a background thread replenishes more jobs from storage for that queue. The use case without any job consumption doesn’t involve any activity.
Time shifting
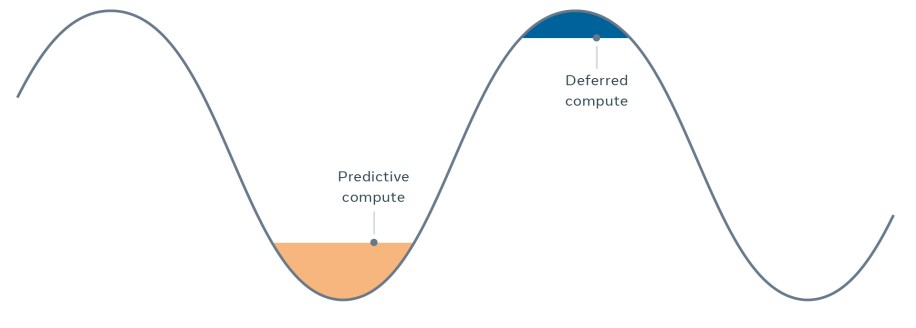
Time shifting is an interesting use case to optimize capacity in Async. Time shifting has two types of compute:
- Predictive compute collects the data people used yesterday. Predicated on which data people may need, it precomputes before peak hours and stores the data in cache. When user requests come in during peak hours, it reads cached data. This moves the computing lift from peak hours to off-peak hours and trades a little cache miss for better efficiency.
- Deferred compute does the opposite. It schedules a job as part of user request handling but runs at much later time. For instance, the “people you may know” list is processed during off-peak hours, then shown when people are online (generally during peak hours).
Both time shifting use cases reduce on-demand capacity during peak hours and utilize the computing resource during off-peak times.
Batching
The life cycle of a job includes being scheduled to a queue, picked up by a dispatcher, sent to a worker, and deleted from the queue. Whether the job runs a few hundred milliseconds or a few minutes, it still takes one slot in the queue and requires one round-trip between the dispatcher and the worker. Except for the job execution part, the load on the Async service is the same.
In the case of major events, which could bring 10x traffic to some use cases, even if we have enough workers, it still creates huge pressure on other components in Async service. Batching is a way to reduce the load. On the service side, it accumulates multiple jobs into one mega job and stores it in the queue. It is still one round-trip between the dispatcher and the worker. Although the worker still needs to run multiple jobs in the same request, the load on other Async components is significantly reduced. Another surprise we found is that, in some cases, it is actually more efficient on the worker side due to high cache reuse and code warmup.
Capacity policy
With the continuous growth of requests being onboarded into Async, bugs and misconfiguration began to affect Async’s reliability. To prevent these bugs and misconfiguration from affecting more use cases, we introduced quotas and rate limiting.
Being a multitenant system, Async needed to track the resources utilized by every request in order to enforce limits accurately. Quotas for CPU instruction utilization and memory limits were introduced: According to each use case’s computation needs, quotas were assigned. If more were required, the engineers could request that more servers be added to the pool of machines. When use cases went above the established quota, their execution would be throttled and an alert was sent to the engineers. This quota prevented them from disrupting Async’s executions.
However, Async’s operations include more than just execution: Misconfiguration could cause our submitter, the component to which async requests are submitted, to become overloaded and occasionally go out of service. Rate limits on requests accepted were introduced to prevent unexpected spikes of traffic from disrupting the system’s ingestion.
A big challenge during this implementation was to ensure that traffic from incident response use cases were not throttled — these use cases have irregular, unpredictable traffic. For this, we added flexibility for quotas where a use case could go beyond its quota for short periods of time.
New solutions bring new challenges
While the evolution of the system closed the initial gaps in the architecture, it also brought new challenges. The system is now more complex, serves significantly more traffic, and brings more edge cases. This makes the system harder to understand, which requires a long period of learning. Greater complexity also brings a deeper learning curve of the system, directly affecting how effective the team members are in troubleshooting issues. Better troubleshooting tools are a requirement to enable a system to grow, and being a tool for human interaction, it needs to be intuitive and easy to understand, so that our users are not blocked when onboarding a new use case into the system.
An important priority among these new challenges is providing both users of our system and Async’s maintainers with a better process for resource accountability and management. Better resource accountability also helps better predict future capacity needs and improves the fairness of resource allocation between use cases, allowing us to provide flexibility for those use cases with surges or spiky traffic.
The challenges that come with managing Async present exciting opportunities for system innovation at massive scale. Whether you are operating at this scale or just starting to learn about the building blocks of a large-scale system, we hope our learnings will help guide you into a more reliable service.








