
A few months ago we rolled out Live for Facebook Mentions, which allows verified public figures using Mentions to broadcast live video to their fans on Facebook. We learned a lot through that deployment and are excited to say that today we’re beginning to test the ability for people to share live video on Facebook, starting with a small percentage of people in the U.S. on iPhones. (Read more in our Newsroom post.)
Building live video for Facebook was a challenging exercise in engineering for scale. With Live for Facebook Mentions, we had to solve for huge traffic spikes. Public figures on Facebook can have millions of followers all trying to watch a video at once; creating new tricks for load balancing became our goal. To begin rolling out live video for more people, we’re taking the latency in live broadcasts down to few seconds by enabling RTMP playback. We’re hoping that these low-latency broadcasts will make the experience more engaging for broadcasters and viewers alike. In this post, we’ll walk through the problems we solved for in each of these launches and explain the solutions we chose for load balancing and RTMP implementation.
Solving the “thundering herd” problem
Some public figures have millions of followers on Facebook. This means that when public figures start a live broadcast, we need to be able to handle the potential of more than a million people watching the broadcast at the same time, as happened recently with Vin Diesel’s live stream. No high-scale system likes traffic spikes, especially this many requests coming in at once. When it happens, we call it a “thundering herd” problem — too many requests can stampede the system, causing lag, dropout, and disconnection from the stream.
The best way to stop the stampede is to never let it through the gates, so to speak. Instead of having clients connecting directly to the live stream server, there’s a network of edge caches distributed around the globe. A live video is split into three-second HLS segments in our implementation. These segments are sequentially requested by the video player displaying the broadcast. The segment request is handled by one of the HTTP proxies in an edge data center that checks to see whether the segment is already in an edge cache. If the segment is in cache, it’s returned directly from there. If not, the proxy issues an HTTP request to the origin cache, which is another cache layer with the same architecture. If the segment is not in origin cache, then it needs to request it to the server handling that particular stream. Then the server returns the HTTP response with the segment, which is cached in each layer, so following clients receive it faster. With this scheme, more than 98 percent of segments are already in an edge cache close to the user, and the origin server receives only a fraction of requests.
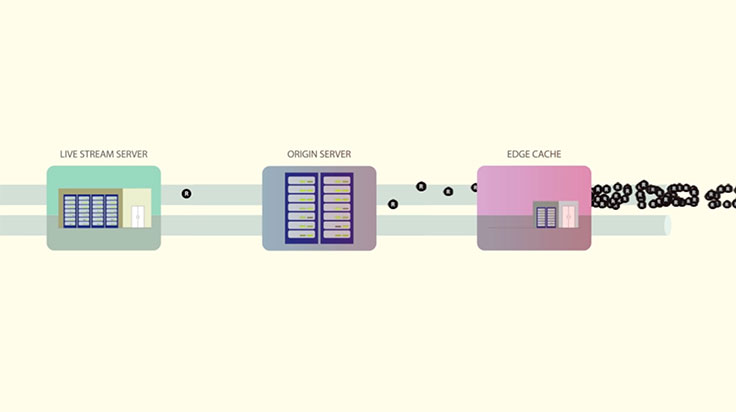
The solution works well, except that at our scale there was some leakage — about 1.8 percent of requests were getting past the edge cache. When you’re dealing with a million viewers, that’s still a large number. To make sure there was no failure at the origin level, we applied a technique called request coalescing. People typically watch regular, non-live videos at different times. You can see the traffic spike coming if something is viral, so the minute-to-minute need to balance the load isn’t there. With live video, a large number of people watch the same video at the same time with potentially no notice, which creates a load problem and a cache problem. People request the same video segment at the same time, and it may not be in cache yet. Without a thundering herd prevention plan, the edge cache would return a cache miss for all the client requests, and all of them would go to origin cache, and all the way to the live stream server. This would mean that a single server would receive a huge number of requests. To prevent that, the edge cache returns a cache miss for the first request, and it holds the following requests in a queue. Once the HTTP response comes from the server, the segment is stored in the edge cache, and the requests in the queue are responded from the edge as cache hits. This effectively handles the thundering herd, reducing the load to origin. The origin cache in turn runs the same mechanism to handle requests from multiple edge caches — the same object can be requested from an edge cache in Chicago and an edge cache in Miami.
Bringing latency down
Where building Live for Facebook Mentions was an exercise in making sure the system didn’t get overloaded, building Live for people was an exercise in reducing latency. People who aren’t public figures are more likely to be broadcasting to a small, interactive group. It was important to us that people be able to have near real-time conversations without an awkward data transmission delay. To bring latency down to a two- to three-second transmission, we decided to use RTMP.
RTMP is a streaming protocol that maintains a persistent TCP connection between the player and the server during the whole broadcast. Unlike HLS, RTMP uses a push model. Instead of the player requesting each segment, the server continuously sends video and audio data. The client can still issue pause and resume commands when the person requests it or when the player is not visible. In RTMP, the broadcast is split into two streams: a video stream and an audio stream. The streams are split into chunks of 4 KB, which can be multiplexed in the TCP connection, i.e., video and audio chunks are interleaved. At a video bit rate of 500 Kbps, each chunk is only 64 ms long, which, compared with HLS segments of 3 seconds each, produces smoother streaming across all components. The broadcaster can send data as soon as it has encoded 64 ms of video data; the transcoding server can process that chunk and produce multiple output bit rates. The chunk is then forwarded through proxies until it reaches the player. The push model plus small chunks reduce the lag between broadcaster and viewer by 5x, producing a smooth and interactive experience. Most of the live stream products use HLS because it’s HTTP-based and easy to integrate with all existing CDNs. But because we wanted to implement the best live streaming product, we decided to implement RTMP by modifying nginx-rtmp module, and developed an RTMP proxy. The lessons learned from the HLS path also allowed us to implement an RTMP architecture that effectively scales to millions of broadcasters.
Moving forward
We’ve gotten a lot of great feedback for Live for Facebook Mentions, and we’re excited to see what people think of the new ability to broadcast as we begin to test it with more accounts. If you have any questions about how we built this, please reach out to us on the Facebook Engineering page.
Many thanks to the engineers, PMs, and other team members who worked on making live video possible, including Eran Ambar, Dave Capra, Piyush Gadigone, Lulu He, Mathieu Henaire, Jason Hu, Rama Karve, Peter Knowles, Vadim Lavrusik, Kevin Lin, Ryan Lin, Sameer Madan, Kirill Pugin, Bhavana Radhakrishnan, Sabyasachi Roy, and Viswanath Sivakumar.








