
Most of the autonomous agents that humans interact with have something in common: They aren’t very self-sufficient. A smart speaker, for example, can communicate through its voice interface and take some actions, such as ordering products, but it can’t perceive its surroundings. A robotic lawn mower, on the other hand, can take action (by mowing) and perceive (with sensors), but, aside from blinking its lights or sending error messages, it can’t fully communicate back to its owner.
Without the important trifecta — perception, communication, and action — autonomous agents fall short as full-fledged assistants, leaving people to fill in the gaps in their self-sufficiency. This issue might seem minor with present-day agents — the Roomba neglecting to inform you about a chair blocking its cleaning rounds is a hassle, not a crisis. But in order for the next generation of agents to integrate into and transform our lives, autonomous systems need to become more self-sufficient.
Training AI without training wheels
To help pave the way for systems that are less dependent on human micromanagement and more useful generally, Facebook AI Research (FAIR) has developed a collection of virtual environments for training and testing autonomous agents, as well as novel AI agents that learn to intelligently explore those environments. The agents, which function as simulated robots, were created in a collaboration with researchers at Georgia Tech. Using virtual agents and environments is vastly more efficient than sending real robots into existing indoor locations, since it would take thousands of machines to match the speed of AI-based training runs. We presented an overview of this work at today’s F8 conference, during a talk on using AI to make content more accessible.
Our aim is to teach systems to take multiple actions according to a long-term plan, while working toward accomplishing a given mission. To succeed, these agents must act in their environments, using a combination of perception, navigation, and communication to seek out the answers to questions posed to them, and then relay those answers in plain, natural language. It’s a challenging gauntlet for AI to run, and a step toward a level of autonomy that’s adaptive enough to function in the unstructured, human-built world.
To test this goal-driven approach, FAIR and Georgia Tech are proposing a multistep AI task called Embodied Question Answering, or EmbodiedQA. In contrast to a chat bot or smart speaker, this agent must learn and function in the context of a physical (albeit virtual) environment, hence “embodied.” When asked a single question, such as “What color is the car?” or “What room are my keys in?” the agent must be able to understand written language, perceive its surroundings with a first-person camera, and navigate through 3D indoor environments until it finds the answer. To round out the agent’s useful autonomy, it completes its mission by communicating that answer back through natural language.
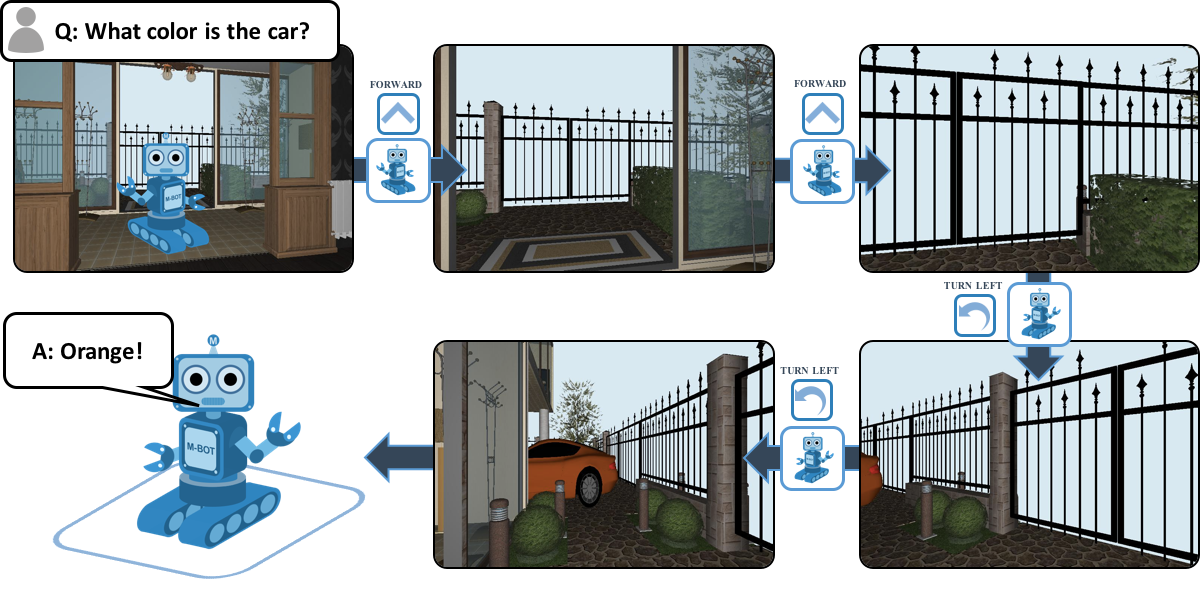
We believe these experiments are the first to require an AI system to demonstrate a mix of perception, communication, and action in order to succeed. Adding to the task’s challenge is the combination of total autonomy — agents function with no human guidance or intervention — and unfamiliar surroundings. The agent spawns at random, in one of hundreds of different floor plans (each one modeled after a realistic home), without the benefit of practice runs in that environment or anything resembling a map. Harder still, to answer the question posed to it, the agent must move, because the object in question may not be in immediate view.
Learning on the job
To train and evaluate these agents, we needed access to environments that were not only interactive but also diverse and numerous enough to limit the chances of repeat runs. This is a broader challenge for autonomous agent development, and FAIR’s solution, called House3D, consists of 45,000 manually created simulated indoor environments. House3D is based on Princeton University’s SUNCG data set, but as a fully navigable set of locations, it gives us the luxury of exploring thousands of rooms simultaneously, training our agent faster than a physical robot would be able to train in real living spaces. It also lets us conduct reproducible scientific experiments. And House3D is designed for use by other researchers — it’s open source and currently accessible on GitHub.
To carry out each unique scavenger hunt in House3D, the agent must learn a set of core capabilities — ranging from the recognition of indoor objects (couches, chairs, etc.) to an understanding of the language in the questions posed to it — during the process of accomplishing its mission.
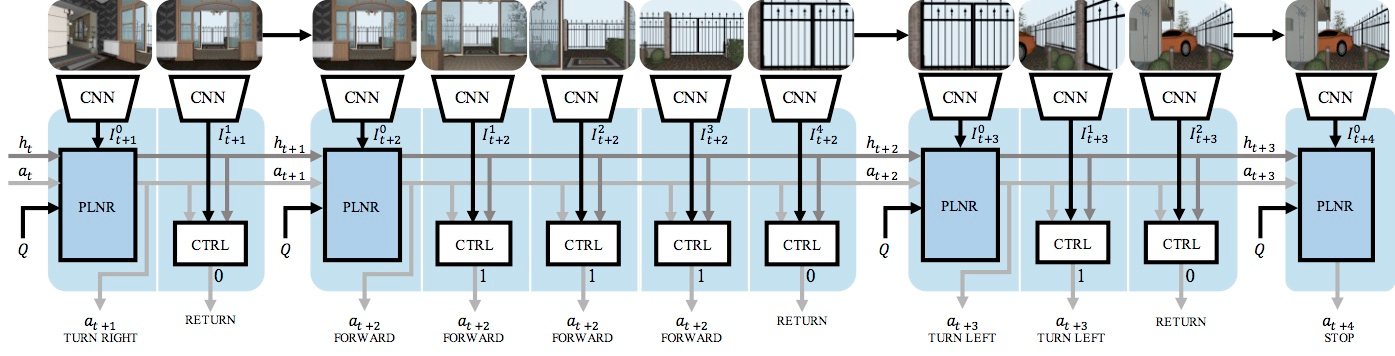
The first of those learned capabilities is active perception, or the ability to intelligently control the pixels that come its way, since the target is initially unlikely to be in the line of sight of the agent’s simulated 224×224-pixel RGB camera. So, rather than passively perceiving the object in question (as in fixed image data sets), the agent moves through its surroundings, seeking it out.
One of the novel aspects of this research is a modular approach to navigation that splits the task up between two components. The planner picks the direction of movement, such as going left, while the controller determines how far to move in that direction. This strategy avoids the need to create long, detailed paths before moving, which can lead to more errors and less adaptability. The planner-controller setup is also better suited to reinforcement learning, where the agent adjusts its navigation on the fly, based on positive or negative feedback.
Next, the agent must learn commonsense reasoning, getting its bearings in the context of a new but not entirely alien environment. While humans might know that garages tend to be on the perimeter of a house and are therefore accessible via external doors, the system needs to learn this for itself. With successive spawns in different simulated homes, the agent must develop the kind of common sense that shortens the amount of time it takes to find a given object and then answer the related question.
As a follow-on to an accrued common sense, the agent also needs to learn language grounding, or how to associate words (such as descriptions of an object) with specific actions. For example, when searching for a garage in order to find the car that’s likely within it, the agent isn’t forced to look in every possible space until it finds a set of pixels that correspond to a garage. Instead, it uses “garage” as a call to action, seeking out external doors in order to more efficiently locate its target.
Finally, since our goal is to move beyond tedious, step-by-step human supervision to learning from weak and distant goal-driven rewards, one of the most important skills the agent must learn is “credit assignment,” meaning knowing what it did right or wrong along the way. For example, if asked “How many rooms contain chairs?” the agent isn’t being explicitly told to navigate through every room or even to start a tally of chair-containing sections of the home. Rather than receiving such an explicit step-by-step plan, the agent is on its own to explore and answer when ready. Thus, from a weak signal of whether it answered correctly, it must learn on its own which of its hundreds of interdependent actions lead to success. To augment traditional reinforcement learning, we used imitation learning (comparing the agent’s movement with the shortest possible path to the target) and reward shaping (improving the agent’s performance over time with “getting closer” or “getting further” signals) to allow the agent to piece together its real mission, even when it wasn’t clear from the start.
Making autonomy more autonomous
The trained EmbodiedQA agent performs quite reasonably compared with a standard sequence model baseline (an LSTM navigator).
This video compares the performance of our developed agent (titled ACT+Q-RL) against a baseline (titled LSTM+Q).
Like House3D, the EmbodiedQA data that we’ve gathered will be open source and is intended to inspire other projects within to the broader AI research community. And to provide full context for other researchers we brought humans into the equation. FAIR and Georgia Tech measured the autonomous agents’ ability to navigate and answer questions against remote-controlled agents, which were operated by people (via Amazon’s Mechanical Turk platform) to create expert, benchmark navigation examples. The resulting initial data set includes synthetically generated questions related to 750 unique, multiroom environments. Breakdowns of agent (and human) accuracy, as well as the question-answer generation engine that we used, will be part of the EQA v1 open source release, which should be available in the near future.
Though EmbodiedQA covers only a single kind of goal-driven autonomous task, it represents both a high degree of difficulty for AI (since it rolls various subtasks into a single one) and an opportunity to explore new learning paradigms in which taking “action” is a prerequisite of success. Agents that aren’t capable of making decisions — in this case, navigating through realistic homes, determining that they’ve gathered relevant data, and then communicating what they discover — simply can’t accomplish the missions in our experiments.
This sort of challenge is as daunting as it is crucial. In the short run, goal-driven algorithms could use automation to improve the experience of AR and VR, adding intuitive voice interaction to the available interface options. But the long-term impact of this action-based, goal-driven approach could extend to autonomy itself. From digital assistants that can carry out a slew of chores based on a single command (such as not only making a doctor’s appointment but also rescheduling conflicting meetings) to disaster response robots that follow plain-language orders from first responders, this sort of adaptive automation could have a significant impact on our lives.








