
Caches help reduce latency, scale read-heavy workloads, and save cost. They are literally everywhere. Caches run on your phone and in your browser. For example, CDNs and DNS are essentially geo-replicated caches. It’s thanks to many caches working behind the scenes that you can read this blog post right now.
Phil Karlton famously said, “There are only two hard things in computer science: cache invalidation and naming things.” If you have ever worked on a cache that uses invalidations, chances are you have run into the annoying problem of cache inconsistency.
At Meta, we operate some of the largest cache deployments in the world, including TAO and Memcache. Over the years, we’ve improved TAO’s cache consistency by one measure, from 99.9999 percent (six nines) to 99.99999999 percent (10 nines).
When it comes to cache invalidation, we believe we now have an effective solution to bridge the gap between theory and practice. The principle and methodology in this blog post apply broadly to most, if not all, cache services at any scale. It does so whether you are caching Postgres data in Redis or maintaining a disaggregated materialization.
We want to help reduce the number of cache invalidation issues that engineers have to deal with and help make all caches with invalidations more consistent.
Defining cache invalidation and cache consistency
By definition, a cache doesn’t hold the source of truth of your data (e.g., a database). Cache invalidation describes the process of actively invalidating stale cache entries when data in the source of truth mutates. If a cache invalidation gets mishandled, it can indefinitely leave inconsistent values in the cache that are different from what’s in the source of truth.
Cache invalidation involves an action that has to be carried out by something other than the cache itself. Something (e.g., a client or a pub/sub system) needs to tell the cache that a mutation happened. A cache that solely depends on time to live (TTL) to maintain its freshness contains no cache invalidations and, as such, lies out of scope for this discussion. For the rest of this post, we’ll assume the presence of cache invalidation.
Why is this seemingly straightforward process considered such a difficult problem in computer science? Here’s a simple example of how a cache inconsistency could be introduced:
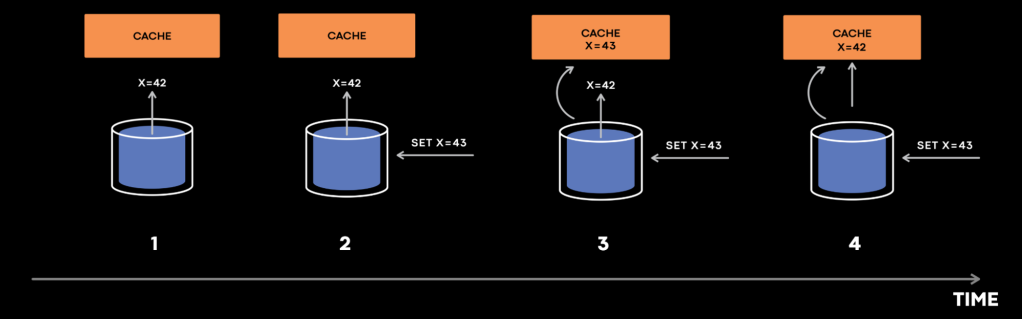
The cache first tries to fill x from the database. But before the reply “x=42” reaches the cache host, someone mutates x to 43. The cache invalidation event for “x=43” arrives at the cache host first, setting x to 43. Finally, “x=42” in the cache fill reply gets to the cache, setting x to 42. Now we have “x=43” in the database and “x=42” in the cache indefinitely.
There are different ways to solve this problem, one of which involves maintaining a version field. This allows us to perform conflict resolution, as older data should never overwrite newer data. But what if the cache entry “x=43 @version=2” gets evicted from cache before “x=42” arrives? In that case, the cache host would lose knowledge of the newer data.
The challenge of cache invalidation arises not only from the complexity of invalidation protocols, but also from monitoring cache consistency and determining why these cache inconsistencies occur. Designing a consistent cache is very different from operating a consistent cache — much like designing Paxos, where the protocol is different from building Paxos that actually works in production.
Why do we care about cache consistency at all?
Do we have to solve this intricate cache invalidation problem? Yes. In some cases, cache inconsistencies are almost as bad as data loss on a database. From the user’s perspective, it can even be indistinguishable from data loss.
Let’s examine another example of how cache inconsistencies can lead to split-brain. A messaging use case at Meta stores its mapping from user to primary storage in TAO. It performs shuffling frequently to keep the user’s primary message storage close to where the user accesses Meta. Every time you send a message to someone, behind the scenes, the system queries TAO to find out where to store the message. Many years ago, when TAO was less consistent, some TAO replicas would have inconsistent data after reshuffling, as illustrated in the example below.
Imagine that after shuffling Alice’s primary message store from region 2 to region 1, two people, Bob and Mary, both sent messages to Alice. When Bob sent a message to Alice, the system queried the TAO replica in a region close to where Bob lives and sent the message to region 1. When Mary sent a message to Alice, it queried the TAO replica in a region close to where Mary lives, hit the inconsistent TAO replica, and sent the message to region 2. Mary and Bob sent their messages to different regions, and neither region/store had a complete copy of Alice’s messages.

A mental model of cache invalidation
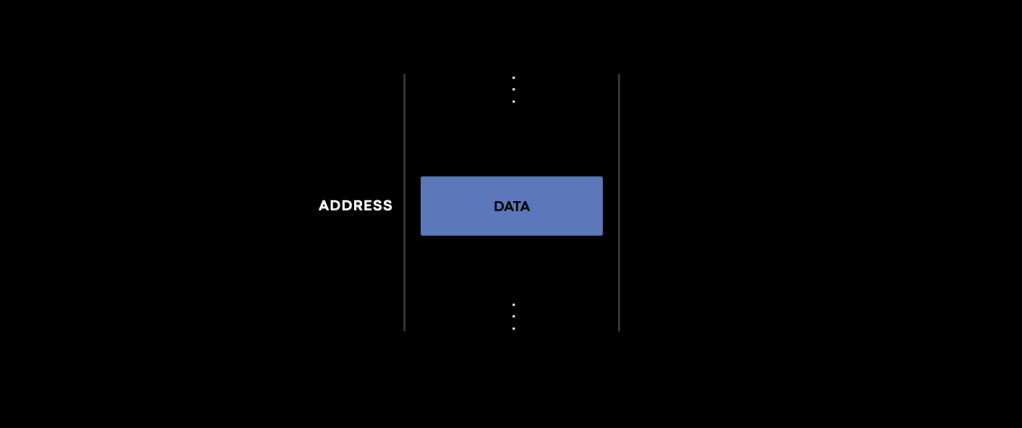
Understanding the unique challenges of cache invalidation is particularly challenging. Let’s start with a simple mental model. A cache, at its very core, is a stateful service that stores data in an addressable storage medium. Distributed systems are essentially state machines. If every state transition is performed correctly, we will have a distributed system that works as expected. Otherwise, we’ll have a problem. So, the key question is: What’s changing the data for a stateful service?
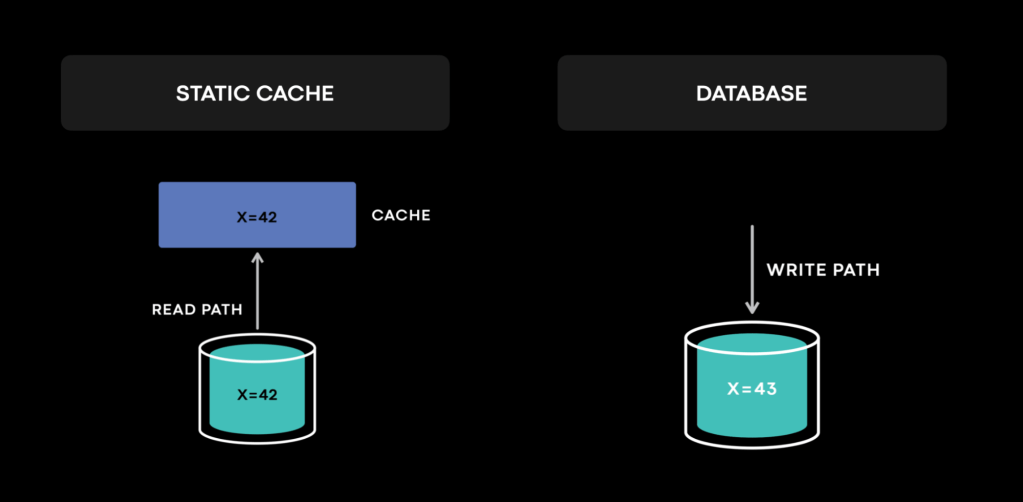
A static cache has a very simple cache model (e.g., a simplified CDN fits this model). Data is immutable. No cache invalidations. For databases, data gets mutated only on writes (or replications). We often have logs for almost every state change for a database. Whenever an anomaly occurs, the logs can help us understand what happened, narrow down the problem, and identify the issue. Building a fault-tolerant distributed database (which is already difficult) comes with its own set of unique challenges. These are just simplified mental models. We do not intend to minimize anyone’s struggles.
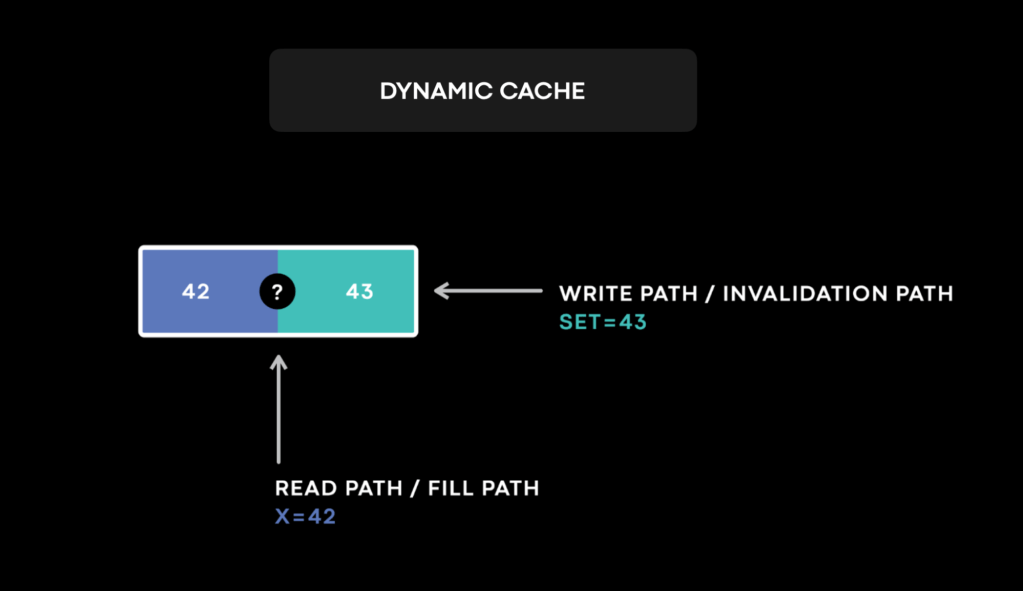
For a dynamic cache, like TAO and Memcache, data gets mutated on both read (cache fill) and write (cache invalidation) paths. This exact conjunction makes many race conditions possible and cache invalidation a difficult problem. Data in cache is not durable, which means that sometimes version information that is important for conflict resolution can get evicted. In combining all these characteristics, a dynamic cache produces race conditions beyond your wildest imagination.
And it’s almost impractical to log and trace every cache state change. A cache often gets introduced to scale a read-heavy workload. It implies that most of the cache state changes transpire from the cache fill path. Take TAO, for example. It serves more than one quadrillion queries a day. Even if the cache hit rate reaches 99 percent, we would be doing more than 10 trillion cache fills a day. Logging and tracing all the cache state changes would turn a read-heavy cache workload to an extremely write-heavy workload for the logging system. Debugging a distributed system already presents significant challenges. Debugging a distributed system — in this case, a distributed cache — without logs or traces for cache state changes could be impossible.
Despite these challenges, we improved TAO’s cache consistency, by one measure, from 99.9999 to 99.99999999 over the years. In the rest of the post, we will explain how we did it and highlight some future work.
Reliable consistency observability
To solve cache invalidation and cache consistency, the first step involves measurement. We want to measure cache consistency and sound an alarm when there are inconsistent entries in the cache. The measurement can’t contain any false positives. Human brains can easily tune out noises. If any false positives existed, people would quickly learn to ignore it and the metric would lose trust and become useless. We also need the measurement to be precise, as we talk about measuring up to more than 10 nines of consistency. If a consistency fix is landed, we want to assure we can quantitatively measure its improvement.
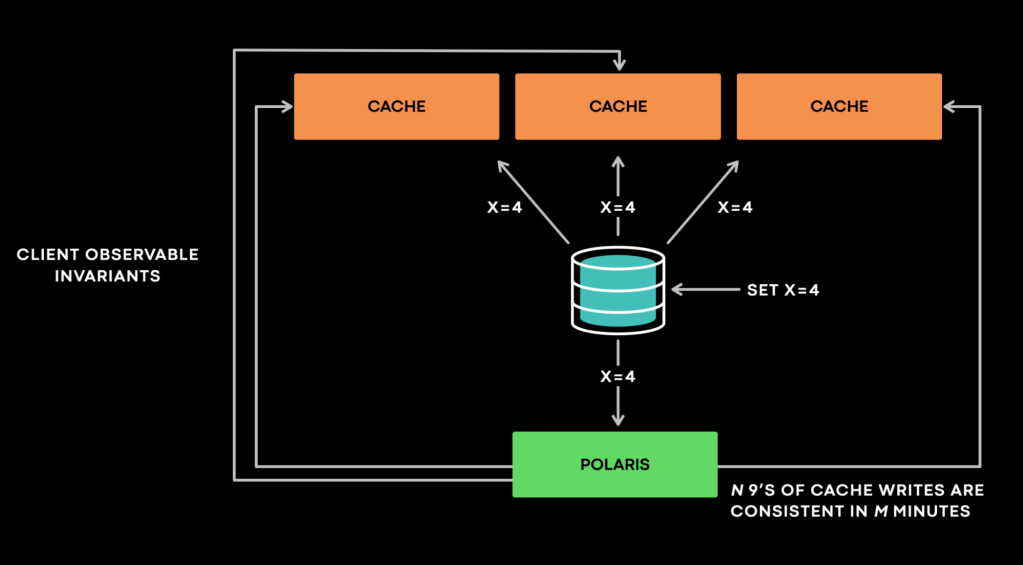
To solve the measurement problem, we built a service called Polaris. For any anomaly in a stateful service, it is an anomaly only if clients can observe it one way or the other. Otherwise, we argue that it doesn’t matter at all. Based on this principle, Polaris focuses on measuring the violations of client-observable invariants.
At a high level, Polaris interacts with a stateful service as a client and assumes no knowledge of the service internals. This allows it to be generic. We have dozens of Polaris integrations at Meta. “Cache should eventually be consistent with the database” is a typical client-observable invariant that Polaris monitors, especially in the presence of asynchronous cache invalidation. In this case, Polaris pretends to be a cache server and receives cache invalidation events. For example, if Polaris receives an invalidation event that says “x=4 @version 4,” it then queries all cache replicas as a client to verify whether any violations of the invariant occur. If one cache replica returns “x=3 @version 3,” Polaris flags it as inconsistent and requeues the sample to later check it against the same target cache host. Polaris reports inconsistencies at certain timescales, e.g., one minute, five minutes or 10 minutes. If this sample still shows as inconsistent after one minute, Polaris reports it as an inconsistency for the corresponding timescale.
This multi-timescale design not only allows Polaris to have multiple queues internally to implement backoff and retries efficiently, but it’s also essential for preventing it from producing false positives.
Let’s take a look at a more interesting example: Say Polaris receives an invalidation with “x=4 @version 4.” But when it queries a cache replica, it gets a reply saying x doesn’t exist. It’s not clear whether Polaris should flag this as an inconsistency. It’s possible that x was invisible at version 3, the version 4 write is the latest write on the key, and it’s indeed a cache inconsistency. It’s also possible that there’s a version 5 write that deletes the key x, and perhaps Polaris is just seeing a more recent view of the data than what’s in the invalidation event.
To disambiguate between these two cases, we would need to bypass cache and check what’s in the database. Queries that bypass cache are very compute-intensive. They also expose the database to risks — not surprisingly because protecting the database and scaling a read-heavy workload is one of the most common use cases for caches. So, we can’t send too many queries to the system that bypasses the cache. Polaris solves this problem by delaying performing the compute-intensive operation until an inconsistent sample crosses the reporting timescale (e.g., one minute or five minutes). Real cache inconsistencies and racing write operations on the same key are rare. As a result, retrying the consistency check (before it crosses the next timescale boundary) helps remove most of the demand to perform these cache bypass queries.
We also added a special flag to the query that Polaris sends to the cache server. So, in the reply, Polaris would know whether the target cache server has seen and processed the cache invalidation event. This bit of information enables Polaris to distinguish between transient cache inconsistencies (usually caused by replication/invalidation lag) and “permanent” cache inconsistencies — when a stale value is in cache indefinitely after processing the latest invalidation event.
Polaris produces a metric that looks like “N nines of cache writes are consistent in M minutes.” At the beginning of the post, we mentioned that by one measure we improved TAO’s cache consistency from 99.9999 percent to 99.99999999 percent. Polaris provided these numbers for the five minute timescale. In other words, 99.99999999 percent of cache writes are consistent within five minutes. Less than 1 out of 10 billion cache writes would be inconsistent in TAO after five minutes.
We deploy Polaris as a separate service so that it will scale independently from the production service and its workload. If we want to measure up to more nines, we can just increase Polaris throughput or perform aggregation over a longer time window.
Consistency tracing
In most diagrams, we use one simple box to represent cache. In reality, it looks more like the following, even after omitting many dependencies and data flows:
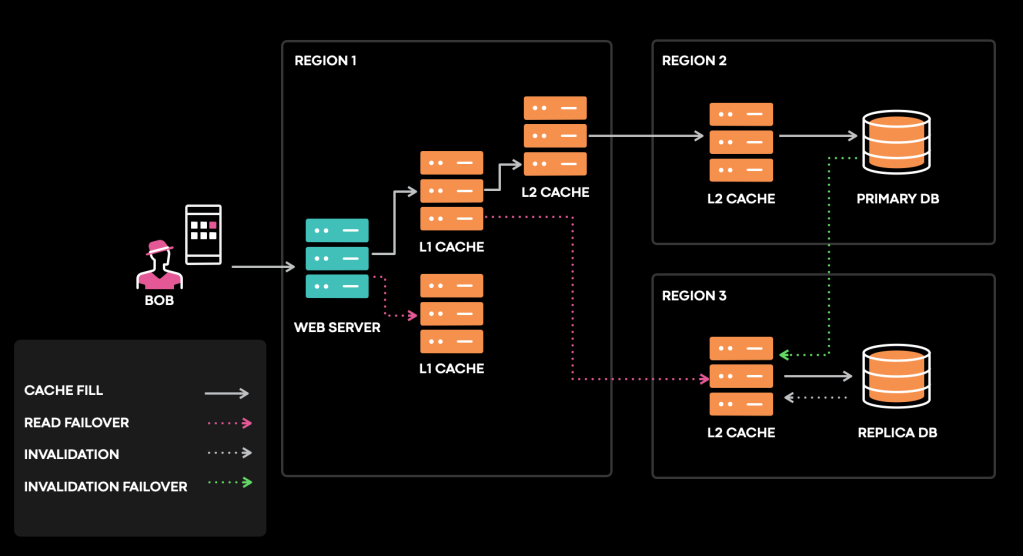
Caches can fill from different upstreams at different points in time, within or across regions. Promotions, shard moves, failure recoveries, network partitions, and hardware failures can all potentially trigger bugs that lead to cache inconsistencies.
However, as mentioned earlier, logging and tracing every cache data change is almost impractical. But what if we only log and trace cache mutations where and when cache inconsistencies can get introduced (or cache invalidations can possibly be mishandled)? Within this massive and complex distributed system, where a single flaw in any component can lead to cache inconsistencies, is it possible to find a place where most if not all cache inconsistencies get introduced?
Our task becomes finding a simple solution to help us manage this complexity. We want to assess the entire cache consistency problem from a single cache server’s perspective. At the end of the day, an inconsistency has to materialize on a cache server. From its perspective, it cares about only a few aspects:
- Did it receive the invalidate?
- Did it process the invalidate correctly?
- Did the item become inconsistent afterwards?
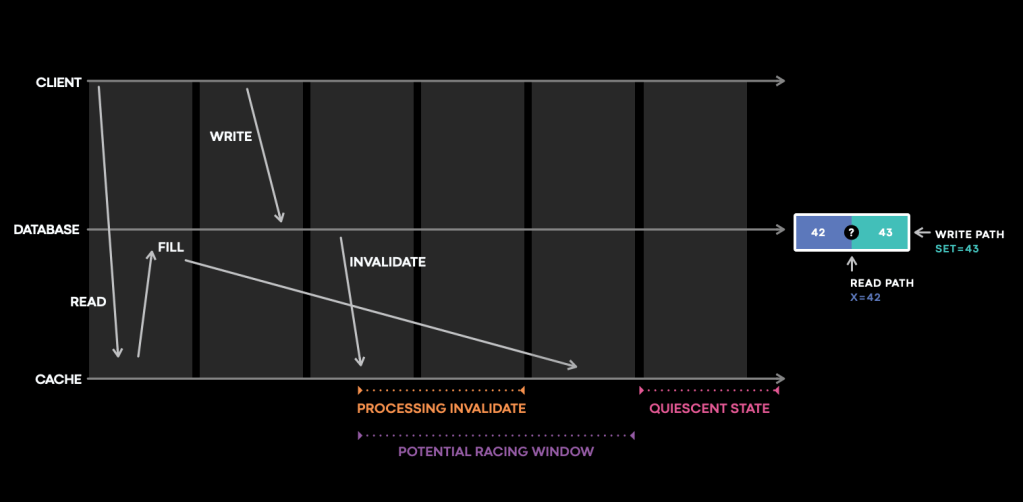
This is the same example we explained at the beginning of the post, now illustrated on a space-time diagram. If we focus on the cache host timeline at the bottom, we see that after a client write, there’s a window in which both the invalidation and the cache fill can race to update the cache. After a while, the cache will be in a quiescent state. Cache fills can still happen in high volume in this state, but from a consistency perspective, it holds less interest, given there are no writes and it’s reduced to a static cache.
We built a stateful tracing library that logs and traces cache mutations in this small purple window, where all the interesting and complicated interactions trigger bugs that lead to cache inconsistencies. It covers cache evictions, and even the absence of the log can tell us if the invalidate event never arrives. It’s embedded into a few major cache services and throughout the invalidation pipeline. It buffers an index of recently modified data, used to determine whether subsequent cache state changes should be logged. And it supports code tracing, so we’ll know the exact code path for every traced query.
This methodology has helped us find and fix many flaws. It offers a systemic and much more scalable approach to diagnosing cache inconsistencies. It has proved to be very effective.
A real bug we found and fixed this year
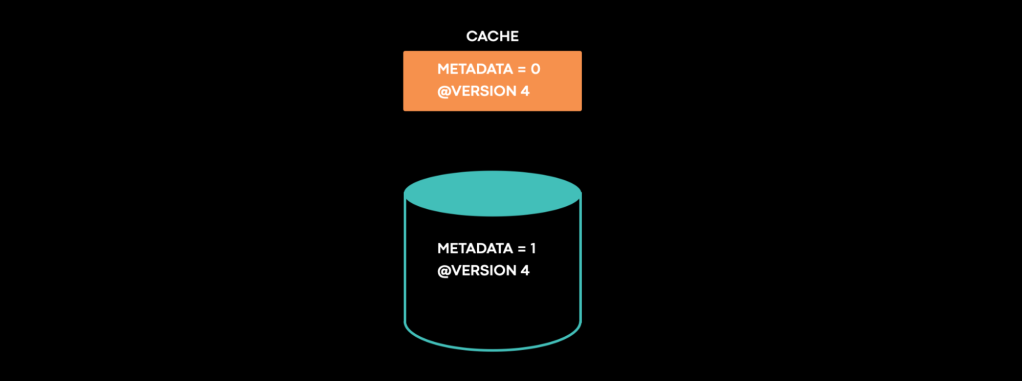
In one system, we version each piece of data for ordering and conflict resolution. In this case, we observed “metadata=0 @version 4” in the cache, while the database contained “metadata=1 @version 4.” The cache stayed inconsistent indefinitely. This state should have been impossible. Pause for a second and consider: How would you approach this problem? How nice would it be if we got the complete timeline of every single step that led to the final inconsistent state?
Consistency tracing provided exactly the timeline we needed.
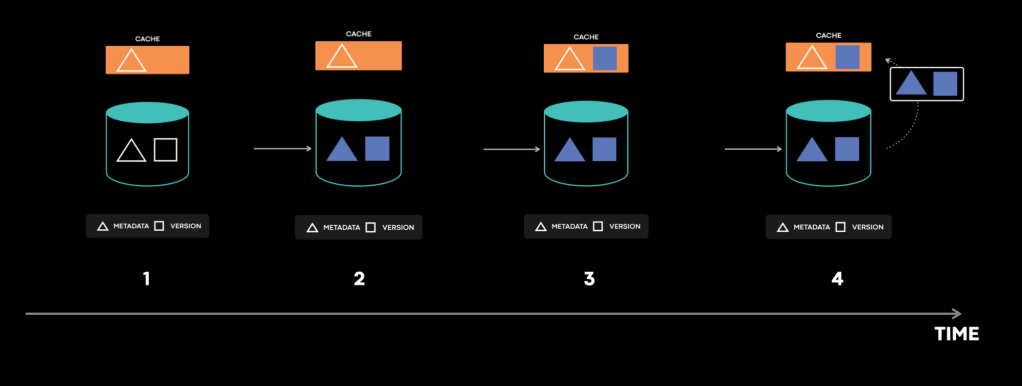
In the system, a very rare operation updates two tables of the underlying database transactionally — the metadata table and the version table.
Based on consistency tracing, we know the following happened:
-
- The cache tried to fill the metadata with version.
- In the first round, the cache first filled the old metadata.
- Next, a write transaction updated both the metadata table and the version table atomically.
- In the second round, the cache filled the new version data. Here, the cache fill operation interleaved with the database transaction. It happens very rarely because the racing window is tiny. You might be thinking, “This is the bug.”. No. Actually, so far everything worked as expected because cache invalidation is supposed to bring the cache to a consistent state.
- Later, cache invalidation came during an attempt to update the cache entry to both the new metadata and the new version. This almost always works, but this time it didn’t.
- The cache invalidation ran into a rare transient error on the cache host, which triggered the error handling code.
- The error handler dropped the item in cache. The pseudocode looks like this:
drop_cache(key, version);It says drop the item in cache, if its version is less than specified. However, the inconsistent cache item contained the latest version. So this code did nothing, leaving stale metadata in cache indefinitely. This is the bug. We simplified the example quite a bit here. The actual bug has even more intricacy, with database replication and cross region communication involved. The bug gets triggered only when all steps above occur and happen specifically in this sequence. The inconsistency gets triggered very rarely. The bug hides in the error handling code behind interleaving operations and transient errors.
Many years ago, finding the root cause of such a bug would take weeks from someone who knew the code and the service inside out, if they were lucky enough to find it at all. In this case, Polaris identified the anomaly and fired an alarm immediately. With information from consistency tracing, it took on-call engineers less than 30 minutes to locate the bug.
Future cache consistency work
We’ve shared how we made our caches more consistent with a generic, systemic, and scalable approach. Looking ahead, we want to get the consistency of all our caches as close to 100 percent as physically possible. Consistency for disaggregated secondary indices poses an interesting challenge. We are also measuring and meaningfully improving cache consistency at read time. Finally, we are building a high-level consistency API for distributed systems — think of C++’s std::memory_order, but for distributed systems.








