
A fast dimensional analysis (FDA) framework that automates root cause analysis on structured logs with improved scalability. When a failure event happens in a large-scale distributed production environment, performing root cause analysis can be challenging. Various hardware, software, and tooling logs are often maintained separately, making it difficult to detect issues across multiple logs. Additionally, at scale, there could easily be millions of entities, each with hundreds of features, making it difficult to debug issues.
Our proposed FDA framework combines structured logs from a number of sources and provides a meaningful combination of features. That information arms engineers with actionable insights and helps them determine where to begin their investigation. And improved Apriori/FP-Growth algorithms sustain analysis at Facebook scale.
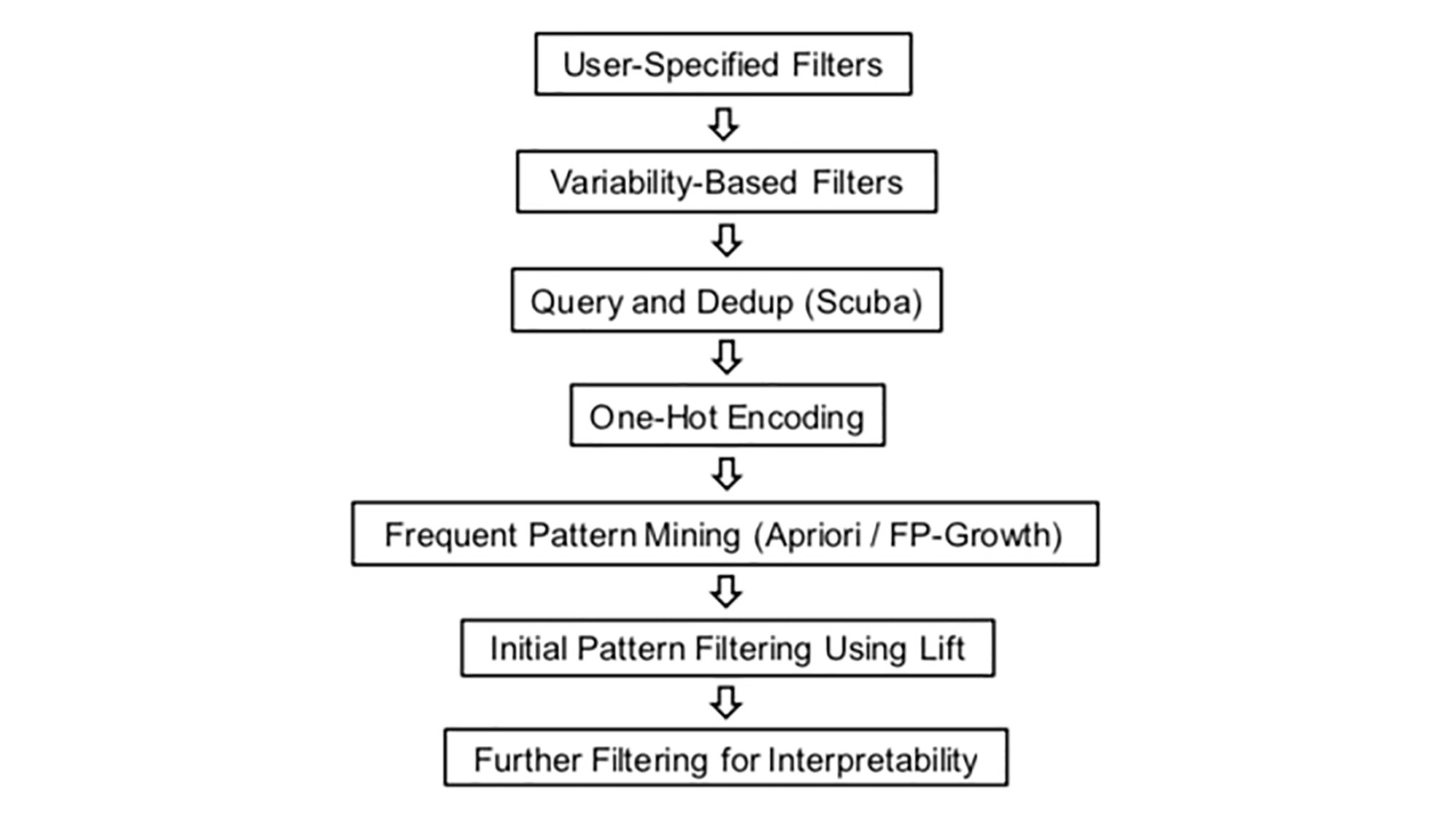
How it works:
The FDA framework first fetches structured logs from various sources. Log data is deduplicated at query time (deduping significantly improves algorithm performance). Each duplicated row will have a samples column that counts original row frequency. The resulting data is then one-hot encoded (a Boolean 0/1 value, depending on whether a given feature is present in a given row) to transform it into a schema that fits the frequent pattern mining formulation. Frequent pattern mining is applied to identify frequent item-sets.
Support and lift are metrics that are used for filtering. Support of feature X with respect to data set D refers to the portion of transactions that contain X within D. Support has a downward closure property, which is important because downward closure implies that all subsets of a frequent item-set are also frequent, and all supersets of an infrequent item-set can be safely pruned because they will never be frequent.

To measure significance or importance, we used lift, which measures how much more likely X and Y are to occur together relative to if they were independent. A lift value of 1 means independence between X and Y, and a value greater than 1 signifies dependence. Due to the focus on scalability, we propose pre- and post-processing, parallelism, and filters to further speed up the analysis and improve interpretability.
Why it matters:
During system outages, it is important for engineers to accurately isolate the problem and quickly find a solution. As we’ve mentioned, the challenges of performing root cause analysis in a large-scale distributed production environment make outage detection and mitigation difficult. We have successfully implemented this approach for a large-scale infrastructure environment and hope this work motivates further research and automation for similarly large and complex environments.
Read the full paper:
Fast Dimensional Analysis for Root Cause Investigation in Large-Scale Service Environment
We’d like to thank Seunghak Lee and Sriram Sankar for their contributions to this work.








