
What the research is:
A first-of-its-kind study that details the scalable design, software implementation, and operations of Facebook’s data center routing design, based on Border Gateway Protocol (BGP). BGP was originally designed to interconnect autonomous internet service providers (ISPs) on the global internet. Highly scalable and widely acknowledged as an attractive choice for routing, BGP is the routing protocol that connects the entire internet. Similar to online map services for streets, BGP directs data packets, helping determine the most efficient route through a network.
Based on our experience implementing it into our data centers, BGP can form a robust routing foundation, but it requires tight codesign with the data center topology, configuration, switch software, and data center–wide operational pipeline. We devised this routing design for our data centers to build our network quickly and provide high availability for our services, while keeping the design itself scalable. We know failures happen in any large-scale system — hence, our routing design aims to minimize the impact of any potential failures.
How it works:
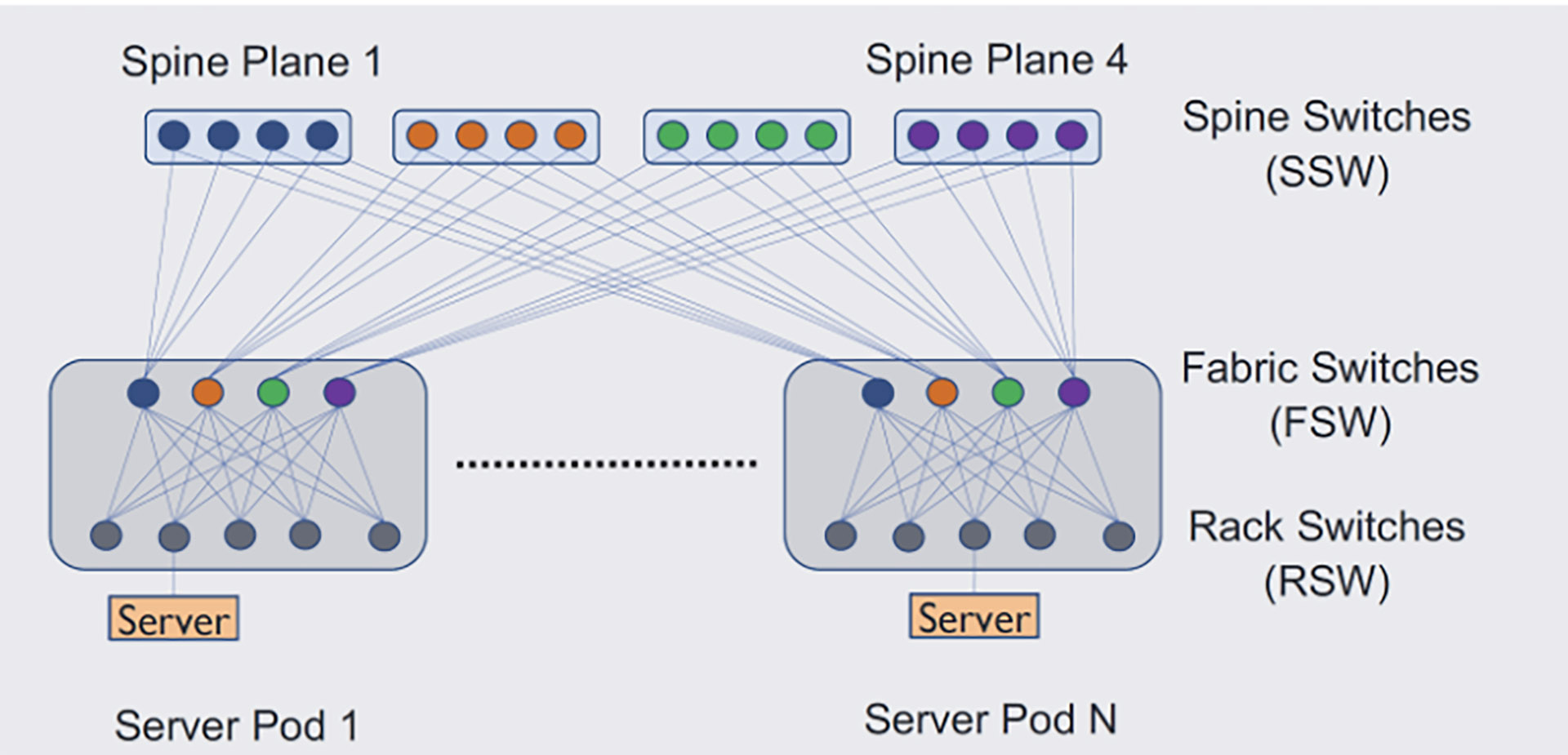
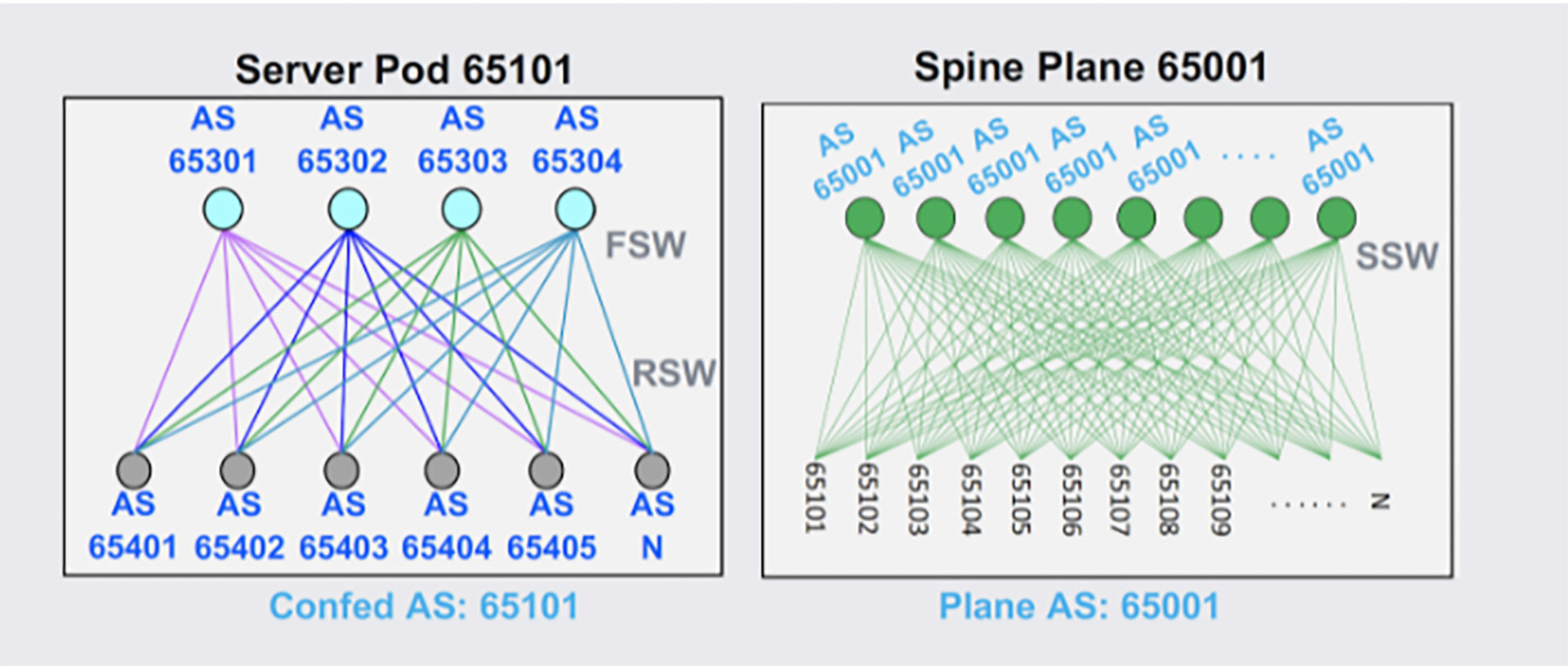
To achieve the goals we’d set, we had to go beyond using BGP as a mere routing protocol. The resulting design creates a baseline connectivity configuration on top of our existing scalable network topology. We employ a uniform AS numbering scheme that is reused across different data center fabrics, simplifying ASN management across data centers. We use hierarchical route summarization on all levels of the topology to scale to our data center sizes while ensuring that forwarding tables in hardware are small.
Our policy configuration is tightly integrated with our baseline connectivity configuration. Our policies ensure reliable communication using route propagation scopes and predefined backup paths for failures. They also allow us to maintain the network by seamlessly diverting traffic from problematic/faulty devices in a graceful fashion. Finally, they ensure that services remain reachable even when an instance of the service is added, removed, or migrated.
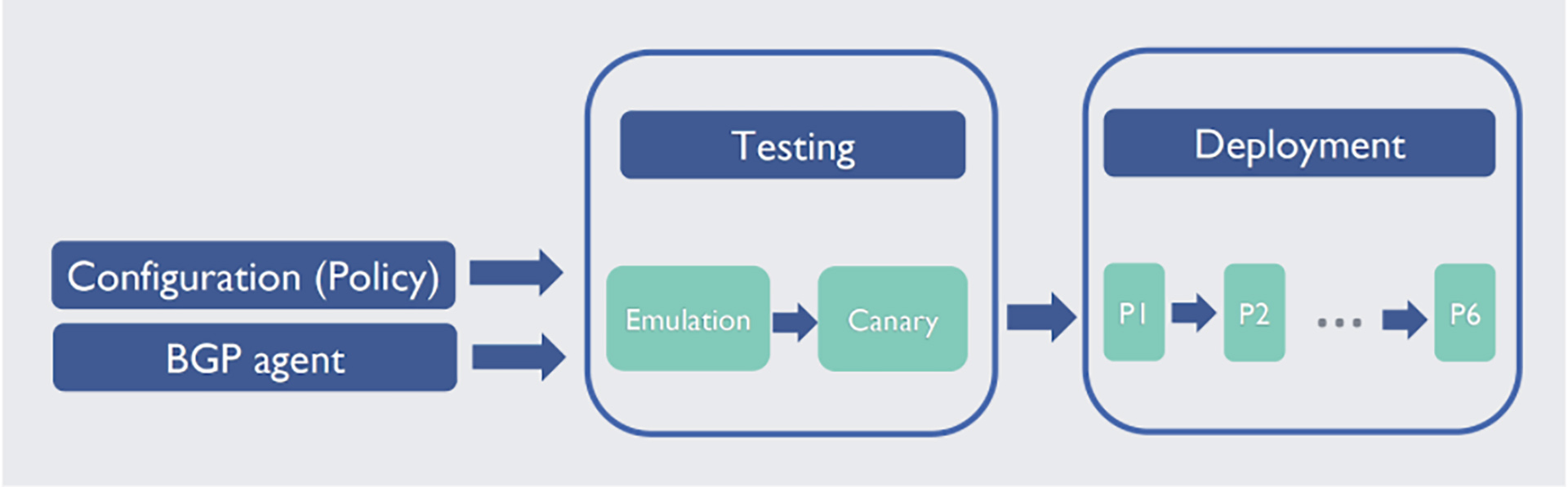
To support the growing scale and evolving routing requirements, our switch-level BGP agent needs periodic updates to add new features, optimization, and bug fixes. To optimize this process (i.e., to ensure fast, frequent changes to the network infrastructure to support good route processing performance), we implemented an in-house BGP agent. We keep the codebase simple and implement only the necessary protocol features required in our data center, but we do not deviate from the BGP specifications.
To minimize impact on production traffic while achieving high release velocity for the BGP agent, we built our own testing and incremental deployment framework, consisting of unit testing, emulation, and canary testing. We use a multi-phase deployment pipeline to push changes to agents.
Why it matters:
BGP has made serious inroads into data centers thanks to its scalability, extensive policy control, and proven track record of running the internet for a few decades. Data center operators are known to use BGP for routing, often in different ways. Yet, because data center requirements are very different from the internet, using BGP to achieve effective data center routing is much more complex.
Facebook’s BGP-based data center routing design marries the stringent requirements of data centers with BGP’s functionality. This design provides us with flexible control over routing and keeps the network reliable. Our in-house BGP software implementation and its testing and deployment pipelines allow us to treat BGP like any other software component, enabling fast incremental updates. Finally, our operational experience running BGP for more than two years across our data center fleet has influenced our current and ongoing routing design and operation. Our experience with BGP has shown that it’s an effective option for large-scale data centers. We hope sharing this research helps others who are looking for a similar solution.
To learn more, watch our presentation from NSDI 2021.








