
How does Meta empower its product teams to harness GenAI’s power responsibly? In this post, we delve into how Meta addresses the challenges of safeguarding data in the GenAI era by scaling its Privacy Aware Infrastructure (PAI), with a particular focus on Meta’s AI glasses as an example GenAI use case.
- We’ll describe in detail the technology behind data lineage, explain how modern infrastructure supports privacy at scale, and discuss how these advances accelerate product innovation while keeping privacy at the core.
- AI glasses are only one of the latest examples of how generative AI (GenAI) has been driving a range of new product experiences across all our platforms at Meta.
- While GenAI enables new features like hyper-personalized recommendations and responsive real-time assistants, it is also reinforcing the importance of earning and maintaining user trust by maintaining and protecting user data.
As AI products like our AI glasses ingest, process, and generate increasingly rich data, they also introduce new opportunities for embedding privacy into those processes. Our vision to empower our product teams to responsibly harness the power of GenAI is a bold one: We scale our Privacy Aware Infrastructure (PAI) as a foundational backbone of AI innovation.
By empowering product teams with lineage insights and automated privacy controls, we accelerate GenAI product innovation while upholding user trust and privacy as foundational principles.
The Key Privacy Challenges of GenAI
We’ve encountered three primary challenges to ensuring privacy for GenAI:
- Technological evolution and explosive data growth: The emergence of GenAI has introduced novel data types and dramatically increased data volumes, presenting new complexities in data observability and management.
- Shifting requirements landscape: Advancements in technology continually generate new privacy and compliance requirements. Our ability to remain competitive and innovative hinges on how swiftly we can adapt to these evolving demands.
- Accelerated innovation cycles: GenAI-powered features drive faster product development, necessitating infrastructure that can scale rapidly and enforce privacy controls automatically.
Meta’s AI glasses integrate wearable technology with GenAI to deliver real-time information, personalized assistance, and creative capabilities—all contextualized to the wearer’s surroundings.
- Real-time scene understanding: Meta’s AI glasses leverage advanced cameras and sensors to interpret your surroundings, enabling you to ask questions like, “What is that building?” or “Can you read this sign to me?” and receive instant, relevant answers.
- Contextual overlays: GenAI models deliver dynamic overlays and summaries, offering guidance and information tailored to your current location or activity for a more personalized experience.
- Natural and intuitive interactions: Innovative input methods such as the Meta Neural Band and advanced output technologies, like those featured in the Meta Ray-Ban Display glasses, enable seamless and intuitive interactions and low-latency, full-duplex conversations that go beyond simple commands.
Forward-looking use cases like these highlight the intricate data flows enabled by GenAI: continuous sensor inputs, real-time processing both on-device and in the cloud, and a dynamic feedback loop to the user. They also speak to our key challenges and underscore the need for robust, adaptable systems that prioritize privacy as GenAI continues to transform our products and data ecosystem.
At Meta, we tackle these challenges with integrated privacy via a scalable infrastructure that is deeply embedded from the ground up during product development.
For example, Figure 1 outlines how we use our PAI technologies to track and protect user interactions with the Meta AI app that happen through our AI glasses.
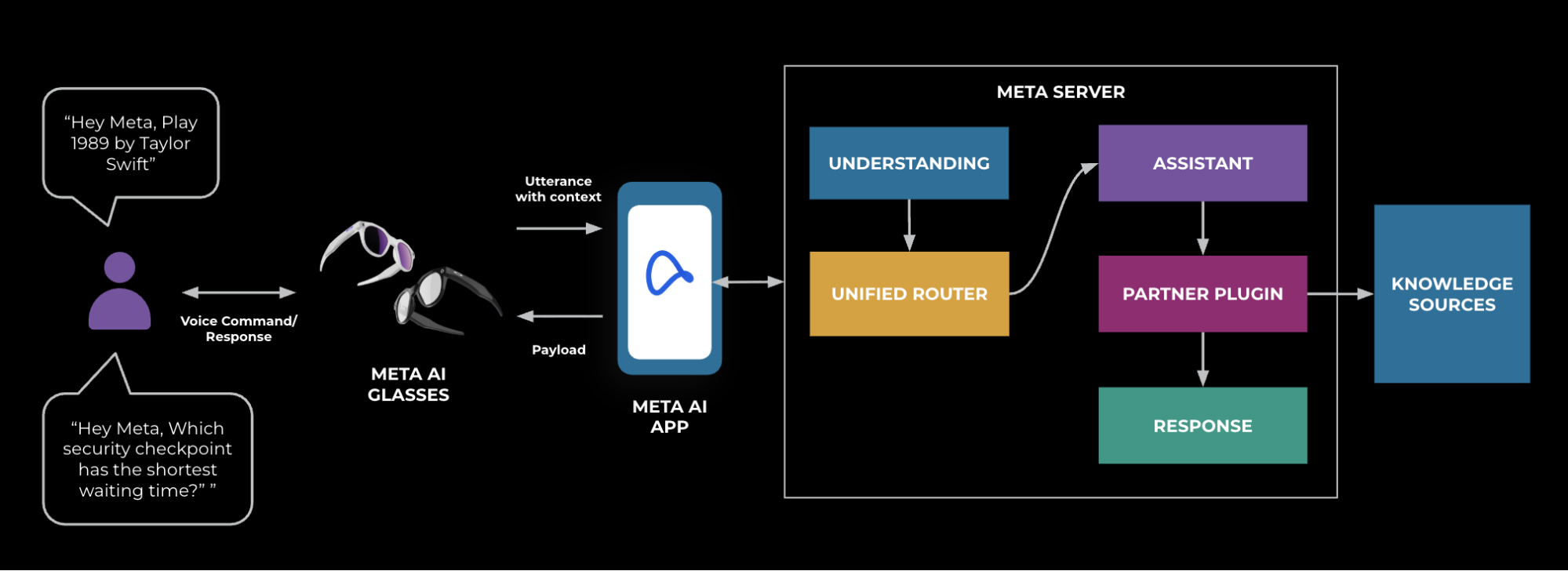
An Overview of Meta’s Privacy-Aware Infrastructure
Meta’s PAI sits at the heart of our privacy strategy. PAI is a suite of infrastructure services, APIs, and monitoring systems designed to integrate privacy into every aspect of product development.
Addressing the challenges listed in the section above, it includes:
- Enhanced observability: Automated data detection through advanced scanning and tagging identifies relevant data at the point of ingestion. This is further strengthened by data-lineage tracking, which maintains a real-time map of data origins, propagation paths, and usage—providing comprehensive visibility into how data flows across systems.
- Efficient privacy controls: Policy-enforcement APIs to programmatically enforce privacy constraints at the data storage, processing, and access layers. Policy automation that embeds regional and global requirements into automated checks and workflow constraints.
- Scalability: Supports thousands of microservices and product teams across Meta’s vast ecosystem.
PAI empowers engineers to innovate while automatically ensuring policy adherence and safety. Figure 2 summarizes this lifecycle and highlights the Discover stage we focus on below.
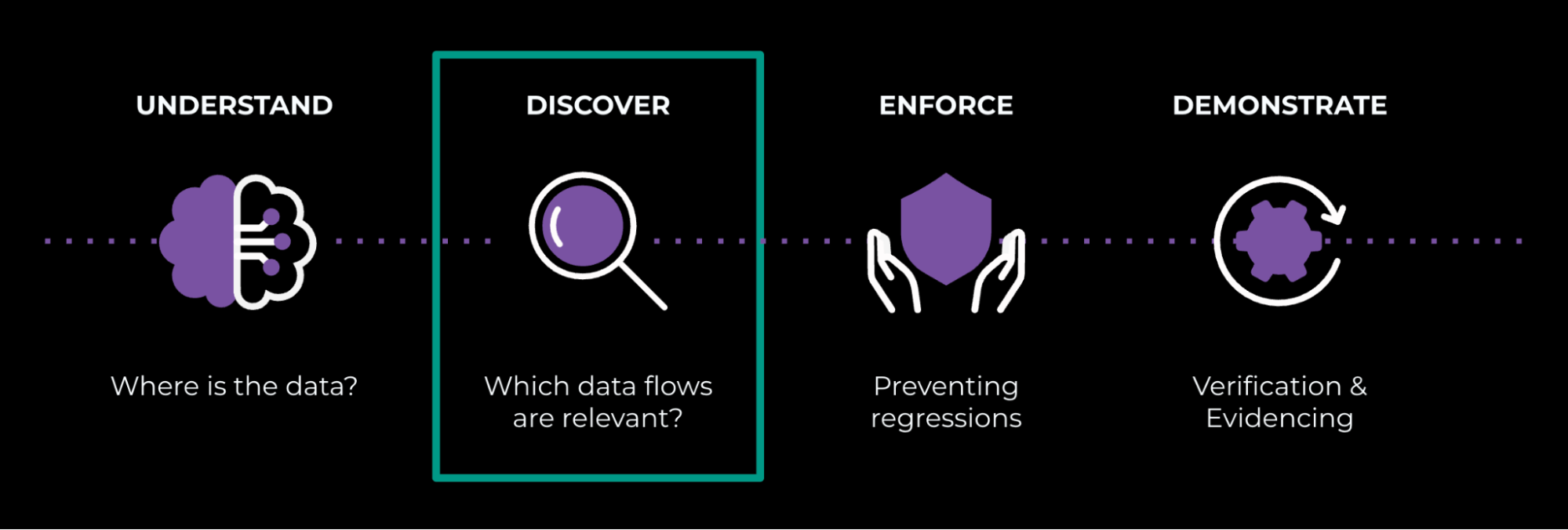
A Deep Dive Into the “Discover” Stage of Our PAI
One of PAI’s most transformative technologies is our approach to data lineage at scale. Our data lineage system continuously tracks and maps data flows across the entire infrastructure. While we discussed the technical foundations in our prior blog post on how Meta discovers data flows via lineage at scale, here we’ll explore a new perspective — highlighting how we’ve adapted our lineage capabilities to meet the unique challenges of GenAI’s rapidly evolving environment.
Meta’s vast scale and diverse ecosystem of systems present significant challenges for observing data lineage. Our lineage solution must operate across millions of data and code assets, spanning hundreds of platforms and a wide array of programming languages.
Let’s take a look at how this works.
Collect Cross-Stack Lineage for Interaction Data
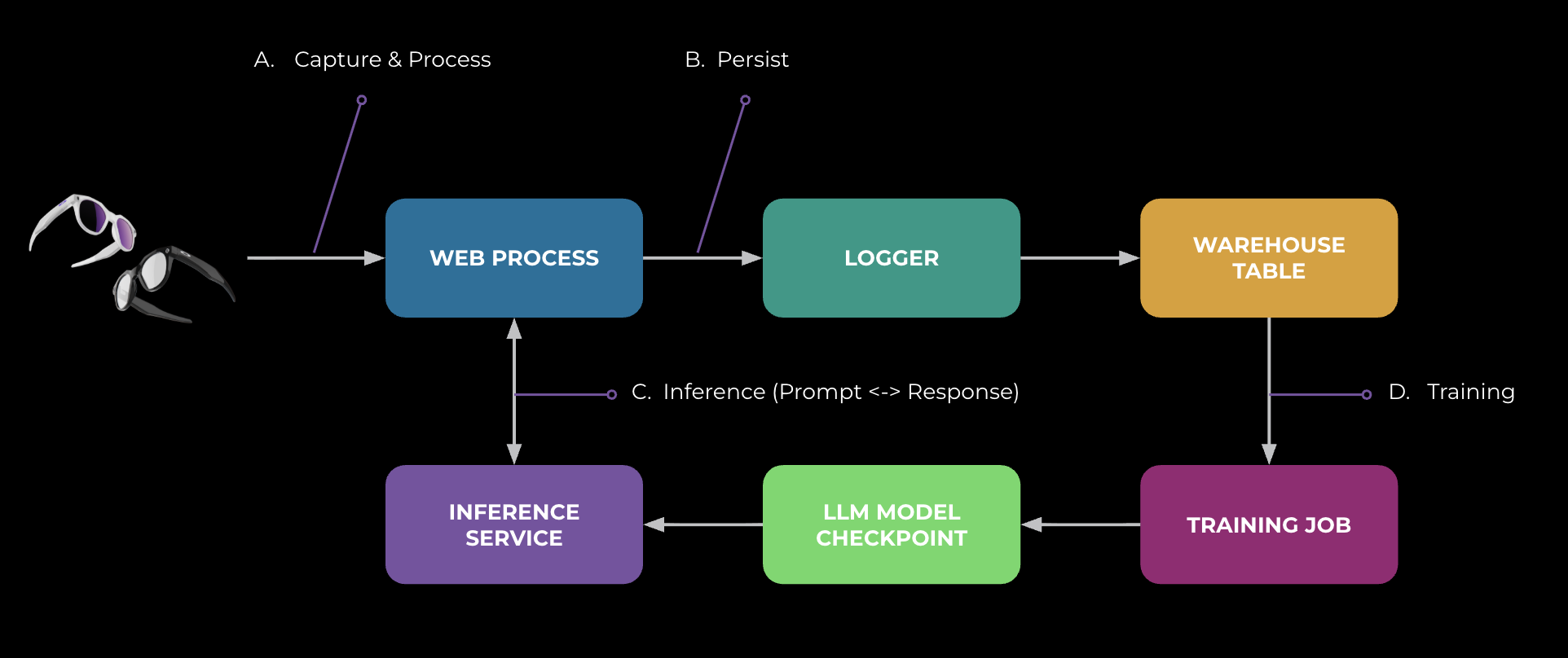
To maintain the privacy requirements for the data under consideration — for example, for user-interaction data from the scenario above with our AI glasses — we need a complete map of its movement. This traceability is what cross-stack lineage provides, as illustrated in Figure 3:
- [A] Within web: We capture data flows as the interaction data enters Meta’s web servers and further downstream between web components with privacy probes, so we know exactly what is collected and how it’s processed.
- [B] Web -> logger -> warehouse: When the web processing persists data, lineage tracks the logger that writes to the data-warehouse tables. Then, when the data is batch-processed downstream, we parse logger configs, SQL queries, and processing logs to extract data lineage.
- [C] Web <> inference: For large language model (LLM) calls, we collect lineage signals at service/RPC boundaries; for example, which model checkpoints are invoked, what are the inputs, and what are the responses returned to the app.
- [D] Warehouse -> training: Finally, lineage links warehouse tables into training jobs and the checkpoints they produce. This boundary is where we can enforce and demonstrate privacy requirements regarding the purposes that are allowed.
PAI collects these lineage signals crossing all stacks, including web probes, logger, batch-processing lineage, RPC lineage, and training manifests. Together they form an end-to-end graph for interaction data. Figure 4 shows this graph. With this visibility, we can reason about privacy in concrete terms: We know exactly which systems are involved and which ones aren’t. That clarity is what enables us to enforce data flow at boundaries and prove policy adherence.
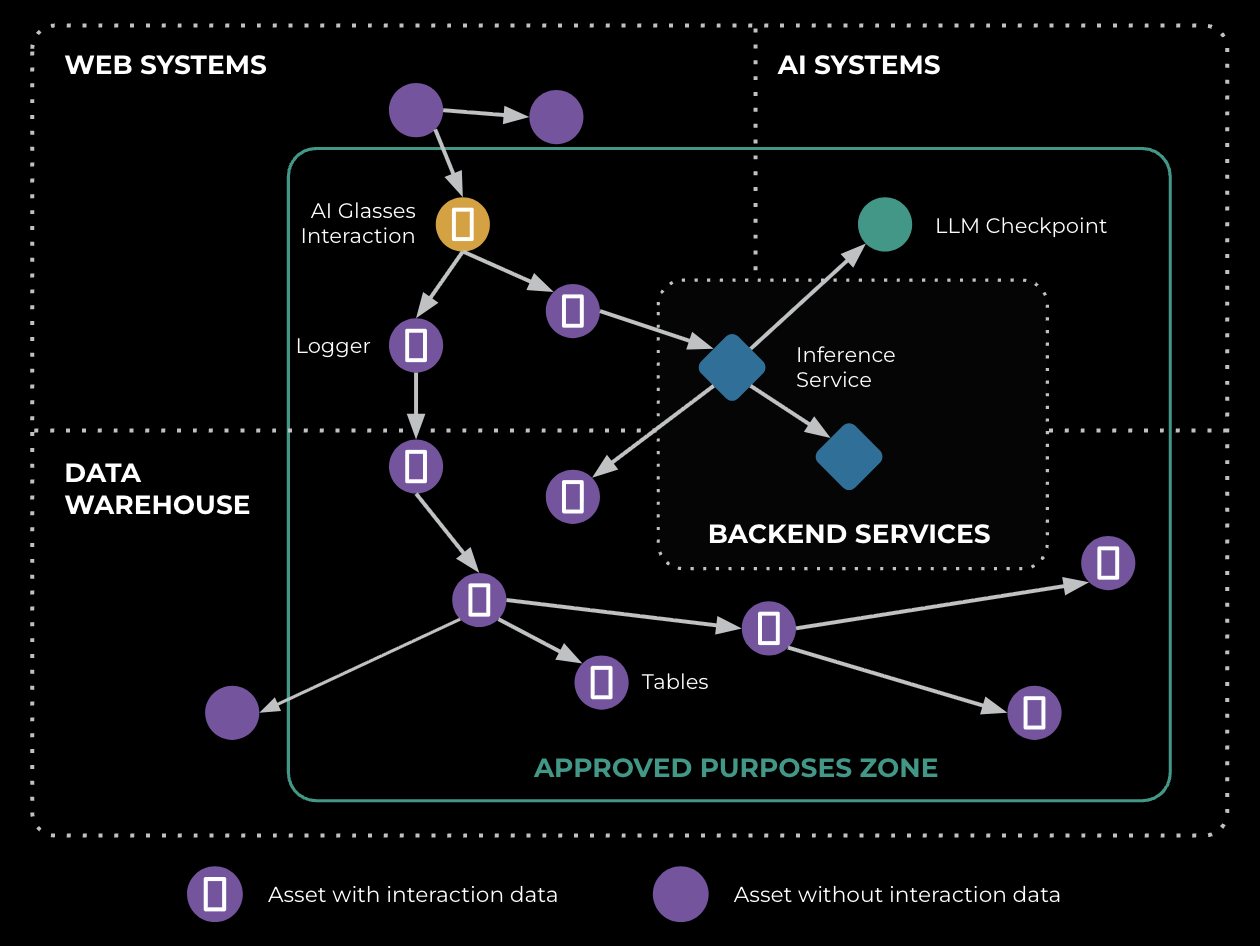
Building Comprehensive Lineage Observability
A sound lineage-observability system must catch all actual data flows or I/O operations comprehensively when data is processed. To achieve that we:
- Capture and link all read operations to the write operation: When we write a data asset, we ensure that we log all relevant write operations with the same correlation key as the one used for the read operation. We perform this logging for both SQL and non-SQL queries, as well as when I/O operations occur in a distributed manner.
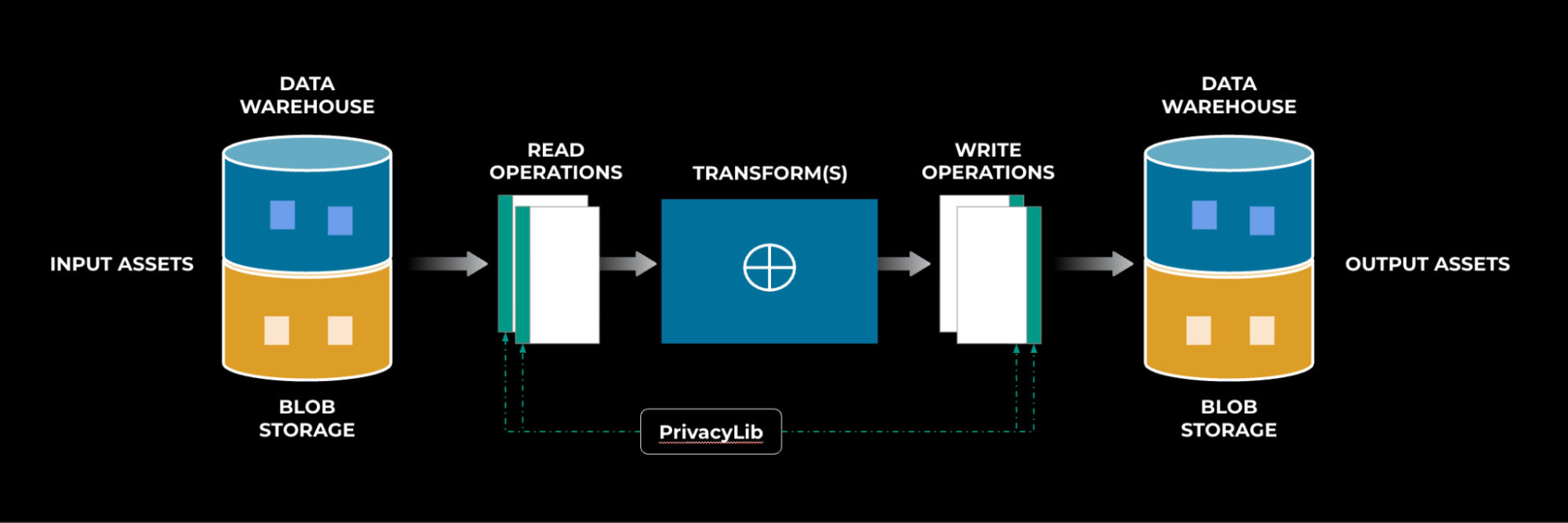
- Create a common privacy library to log data flow information: Our privacy library (PrivacyLib) is designed to initialize and propagate privacy policies, offer a generic abstraction for diverse operations (e.g. reads, writes, remote calls), and standardize extensions such as logging. Figure 5 illustrates how PrivacyLib is being used to link reads and writes across systems.
- Place library integration points in all involved data systems at Meta: We have integrated the library into all relevant data systems, implemented it in various programming languages, and ensured comprehensive coverage of I/O operations.
From Lineage to Proof for AI Glasses
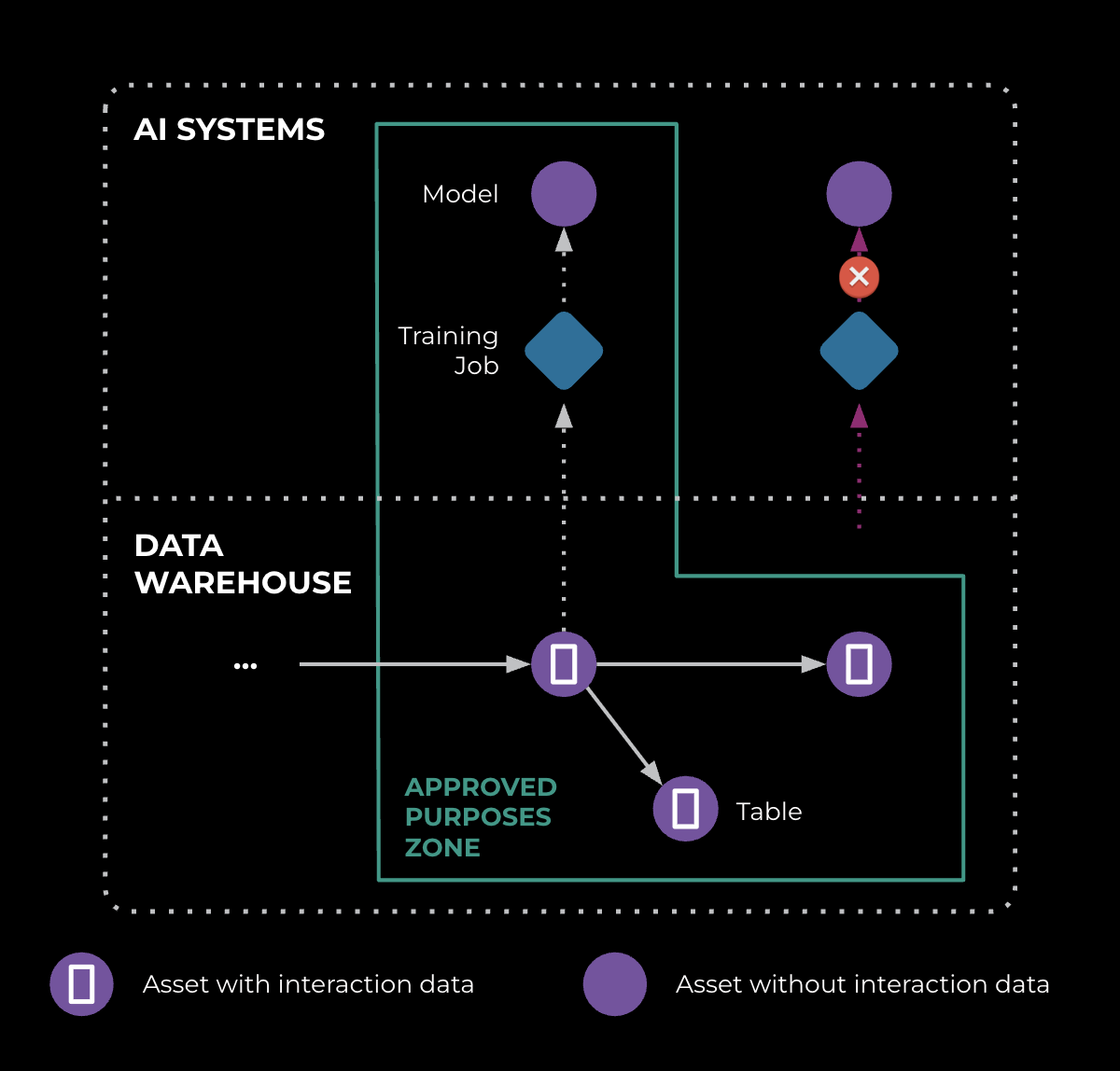
Data lineage tells us which systems process AI-glasses-interaction data. Based on that, we can protect the data in the following manner:
- We use lineage to guide the placement of Policy Zones, protecting interaction data.
- We start the training job for a model using a data asset in this zone only if all training-data assets are permitted for this purpose; otherwise, we remediate it.
- Finally, our verifiers watch these edges over time, so that any new or changed data-processing jobs are identified early during feature development.
As shown in Figure 6, this set of workflows is how we transform lineage into protection: place Policy Zones, block boundary crossings, and continuously prove it.
Zooming out: Privacy-Safe Data Across the GenAI Lifecycle
Scaling privacy from early prototypes to global rollouts requires infrastructure that adapts across products, regions, and evolving AI capabilities. PAI’s data understanding, data flow lineage, and policy enforcement facilitate safe and conformant data flows. This infrastructure enables Meta to launch products such as ourAI glasses confidently at a global scale, providing users with rich, personalized experiences powered by GenAI, while ensuring transparent and verifiable privacy guarantees.
Key Takeaways: How PAI Scales GenAI Privacy
Meta’s approach to privacy is straightforward: scale the infrastructure, not just the rules. By embedding PAI technologies including data lineage into the stack, Meta empowers engineers to deliver the next wave of GenAI products safely, quickly, and globally.
- Lightning-fast advancements from GenAI and its powered products bring new privacy and policy challenges that require rapid development of privacy-aware infrastructure.
- Privacy Aware Infrastructure (PAI) provides reusable workflows (Understand -> Discover -> Enforce -> Demonstrate) that scale privacy enforcement for GenAI products as well.
- Scalable data lineage technology facilitates privacy controls by giving us auditable, real-time insight into every data flow.
- Automatic guardrails and instant development feedback help product teams move faster and safer, with lower friction..
As GenAI Evolves, So Does Privacy
Scaling privacy for GenAI is an ongoing journey. As AI capabilities advance, so do the complexity and expectations around privacy protection. Meta’s PAI is evolving in step—integrating smarter lineage analysis and increasingly developer-friendly tools to meet these new demands.
As GenAI ushers in the next era of digital experiences, our focus on privacy remains strong. By scaling privacy infrastructure as a product enabler, not a barrier, Meta is laying the groundwork for responsible AI-product innovation.
Interested in learning more? Follow the Engineering at Meta blog on Facebook and stay engaged in the evolving dialogue on infrastructure for responsible innovation.
Acknowledgements
The authors would like to acknowledge the contributions of many current and former Meta employees who have played a crucial role in developing privacy infrastructure over the years. In particular, we would like to extend special thanks to (in last name alphabetical order): Taha Bekir Eren, Abhishek Binwal, Sergey Doroshenko, Rajkishan Gunasekaran, Ranjit Gupta, Jason Hendrickson, Kendall Hopkins, Aleksandar Ilic, Gabriela Jacques da Silva, Anuja Jaiswal, Joel Krebs, Vasileios Lakafosis, Tim LaRose, Yang Liu, Rishab Mangla, Komal Mangtani, Diana Marsala, Sushaant Mujoo, Andrew Nechayev, Alex Ponomarenko, Peter Prelich, Ramnath Krishna Prasad, Benjamin Renard, Hannes Roth, Christy Sauper, David Taieb, Vitalii Tsybulnyk, Pieter Viljoen, Lucas Waye, Yizhou Yan, Danlei Yang, Hanzhi Zhang, and Adrian Zgorzalek.
We would also like to express our gratitude to all reviewers of this post, including (in last name alphabetical order): Albert Abdrashitov, Jennifer Billock, Jordan Fieulleteau, Ahmed Fouad, Angie Galloway, Xenia Habekoss, Kati London, Koosh Orandi, Brianna O’Steen, Zef RosnBrick, Tobias Speckbacher, and Emil Vazquez.
We would like to especially thank Jonathan Bergeron for overseeing the effort and providing all of the guidance and valuable feedback, and Supriya Anand and Chloe Lu for pulling required support together to make this blog post happen.








