
More than half of the people on Facebook speak a language other than English, and more than 100 languages are used on the platform. This presents us with the challenge of providing everyone a seamless experience in their preferred language, especially as more of those experiences are powered by machine learning and natural language processing (NLP) at Facebook scale. To better serve our community — whether it’s through offering features like Recommendations and M Suggestions in more languages, or training systems that detect and remove policy-violating content — we needed a better way to scale NLP across many languages.
Existing language-specific NLP techniques are not up to the challenge, because supporting each language is comparable to building a brand-new application and solving the problem from scratch. Today, we’re explaining our new technique of using multilingual embeddings to help us scale to more languages, help AI-powered products ship to new languages faster, and ultimately give people a better Facebook experience.
Challenges for NLP across languages
One common task in NLP is text classification, which refers to the process of assigning a predefined category from a set to a document of text. Text classification models are used across almost every part of Facebook in some way. Examples include recognizing when someone is asking for a recommendation in a post, or automating the removal of objectionable content like spam. Classification models are typically trained by showing a neural network large amounts of data labeled with these categories as examples. Through this process, they learn how to categorize new examples, and then can be used to make predictions that power product experiences.
The training process is typically language-specific, meaning that for each language you want to be able to classify, you need to collect a separate, large set of training data. Collecting data is an expensive and time-consuming process, and collection becomes increasingly difficult as we scale to support more than 100 languages.
Another approach we could take is to collect large amounts of data in English to train an English classifier, and then — if there’s a need to classify a piece of text in another language like Turkish — translating that Turkish text to English and sending the translated text to the English classifier.
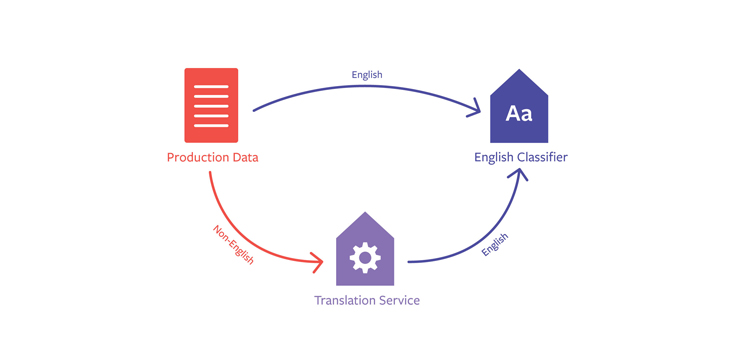
However, this approach has some drawbacks. First, errors in translation get propagated through to classification, resulting in degraded performance. Second, it requires making an additional call to our translation service for every piece of non-English content we want to classify. This adds significant latency to classification, as translation typically takes longer to complete than classification.
We felt that neither of these solutions was good enough. We wanted a more universal solution that would produce both consistent and accurate results across all the languages we support.
Text classification using multilingual word embeddings
Text classification models use word embeddings, or words represented as multidimensional vectors, as their base representations to understand languages. Word embeddings have nice properties that make them easy to operate on, including the property that words with similar meanings are close together in vector space. Traditionally, word embeddings have been language-specific, with embeddings for each language trained separately and existing in entirely different vector spaces.
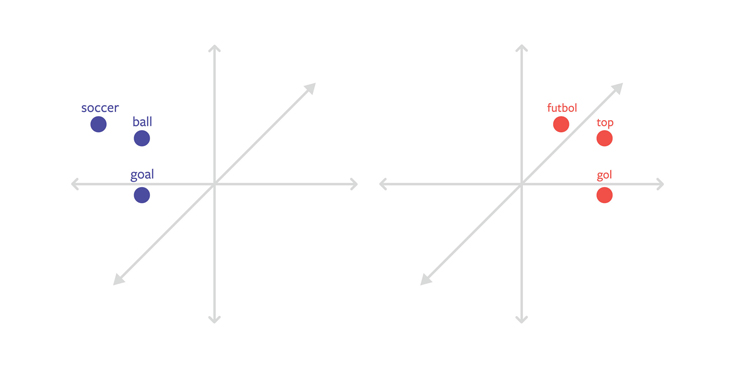
One way to make text classification multilingual is to develop multilingual word embeddings. With this technique, embeddings for every language exist in the same vector space, and maintain the property that words with similar meanings (regardless of language) are close together in vector space. For example, the words futbol in Turkish and soccer in English would appear very close together in the embedding space because they mean the same thing in different languages.
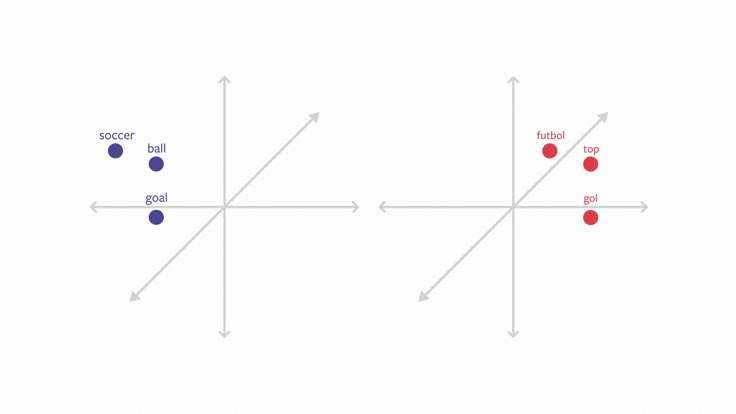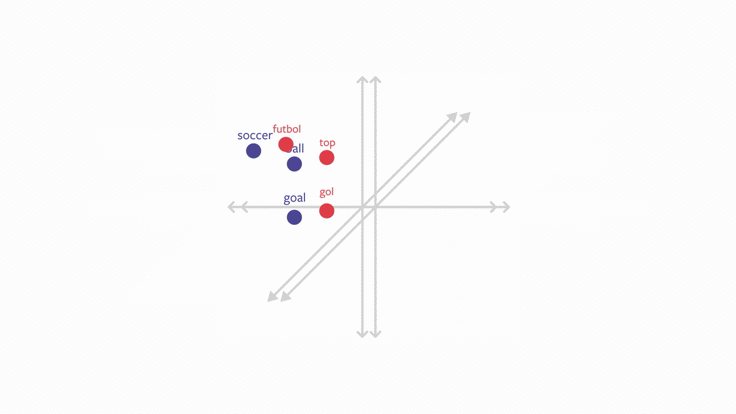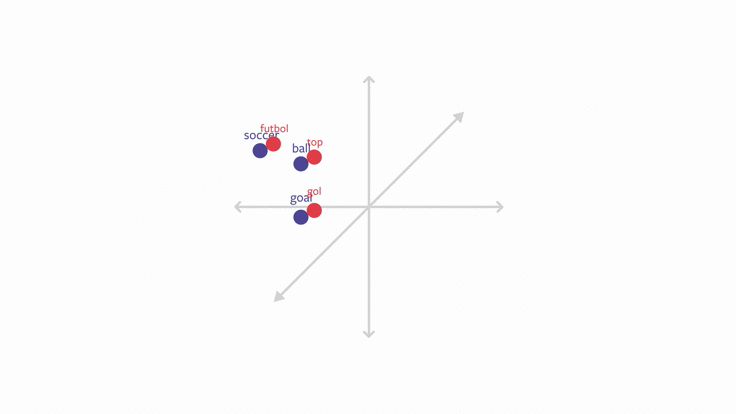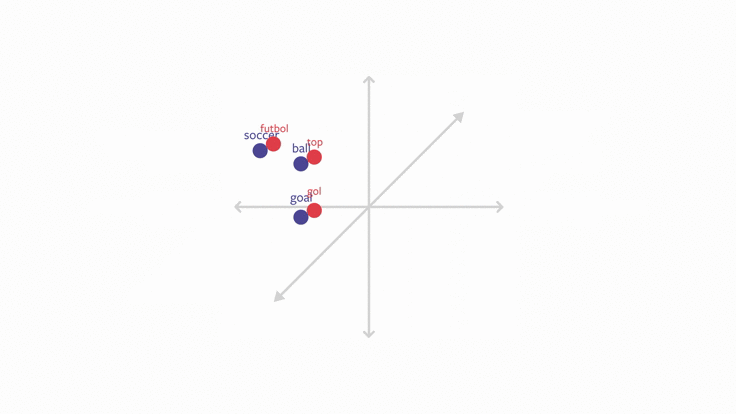
In order to make text classification work across languages, then, you use these multilingual word embeddings with this property as the base representations for text classification models. Since the words in the new language will appear close to the words in trained languages in the embedding space, the classifier will be able to do well on the new languages too. Thus, you can train on one or more languages, and learn a classifier that works on languages you never saw in training.
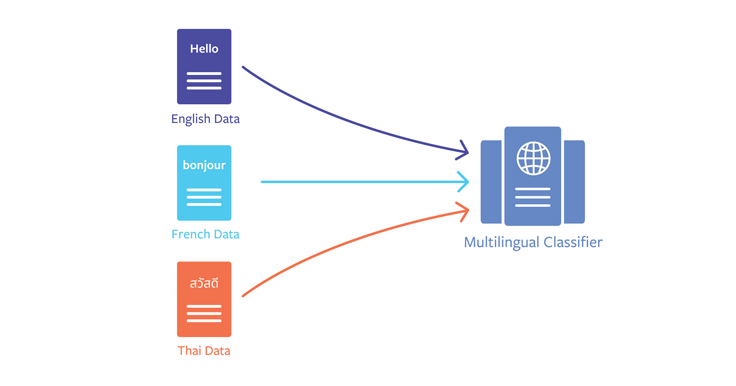
Training multilingual embeddings
To train these multilingual word embeddings, we first trained separate embeddings for each language using fastText and a combination of data from Facebook and Wikipedia. We then used dictionaries to project each of these embedding spaces into a common space (English). The dictionaries are automatically induced from parallel data — meaning data sets that consist of a pair of sentences in two different languages that have the same meaning — which we use for training translation systems.
We use a matrix to project the embeddings into the common space. The matrix is selected to minimize the distance between a word, xi, and its projected counterpart, yi. That is, if our dictionary consists of pairs (xi, yi), we would select projector M such that
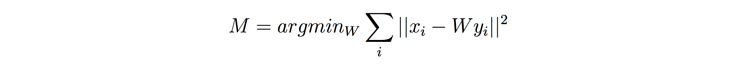
where ||2 indicates the 2-norm. Additionally, we constrain the projector matrix W to be orthogonal so that the original distances between word embedding vectors are preserved.
We integrated these embeddings into DeepText, our text classification framework. DeepText includes various classification algorithms that use word embeddings as base representations. Multilingual models are trained by using our multilingual word embeddings as the base representations in DeepText and “freezing” them, or leaving them unchanged during the training process. We also have workflows that can take different language-specific training and test sets and compute in-language and cross-lingual performance. This facilitates the process of releasing cross-lingual models.
For some classification problems, models trained with multilingual word embeddings exhibit cross-lingual performance very close to the performance of a language-specific classifier. We observe accuracy close to 95 percent when operating on languages not originally seen in training, compared with a similar classifier trained with language-specific data sets. The previous approach of translating input typically showed cross-lingual accuracy that is 82 percent of the accuracy of language-specific models. We also saw a speedup of 20x to 30x in overall latency when comparing the new multilingual approach with the translation and classify approach.
On Facebook at scale
We’ve accomplished a few things by moving from language-specific models for every application to multilingual embeddings that serve as a universal and underlying layer:
- AI-powered features like Recommendations and M Suggestions ship to several new languages faster.
- We’re able to launch products and features in more languages.
- This approach is typically more accurate than the ones we described above, which should mean people have better experiences using Facebook in their preferred language.
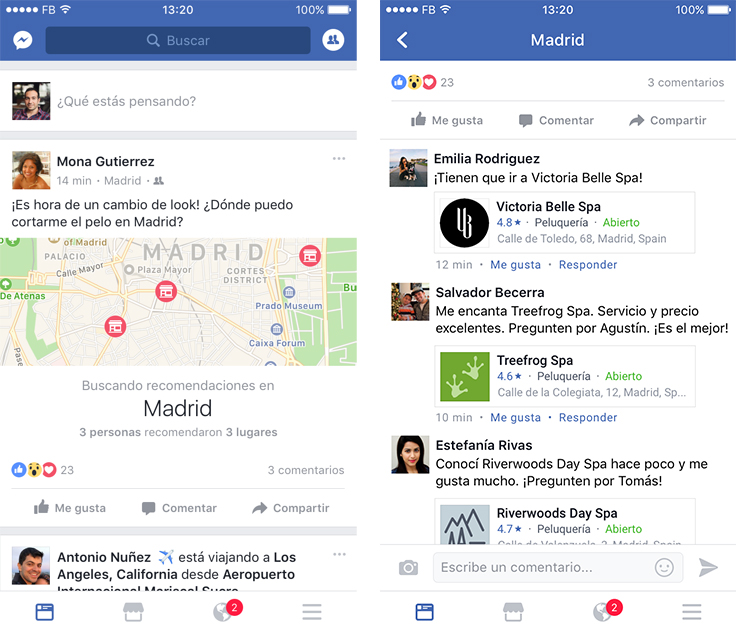
We’re using multilingual embeddings across the Facebook ecosystem in many other ways, from our Integrity systems that detect policy-violating content to classifiers that support features like Event Recommendations.
Ongoing work
Our progress with scaling through multilingual embeddings is promising, but we know we have more to do.
We’re seeing multilingual embeddings perform better for English, German, French, and Spanish, and for languages that are closely related. As we continue to scale, we’re dedicated to trying new techniques for languages where we don’t have large amounts of data. We’re also working on finding ways to capture nuances in cultural context across languages, such as the phrase “it’s raining cats and dogs.”
Looking ahead, we are collaborating with FAIR to go beyond word embeddings to improve multilingual NLP and capture more semantic meaning by using embeddings of higher-level structures such as sentences or paragraphs. Through this technique, we hope to see improved performance when compared with training a language-specific model, and for increased accuracy in culture- or language-specific references and ways of phrasing.
FAIR is also exploring methods for learning multilingual word embeddings without a bilingual dictionary. These methods have shown results competitive with the supervised methods that we are using and can help us with rare languages for which dictionaries are not available. FAIR has open-sourced the MUSE library for unsupervised and supervised multilingual embeddings.







