
At Facebook, we think that artificial intelligence that learns in new, more efficient ways – much like humans do – can play an important role in bringing people together. That core belief helps drive our AI strategy, focusing our investments in long-term research related to systems that learn using real-world data, inspiring our engineers to share cutting-edge tools and platforms with the wider AI community, and ultimately demonstrating new ways to use the technology to benefit the world.
In 2018, we made important progress in all these areas. We presented new research highlighting the long-term feasibility and immediate benefits of working with less supervised data, in projects that ranged from improved image recognition to expanding the number of languages that our services can understand and translate. We released a number of platforms and tools to help others transition their AI research into production applications, including updating our popular open source PyTorch deep learning framework with a new, more versatile 1.0 version that includes additional support and entry points for newcomers. And in addition to publishing a wide range of public research papers and related models and data sets, we showed that AI has the potential to improve lives, by assisting with MRI scans, disaster relief efforts and tools to help prevent suicides. Here are some highlights of our efforts in AI throughout the year.
Advancing AI learning through semi-supervised and unsupervised training
One of the founding goals of the Facebook AI Research (FAIR) group is to work toward the development of systems with human-level intelligence. Achieving this milestone will take many more years of research, but we believe that our efforts in 2018 helped demonstrate a path towards AI that’s more versatile, by learning from data that’s less curated for the purposes of training. While most current AI systems use supervised learning to understand a specific task, the need for large numbers of labeled samples restricts the number of tasks they can learn, and limits the technology’s long-term potential. That’s why we’re exploring multiple approaches to reducing amount of supervision necessary for training, including projects that show the benefits of learning from semi-supervised and even unsupervised data.
For example, in order to increase the number of languages that our systems can potentially translate or understand, we demonstrated a new method for training automatic translation NMT models on unsupervised data, with performance comparable to that of systems trained on supervised data. Our system’s accuracy was a substantial improvement over that of previous unsupervised approaches. By reducing the field’s reliance on large corpora of labeled training data, it opens the door to translating more languages, including low-resource languages such as Urdu, for which existing data sets are limited in comparison with English.
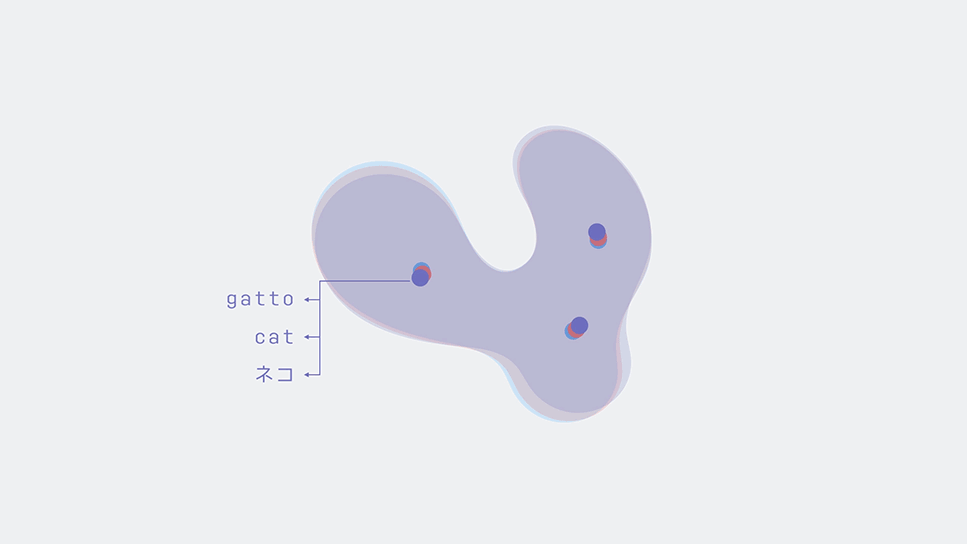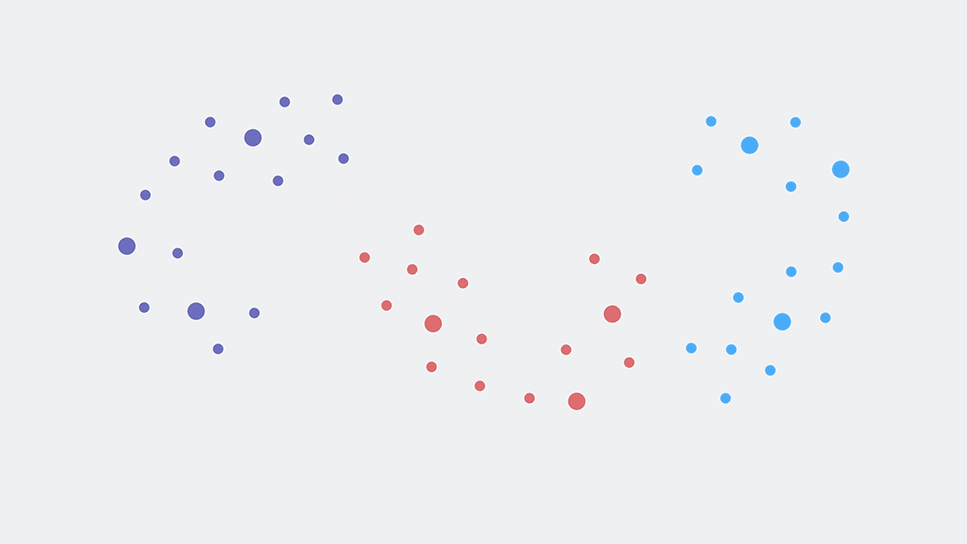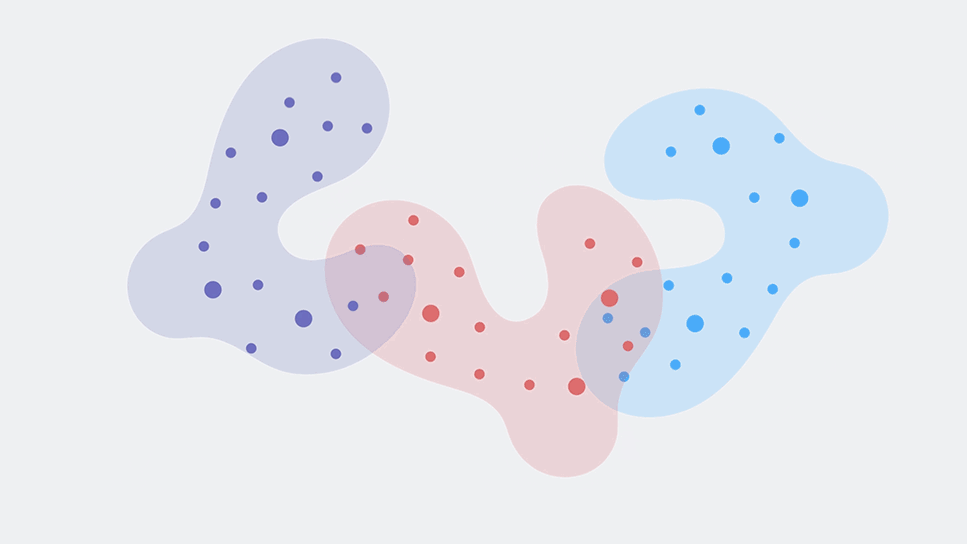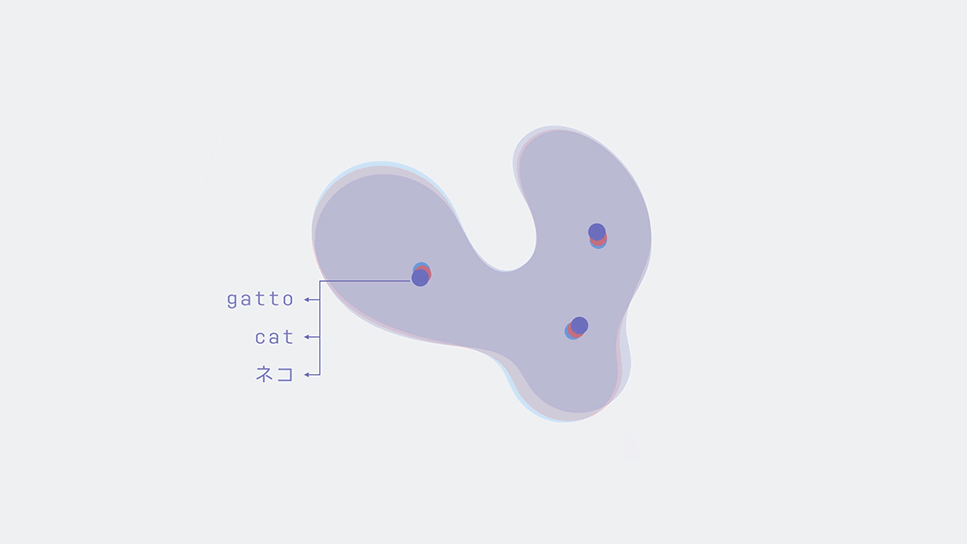
Two-dimensional word embeddings in several languages can be aligned via a simple rotation.
Another project worked entirely with low-resource languages, with multiple approaches for circumventing the relative scarcity of labeled training data. This work included using multilingual modeling to leverage the similarities between dialects within a given language group, such as Belarusian and Ukrainian. This was applied research, and the range of techniques the team employed added 24 more languages to our automatic translation services this year. Also, in a collaboration with NYU, we added 14 languages to the existing MultiNLI data set, which is widely used for natural language understanding (NLU) research but was previously English-only. Among the languages in our updated XNLI data set are two low-resource languages (Swahili and Urdu), and our approach contributes to the overall adoption of cross-lingual language understanding, which reduces the need for supervised training data.
We also demonstrated variations on data supervision, such as a new method of combining supervised and unsupervised data — a process called omni-supervised learning — through data distillation. And for our study of hashtag-based image recognition, we developed a creative use of existing, non-traditional labels to generate large training sets of what was essentially self-labeled data, including a set of 3.5 billion public Instagram images. That project proposed that user-supplied hashtags could act as data labels, turning existing images into weakly supervised training examples. Our results not only proved that using billions of data points could be highly effective for image-based tasks, but it also allowed us to break a notable record, beating the previous state-of-the-art image recognition model’s accuracy score on the ImageNet benchmark by 1 percent.

Hashtags can help computer vision systems go beyond general classification terms in order to recognize specific subcategories and additional elements in an image.
Accelerating the transition from AI research to production
AI has become foundational to nearly every product and service at Facebook, and that diversity of applications is reflected in the broad range of AI-based platforms and tools that our engineers are building and enhancing. But a common theme developed over the course of our platform work in 2018: turning the AI techniques we’re researching into AI systems we can deploy.
Since our release of PyTorch in 2017, the deep learning framework has been widely adopted by the AI community, and it’s currently the second-fastest-growing open source project on GitHub. PyTorch’s user-friendly interface and flexible programming environment made it a versatile resource for rapid iteration in AI development. And its open design has ensured that the framework would continue to grow and improve, thanks to codebase contributions and feedback. For 2018, we wanted to give the PyTorch community a more unified set of tools, with a focus on turning their AI experiments into production-ready applications. That meant enough of an overhaul to justify a new version: PyTorch 1.0.
We announced the updated framework at our F8 conference in May, detailing how it integrates the modular, production-oriented capabilities of Caffe2 and the newly expanded ONNX to streamline the entire AI development pipeline, from prototyping systems to deploying them. In October, we released the PyTorch 1.0 developer preview at the first PyTorch Developers Conference, where we presented the framework’s rapidly growing partner and platform ecosystem. Google, Microsoft, NVIDIA, Tesla, and many other technology providers discussed their current and planned integration with PyTorch 1.0 at that event, and both fast.ai and Udacity have created courses that use the new version to teach deep learning.
We completed the rollout of PyTorch 1.0 earlier this month, with a full release that includes all the new features we’ve been working on, such as a hybrid front end for transitioning seamlessly between eager and graph execution modes, revamped distributed training, and a pure C++ front end for high-performance research. We’ve also released tools and platforms this year that extend PyTorch’s core capabilities, including a pair of kernel libraries (QNNPACK and FBGEMM) that make it easier for mobile devices and servers to run the latest AI models, and PyText, a framework that accelerates natural language processing (NLP) development.
PyTorch also provided the foundation for Horizon, the first open source end-to-end platform that uses applied reinforcement learning (RL) to optimize systems in large-scale production environments. Horizon takes RL’s much researched but rarely deployed decision-based approach and adapts it for use with applications whose data sets might include billions of records. After deploying the platform internally at Facebook, in use cases such as optimizing streaming video quality and improving M suggestions in Messenger, we open-sourced Horizon, making this unprecedented bridge between RL research and production-based RL available for anyone to download.

A high-level diagram showing the feedback loop for Horizon. First, we preprocess some data that the existing system has logged. Then, we train a model and analyze the counterfactual policy results in an offline setting. Finally, we deploy the model to a group of people and measure the true policy. The data from the new model feeds back into the next iteration, and most teams deploy a new model daily.
We also released Glow, an open source, community-driven framework that enables hardware acceleration for machine learning (ML). Glow works with a range of different compilers, hardware platforms and deep learning frameworks, including PyTorch, and is now supported by a partner ecosystem that includes Cadence, Esperanto, Intel, Marvell, and Qualcomm Technologies Inc. And to further encourage the use of ML throughout the industry, we released a new ML-optimized server design, called Big Basin v2, as part of the Open Compute Project. We’ve added the new, modular hardware to our data center fleet, and the specs for Big Basin v2 are available for anyone to download at the OCP Marketplace.
2018 marked the transition of Oculus Research into Facebook Reality Labs, and new explorations of the overlap between AI and AR/VR research. And as part of our ongoing effort to open source as many of our AI-related tools as possible, we’ve released the data and models for our DeepFocus project, which uses deep learning algorithms to render realistic retinal blur in VR. The first system to accomplish this in real time at the image quality necessary for advanced VR headsets, DeepFocus is a novel application of deep learning in AR/VR work, using an entirely novel network structure that’s applicable to our own Half Dome prototype headset, as well as to other classes of promising head-mounted displays.
In the year ahead, we hope to get more feedback about all of these releases. And we’ll continue to build and open-source tools that support PyTorch 1.0’s mission to help the entire developer community get cutting-edge AI systems out of labs and research papers and into production.
Building AI that benefits everyone
We have a long track record of working on technologies that deliver the benefits of AI very broadly, such as creating systems that generate audio descriptions of photos for the visually impaired. This past year, we continued to deploy AI-based features aimed at benefiting the world, including an expansion of our existing suicide prevention tools that use text classification to identify posts with language expressing suicidal thoughts. This system uses separate text classifiers to analyze the text of posts and comments, and then, if appropriate, send them to our Community Operations team for review. This system leverages our established text-understanding models and cross-lingual capabilities to increase the number of people we can connect with support services.
We also released a method for using AI to quickly and accurately help pinpoint the areas most severely affected by a disaster without having to wait for manually annotated data. This approach, which was developed in a collaboration with CrowdAI, has the potential to get aid and rescuers to victims with greater speed and efficiency. In the future, this technique could also be used to help quantify the damage from large-scale disasters such as forest fires, floods, and earthquakes.
We deployed an ML system called Rosetta that extracts text from more than a billion public images and video frames every day, and uses a text recognition model to understand the context of the text and the image together. Rosetta works on a range of languages, and it helps us understand the content of memes and videos, including for the purposes of automatically identifying policy-violating content.
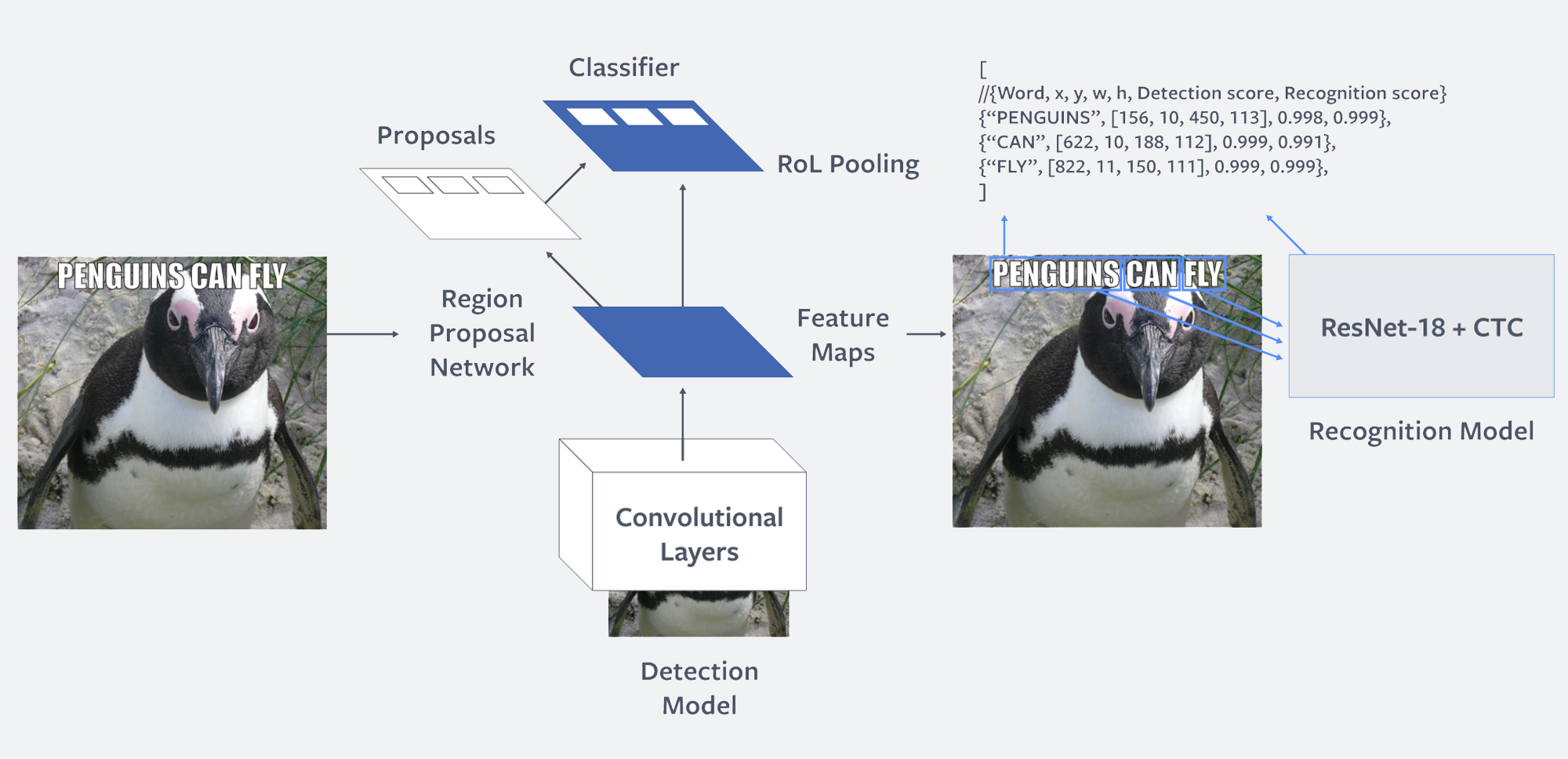
Two-step model architecture used for Rosetta’s text extraction.
And 2018 marked the beginning of fastMRI, a long-term collaboration with NYU School of Medicine to improve diagnostic imaging technology, starting with accelerating MRI scans by as much as 10x. Current scans take up an hour or more, which makes them infeasible for some patients and conditions, and this joint research project is intended to increase the availability of this potentially life-saving diagnostic tool by using deep learning to generate images from less raw scanner data. The goal of fastMRI isn’t to develop a proprietary process but to accelerate the field’s understanding of this technique, and our partnership has already produced the largest-ever collection of fully sampled MRI raw data for research purposes (fully anonymized and released by NYU School of Medicine), as well as open source models to help the wider research community get started on this task. We also launched an online leaderboard, where others can post and compare their results.
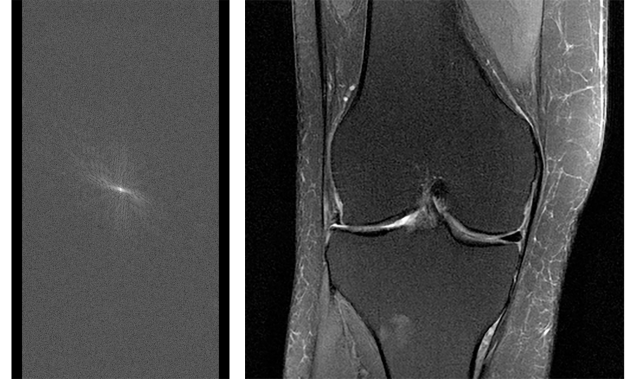
(L) Raw MRI data before it’s converted to an image. To capture full sets of raw data for a diagnostic study, MRI scans can be very time-consuming. (R) MRI image of the knee reconstructed from fully sampled raw data.
In 2018, we also published blog posts detailing our work in other areas. These included ways to use AI to improve our systems (Getafix, predictive test selection, SapFix, Sapienz, and Spiral) and enhance our products (SLAM and AI in Marketplace), as well as other research efforts (wav2letter++, combining multiple word representations, multilingual embeddings, and audio processing.)
We’re excited by the progress we’ve made in 2018 in our pillars — conducting fundamental research, deploying cutting-edge applications, and sharing new ways to use AI to help others — and we look forward to building on those efforts in the coming year.
This series of posts looks back on the engineering work and new technologies we developed in 2018. Read the previous posts about our work in Data Centers and our Open Source efforts.








