
Today we are rolling out automatic alternative (alt) text on Facebook for iOS. Automatic alt text provides visually impaired and blind people with a text description of a photo using object recognition technology. Starting today, people using a screen reader to access Facebook on an iOS device will hear a list of items that may be shown in a photo. This feature is now available in English for people in the U.S., U.K., Canada, Australia, and New Zealand. We plan to roll it out to more platforms, languages, and markets soon.
While this technology is still nascent, tapping its current capabilities to describe photos is a huge step toward providing our visually impaired community with the same benefits and enjoyment that everyone else gets from photos on Facebook.
Why automatic alt text
Every day, people share more than 2 billion photos across Facebook, Instagram, Messenger, and WhatsApp.
While visual content provides a fun and expressive way for people to communicate online, consuming it and creating it pose challenges for people with low vision or blindness. A recent study we conducted with Cornell University showed that although blind people are interested in visual content on social media, they often feel frustrated and even excluded or isolated because they can’t fully participate in conversations centered on photos and videos.
Facebook’s mission is to make the world more open and connected. This means that we want everyone to have equal access to connect with others. Worldwide, more than 39 million people are blind, and more than 246 million have a severe visual impairment. As Facebook becomes an increasingly visual experience, we hope our new automatic alternative text technology will help the blind community experience Facebook the same way others enjoy it.
While some services exist to help blind people understand photos, most of them rely on friends or volunteers to interpret the photos. Our goal is to algorithmically generate useful and accurate descriptions of photos in a way that works on a much larger scale without latency in the user experience. We provide these descriptions as image alt text, an HTML attribute designed for content managers to provide text alternatives for images. Since alt text is part of the W3C accessibility standards, any screen reader software can pick it up and read it out to people when they move the screen reader’s reading cursor to an image.
Building automatic alt text
Before we started the implementation, we ran a wide range of data/performance analysis to make sure that our system was scalable with reasonable precision and recall. It took us 10 months to bring this feature to its current stage, through iterations of design, prototyping, and user studies. The biggest challenge, as we learned during this process, is balancing people’s desire for more information about the images with the quality and social intelligence of such information. Interpretation of visual content can be very subjective and context-dependent. For instance, though people mostly care about who is in the photo and what they are doing, sometimes the background of the photo is what makes it interesting or significant.
Recognizing salient things in an image is very different from recognizing what is most interesting in an image. While that may be intuitive to humans, it is quite challenging to teach a machine to provide as much useful information as possible while acknowledging the social context. Our hope is to build a service that has sufficient recall to be useful, while minimizing errors that might cause awkward social interactions, such as returning an object that isn’t in the photo. With these considerations in mind, we break down our design into the following four components.
Content understanding at scale
Facebook has become one of the largest and fastest-growing repositories of images and videos. The computer vision (CV) platform built as part of Facebook’s applied machine learning efforts makes it possible to leverage all that rich content to create better experiences for everybody on Facebook. The platform provides a visual recognition engine whose role is to “see” inside images and videos to understand what they depict. For example, the engine would know if an image contains a cat, features skiing, was taken at the beach, includes the Eiffel Tower, and so on. Specifically, we can detect objects, scenes, actions, places of interest, whether an image/video contains objectionable content, and more. This is a formidable task given the scale and diversity of the visual material uploaded to Facebook, even when compared with the largest and most complex available academic data sets.
At its core, the engine is a deep convolutional neural network with millions of learnable parameters. The CV platform contains tools to easily collect and annotate millions of example images that are then used to train the network in a supervised and semi-supervised manner. The platform also provides the capability to learn new visual concepts within minutes and immediately start detecting them in new photos and videos.
There has been a lot of active research in the computer vision community on directly generating natural language description of images. Even though we are working on adding that type of capability to our CV platform, the state-of-the-art techniques do not yet provide a high enough accuracy in such a complex scenario as the one we are tackling here. For the time being, our approach is to use the outputs of the recognition engine to construct sentences in a separate step, as explained below.
Selection of concepts
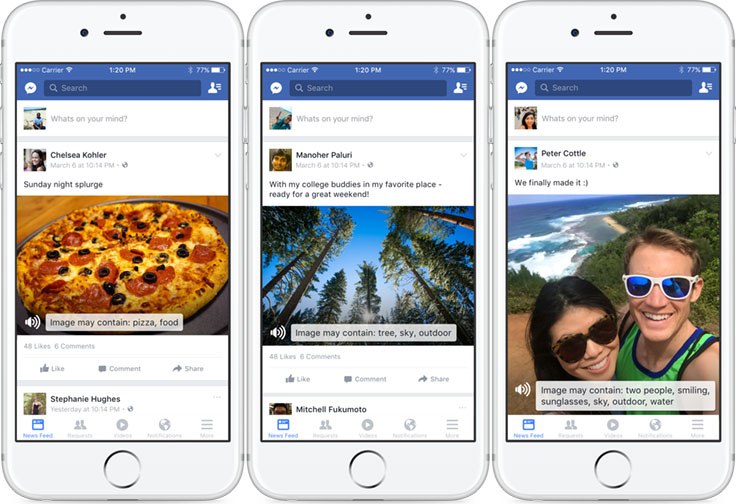
While Facebook’s visual recognition technology described above can be used to recognize a wide range of objects and scenes (both referred to as “concepts” in the rest of this post), for this first launch we carefully selected a set of about 100 concepts based on their prominence in photos as well as the accuracy of the visual recognition engine. We also chose concepts that had very specific meanings, and we avoided concepts open to interpretation. The current list of concepts covers a wide range of things that can appear in photos, such as people’s appearance (e.g., baby, eyeglasses, beard, smiling, jewelry), nature (outdoor, mountain, snow, sky), transportation (car, boat, airplane, bicycle), sports (tennis, swimming, stadium, baseball), and food (ice cream, pizza, dessert, coffee). And settings provided different sets of information about the image, including people (e.g., people count, smiling, child, baby), objects (car, building, tree, cloud, food), settings (inside restaurant, outdoor, nature), and other image properties (text, selfie, close-up).
We make sure that our object detection algorithm can detect any of these concepts with a minimum precision of 0.8 (some are as high as 0.99). Even with such a high quality bar, we can still retrieve at least one concept for more than 50 percent of photos on Facebook. Over time our goal is to keep increasing the vocabulary of automatic alt text to provide even richer descriptions.
Construction of sentence
After detecting the major objects in a photo, we need to organize them in a way that feels natural to people. We experimented with different approaches, such as ordering the concepts by their confidence, showing the concepts with a confidence level (such as 50 percent or 75 percent) attached to them, and so on. After many surveys and in-lab user experience studies, and after using this feature ourselves, we decided to group all the concepts into three categories — people, objects, and scenes — and then present information in this order. For each photo, we first report the number of people (approximated by the number of faces) in the photos, and whether they are smiling or not; we then list all the objects we detect, ordered by the detection algorithm’s confidence; scenes, such as settings and properties of the entire image (e.g., indoor, outdoor, selfie, meme), will be presented at the end. In addition, since we cannot guarantee that the description we deliver is 100 percent accurate (given that it’s neither created nor reviewed by a human), we start our sentence with the phrase “Image may contain” to convey uncertainty. As a result, we will construct a sentence like “Image may contain: two people, smiling, sunglasses, sky, tree, outdoor.”
Build a seamless experience
One advantage of using machine-generated captions is that people do not need to take any action to have a photo described, even if only partially. While on-demand requests for information about a photo or user-supplied descriptions can be useful, machine-generated captions provide unmatched coverage and convenience for photos on large-scale services such as Facebook. Since this is the first time we’ve introduced machine-generated automatic photo descriptions, we want to make sure that it is as lightweight and unobtrusive as possible, so that it enhances their existing Facebook experience without a learning curve.
The launch of automatic alt text is just the beginning: We are committed to improving this technology and making a more inclusive Facebook experience. Today we are thrilled to share this step forward with you.








