
Automatic language translation is important to Facebook as a way to allow the billions of people who use our services to connect and communicate in their preferred language. To do this well, current machine translation (MT) systems require access to a considerable volume of translated text (e.g., pairs of the same text in both English and Spanish). As a result, MT currently works well only for the small subset of languages for which a volume of translations is readily available.
Training an MT model without access to any translation resources at training time (known as unsupervised translation) was the necessary next step. Research we are presenting at EMNLP 2018 outlines our recent accomplishments with that task. Our new approach provides a dramatic improvement over previous state-of-the-art unsupervised approaches and is equivalent to supervised approaches trained with nearly 100,000 reference translations. To give some idea of the level of advancement, an improvement of 1 BLEU point (a common metric for judging the accuracy of MT) is considered a remarkable achievement in this field; our methods showed an improvement of more than 10 BLEU points.
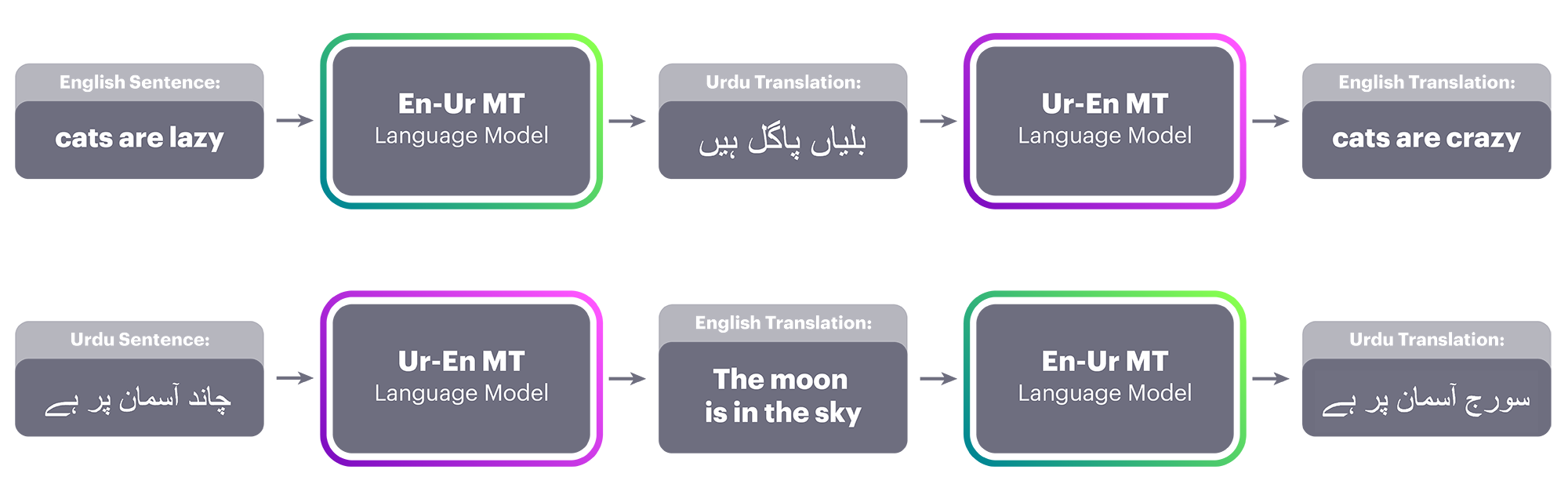
This is an important finding for MT in general and especially for the majority of the 6,500 languages in the world for which the pool of available translation training resources is either nonexistent or so small that it cannot be used with existing systems. For low-resource languages, there is now a way to learn to translate between, say, Urdu and English by having access only to text in English and completely unrelated text in Urdu – without having any of the respective translations.
This new method opens the door to faster, more accurate translations for many more languages. And it may only be the beginning of ways in which these principles can be applied to machine learning and artificial intelligence.
Word-by-word translation
The first step toward our ambitious goal was for the system to learn a bilingual dictionary, which associates a word with its plausible translations in the other language. For this, we used a method we introduced in a previous paper, in which the system first learns word embeddings (vectorial representations of words) for every word in each language.
Word embeddings are trained to predict the words around a given word using context (e.g., the five words preceding and the five words following a given word). Despite their simplicity, word embeddings capture interesting semantic structure. For instance, the nearest neighbor of “kitty” is “cat,” and the embedding of the word “kitty” is much closer to the embedding of “animal” than it is to the embedding of the word “rocket” (as “rocket” seldom appears in the context of the word “kitty”).
Moreover, embeddings of words in different languages share similar neighborhood structure, because people across the world share the same physical world; for instance, the relationship between the words “cat” and “furry” in English is similar to their corresponding translation in Spanish (“gato” and “peludo”), as the frequency of these words and their context are similar.
Because of those similarities, we proposed having the system learn a rotation of the word embeddings in one language to match the word embeddings in the other language, using a combination of various new and old techniques, such as adversarial training. With that information, we can infer a fairly accurate bilingual dictionary without access to any translation and essentially perform word-by-word translation.

Two-dimensional word embeddings in two languages (left) can be aligned via a simple rotation (right). After the rotation, word translation is performed via nearest neighbor search.
Translating sentences
Word-by-word translation using a bilingual dictionary inferred in an unsupervised way is not a great translation — words may be missing, out of order, or just plain wrong. However, it preserves most of the meaning. We can improve upon this by making local edits using a language model that has been trained on lots of monolingual data to score sequences of words in such a way that fluent sentences score higher than ungrammatical or poorly constructed sentences.
So, if we have a large monolingual data set in Urdu, we can train a language model in Urdu alongside the language model we have for English. Equipped with a language model and the word-by-word initialization, we can now build an early version of a translation system.
Although it’s not very good yet, this early system is already better than word-by-word translation (thanks to the language model), and it can be used to translate lots of sentences from the source language (Urdu) to the target language (English).
Next, we treat these system translations (original sentence in Urdu, translation in English) as ground truth data to train an MT system in the opposite direction, from English to Urdu. Admittedly, the input English sentences will be somewhat corrupt because of translation errors of the first system. This technique was introduced by R. Sennrich et al. at ACL 2015 in the context of semisupervised learning of MT systems (for which a good number of parallel sentences are available), and it was dubbed back translation. This is the first time this technique has been applied to a fully unsupervised system; typically, it is initially trained on supervised data.
Now that we have an Urdu language model that will prefer the more fluent sentences, we can combine the artificially generated parallel sentences from our back translation with the corrections provided by the Urdu language model to train a translation system from English to Urdu.
Once the system has been trained, we can use it to translate many sentences in English to Urdu, forming another data set of the kind (original sentence in English, translation in Urdu) that can help improve the previous Urdu-to-English MT system. As one system gets better, we can use it to produce training data for the system in the opposite direction in an iterative manner, and for as many iterations as desired.
The best of both worlds
In our research, we identified three steps — word-by-word initialization, language modeling, and back translation — as important principles for unsupervised MT. Equipped with these principles, we can derive various models. We applied them to two very different methods to tackle our goal of unsupervised MT.
The first one was an unsupervised neural model that was more fluent than word-by-word translations but did not produce translations of the quality we wanted. They were, however, good enough to be used as back-translation sentences. With back translation, this method performed about as well as a supervised model with 100,000 parallel sentences.
Next, we applied the principles to another model based on classical count-based statistical methods, dubbed phrase-based MT. These models tend to perform better on low-resource language pairs, which made it particularly interesting, but this is the first time this method has been applied to unsupervised MT. In this case, we found that the translations had the correct words but were less fluent. Again, this method outperformed previous state-of-the-art unsupervised models.
Finally, we combined both models to get the best of both worlds: a model that is both fluent and good at translating. To do this, we started from a trained neural model and then trained it with additional back-translated sentences from the phrase-based model.
Empirically, we found that this last combined approach dramatically improved accuracy over the previous state-of-the-art unsupervised MT — showing an improvement of more than 10 BLEU points on English-French and English-German, two language pairs that have been used as a test bed (and even for these language pairs, there is no use of any parallel data at training time — only at test time, to evaluate).
We also tested our methods on distant language pairs like English-Russian; on low-resource languages like English-Romanian; and on an extremely low-resource and distant language pair, English-Urdu. In all cases, our method greatly improved over other unsupervised approaches, and sometimes even over supervised approaches that use parallel data from other domains or from other languages.
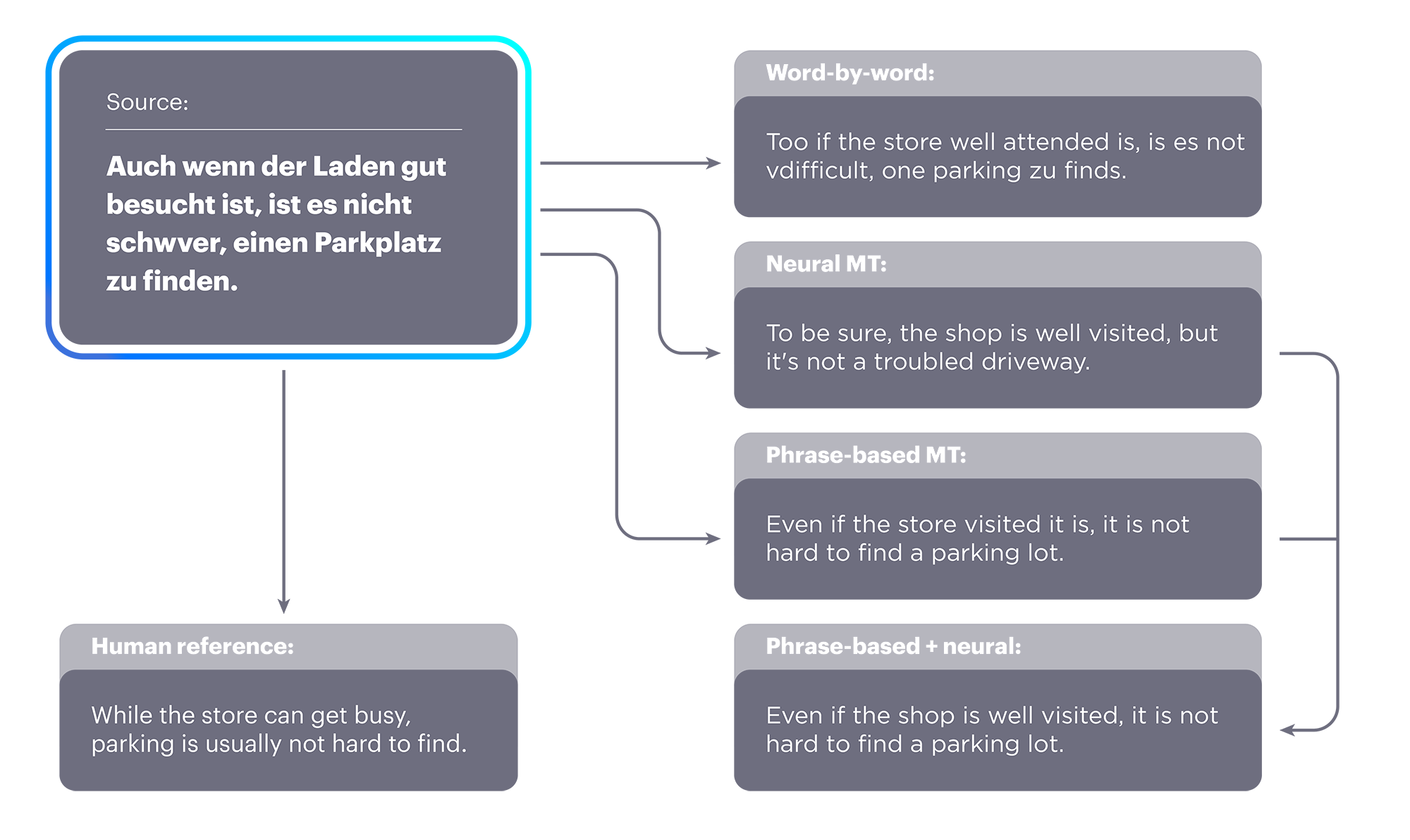
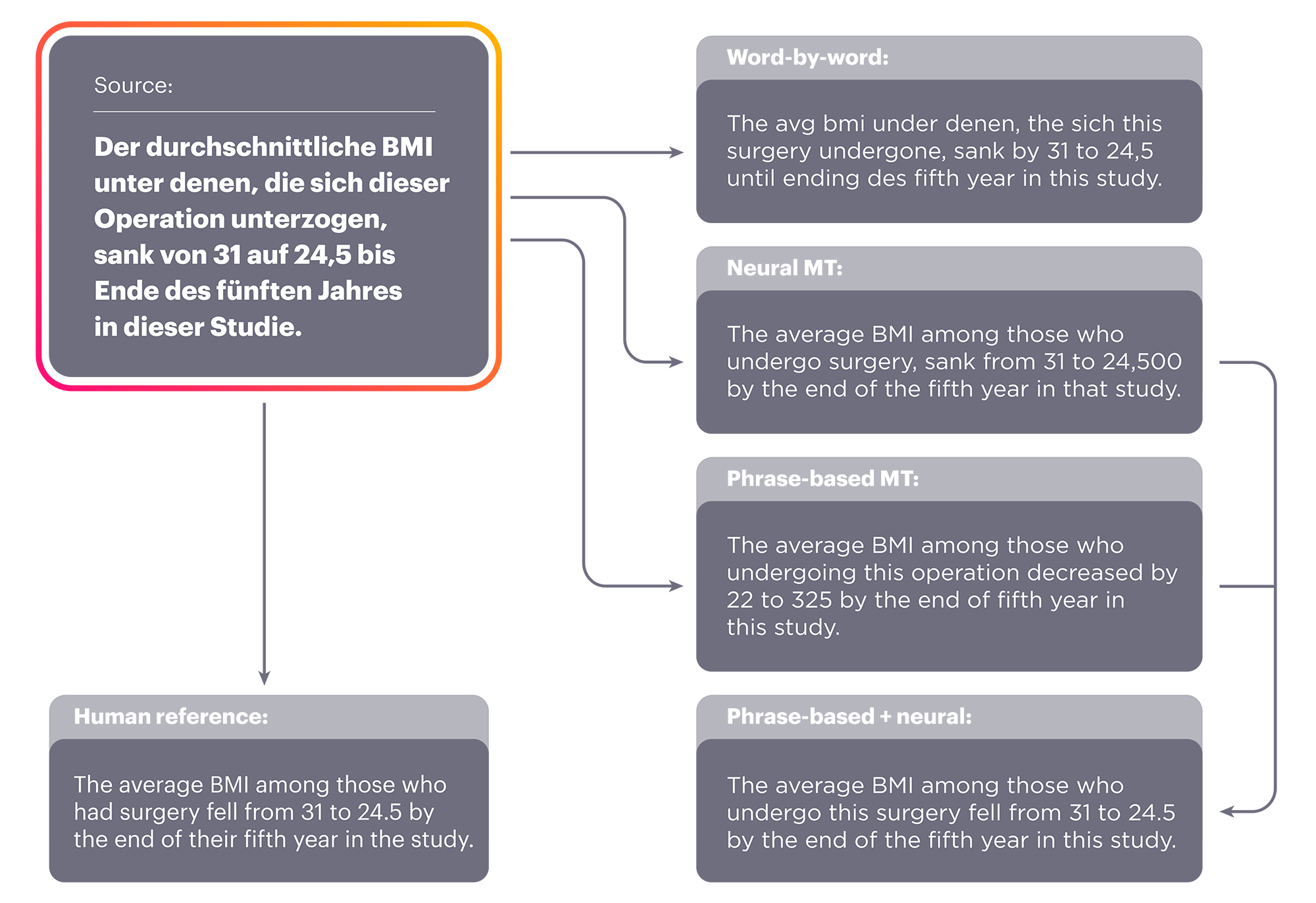
German-to-English translation examples show the results of each method:
Beyond MT
Achieving an increase of more than 10 BLEU points is an exciting start, but even more exciting for us are the possibilities this opens for future improvements. In the short term, this will certainly help us translate in many more languages and improve translation quality for low-resource languages. But the learnings gained from this new method and the underlying principles could go well beyond MT.
We see potential for this research to be applied to unsupervised learning in any arena and potentially allowing agents to leverage unlabeled data and perform tasks with very few, if any, of the expert demonstrations (translations, in this case) that are currently required. This work shows that it is at least possible for the system to learn without supervision and to build a coupled system in which each component improves over time in a sort of virtuous circle.








