
What the research is:
A first-of-its-kind study detailing our backbone management strategy to ensure high service performance throughout the COVID-19 pandemic. The pandemic moved most social interactions online and caused an unprecedented stress test on our global network infrastructure with tens of data center regions. At this scale, failures such as fiber cuts, router misconfigurations, and power outages are a frequent occurrence.
We ran a simulation system that identifies possible failures and quantifies their potential severity with a set of metrics that measure network risk. The risk metrics, in turn, guided operational decisions for capacity deployment. Coupled with traffic priority management and proactive capacity enhancement, our backbone resiliently withstood the COVID-19 stress test while achieving high service availability and low latency, and efficiently handled traffic surges.
How it works:
To satisfy the network’s service-level objectives (SLO), we started by defining a set of risk metrics around demand loss, availability, and latency stretch. All these metrics are computed with respect to possible failure scenarios in the network, which can be enumerated by going through all the components making up the network. The goal of the failure modeling is to estimate the likelihood of a failure scenario as well as the duration of the failure event. Each component failure is characterized by its mean time between failures and mean time to repair. These statistics are estimated based on a combination of historical data and clustering followed by Bayesian regression modeling on common features such as vendor, ownership, and geographical region.
Our risk simulation system periodically computes the aforementioned risk metrics. It works by taking a fresh snapshot of the network topology and demand and the set of failure scenarios to consider together with their failure characteristics as its input. Due to the high number of failure scenarios, each is sharded onto a number of worker jobs that run the same code as our SD-WAN controller to compute the traffic engineering decision for the given failure scenario. The decisions are aggregated to derive the risk metrics and then logged for continuous monitoring.
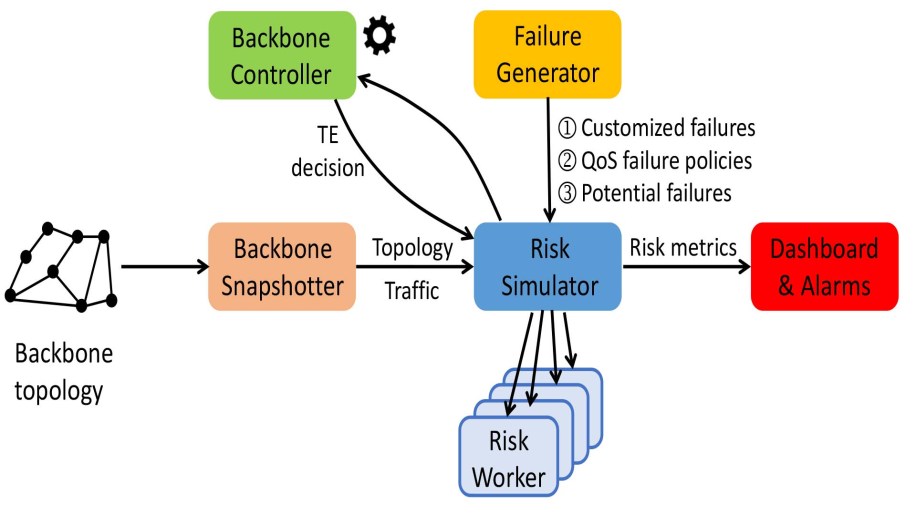
During the onset of COVID-19, the risk metrics reported a significant increase in demand loss (which captures the highest traffic loss across all simulated failure scenarios), a decrease in availability and increase in latency for all quality of service (QoS) classes. The risk metrics guided us to the possible failure scenarios that, were they to occur, would degrade the network operating conditions for certain regions. Capacity was proactively deployed to mitigate these risks. Another helpful technique was looking at the traffic flows from the regions at risk, differentiating the traffic by criticality and then downgrading the QoS to a lower priority. The QoS classes are, in order of importance, infrastructure control (class 1), user traffic (class 2), internal applications (class 3), and bulk data transfer (class 4). We downgraded a lot of latency-insensitive traffic from class 3 to class 4. Less capacity is thus needed to guarantee the same level of SLO.
Why it matters:
There is a long lead time of months to years for building up capacity for backbone networks. As such, network operators typically procure capacity based on estimated traffic growth. When COVID-19 hit, there was a significant unplanned ramp-up in traffic within a short period of time, stressing backbone infrastructure all across the world.
Facebook was able to react swiftly thanks to its risk-driven backbone management strategy. Leveraging the risk metrics computed by our simulation systems, we quickly identified the operational pain points and prioritized capacity enhancements to bring the network back to normal. Our experience has shown that a metrics-centric approach to backbone management could adapt to rare adverse external shock. We hope our research can help operators looking to build a more resilient network.
We would like to thank Ying Zhang, Guanqing Yan, Satyajeet Singh Ahuja, Alexander Nikolaidis, Soshant Bali, Bob Kamma and Gaya Nagarajan for their work on this project.
To learn more, watch our presentation at NSDI 2021.
Read the full paper:
A social network under social distancing: Risk-driven network management during COVID-19 and beyond



")




