")
Since 2010, we have offered Download Your Information to allow people who use our services to access a secure copy of the data they have shared with Facebook. In 2018, we announced our participation in the Data Transfer Project, a collaborative effort with Apple, Google, Microsoft, and Twitter to build a common way for people to transfer their data between online services. The goal of this project has been to make it easier for services of any size to securely make direct transfers for data portability from one service to another and to make the process simpler for the people who use these services.
Over the past year, an open source framework has been developed. Today, we are announcing a new tool on Facebook that allows people to transfer photos and videos directly from Facebook to Google Photos. We plan to expand this to other services in the near future. This tool will begin rolling out in Ireland today and will be available worldwide in early 2020.
The project
The mission of the Data Transfer Project is to create an open source, service-to-service data portability platform so that all individuals across the web can easily move their data between online service providers whenever they want. The project does this by providing an open source library that any service can use to run and manage direct transfers on behalf of users.
Rather than expecting every company to build its own system from scratch, this open source framework allows them to share any improvements in the framework as well as adapters and data models. For example, a company using the Data Transfer Project framework can send an existing data type to a new service by simply creating a new Data Transfer Project importer for that data type. That new importer can also be contributed back to the open source project, thereby allowing other companies to export to that new service, as well, with no additional technical work.
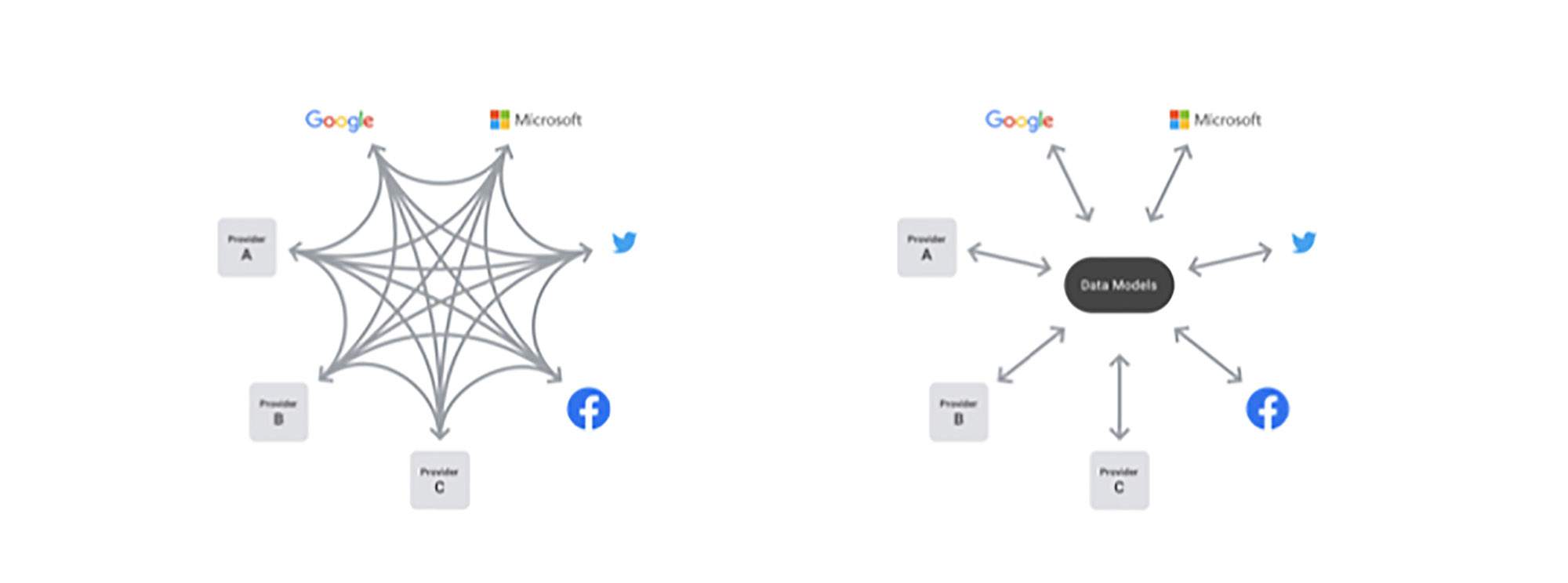
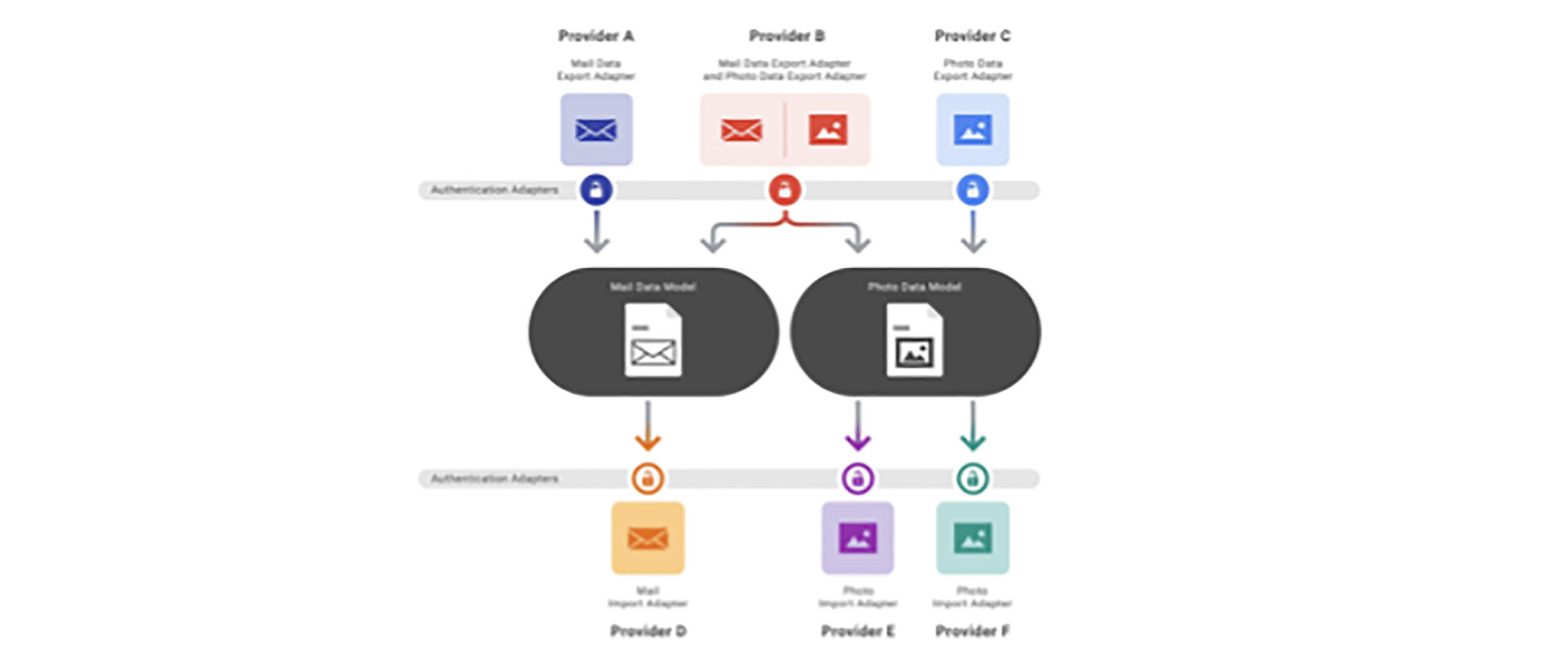
The Data Transfer Project comprises three main components:
- A set of shared data models to represent each vertical (i.e., photos, contacts, playlists)
- Adapters, which handle the authentication of a user to a service (normally OAuth) and the transformation of data to and from the shared data models (importers and exporters)
- A task management framework, which puts all the pieces together and handles the life cycle of a transfer job, including job creation and running the transfer
The Data Transfer Project can be run locally in memory for testing and by individuals who want to try out the code. The service is also highly extensible, which allows it to be deployed in cloud environments and as a back-end service in enterprise level infrastructure. There are public, open source extensions that allow the Data Transfer Project to be run on the Google Cloud Platform and Microsoft Azure cloud hosting providers. Deploying the Data Transfer Project at scale so that it would work seamlessly with our infrastructure-specific back-end services required some thoughtful engineering and design work.
Deploying the Data Transfer Project at Facebook
We’ve spent the past year building the foundation for the photo and video transfer tool we’re starting to release today. We’ve written our own proprietary extensions, which integrate with our tooling and allow us to operate a reliable service. We first needed to verify the security and reliability of the system. We then needed to build an easy-to-understand interface through which people can initiate transfers and monitor the status. Simultaneously, we also had to write various extensions to allow the open source code to communicate with that interface — as well as with our back-end systems.
Security
Any mechanism to send data outside of a service carries risk. We have put measures in place to mitigate these risks. For example, we use the commonly used protocol OAuth to authenticate people with the destination service. As we continue to add more services and data types, we needed to look at several factors. It’s important that the system request only the permissions required for the task at hand. Access to the destination service should end once the transfer is complete. Finally, transfers should only be created by the owner of the account. In order to verify this, we ask people to reenter their password before initiating a transfer. We also send an email to the registered account once a transfer has begun, which allows people a chance to stop the transfer if they change their mind or do not recognize the request.
Reliability
When there is a dependency between any two systems, it is important that each system respect the other’s capacity. For instance, if a person transfers thousands of photos at once, we need to ensure that the system receiving those photos is able to manage that input without overloading it or causing bottlenecks. This involves things like rate limiting, and gracefully handling downtime. The Data Transfer Project allows for configuration of custom retry strategies to handle different error messages. So, if we have hit the maximum number of requests per person within a given minute, the system can delay the next request so as to not overburden the other system.
Custom extensions
The open source code has the concept of a job store, but to take advantage of our existing infrastructure, we needed a custom version that can retrieve and modify portability jobs using our main entity store, TAO. This enables us to take advantage of TAO’s scalability and existing capabilities for indexing, caching, validation, and permissioning.
Additionally, we’ve written a custom monitoring implementation that integrates with our logging frameworks, such as Scribe. This means that logs from the Data Transfer Project can be produced consistently with other Facebook services and integrate seamlessly with our analysis and alerting tools. For hosting, we are able to manage the transfer workers via Tupperware by creating a Facebook-specific deployment policy, which allows us to optimize compute resources in our data centers. Tupperware also means we can have separate release and production tiers, allowing for comprehensive testing of code within the Facebook environment before deploying to users. An extension that communicates with Configerator allows us to configure our transfer workers.
We believe the Data Transfer Project shows that industry-led solutions can help make data portability a reality. We also believe that people should be able to move their data from one service to another. We are excited to be putting this first tool out and look forward to working with even more experts and companies, especially startups and new platforms, as this project continues to expand. We are committed to continuing to build more tools in the coming months that enable people to transfer other types of data. To learn more about the Data Transfer Project open source code, you can read the technical whitepaper, watch our @Scale technical talk, or visit the GitHub repository.








