
People around the world come to Facebook to celebrate and share experiences during special events, such as the Olympics or New Year’s Eve. These types of global occurrences can cause spikes in the load and traffic patterns on Facebook’s systems, especially with high-bandwidth content like Facebook Live videos. The Production Engineering team at Facebook carefully plans and builds infrastructure to ensure service uptime and reliability even through such spikes.
Facebook’s infrastructure is set up to accommodate different types of traffic patterns based on typical usage or special events. There are three general categories of load variance caused by usage changes in a service (as opposed to hardware failure or service disruption):

- Routine: Most online systems have regular and predictable load patterns. One example is the daily pattern of people using Facebook as different parts of the world wake up or go to sleep. Another example is the weekly traffic pattern, where weekend usage often looks different than weekdays. Accommodations for these kinds of regular traffic variations are built in to the service from the outset.
- Spontaneous: On the opposite extreme are unexpected load patterns that can be caused by unplanned world events, such as weather incidents or natural disasters, or even viral social media phenomena such as 2014’s ALS Ice Bucket Challenge. Accommodating and absorbing these kinds of sudden, sometimes dramatic changes can be difficult, often relying on maintaining an entirely elastic service.
- Planned: Examples of planned special events include New Year’s Eve as well as the upcoming Winter Olympics and the 2018 FIFA World Cup. Often, these kinds of events are brief and result in sharp but short load spikes. These events are not regular enough to fall into the normal day-to-day capacity requirements. Nor are they unknown or unexpected, so they require special planning and support from the production engineers.
To illustrate how we handle these kinds of planned special events, let’s look at how the Production Engineering team has prepared the live video streaming infrastructure for New Year’s Eve.
Facebook Live planning for New Year’s Eve
Dec. 31 is a significant day in terms of traffic and load for a number of different systems at Facebook, including Facebook Live. Our focus is to ensure that people can continue to share their experiences on Facebook Live with no disruptions or slowdowns.
Because of its scale, we start planning for New Year’s Eve months ahead of time, in October. Production engineers are responsible for end-to-end reliability, but they coordinate with many infrastructure and product teams involved in the overall planning and execution.
Architecture of Facebook Live
To understand the different ways in which increased traffic affects these systems, let’s review the general architecture of Facebook Live and how the data flows through the system:
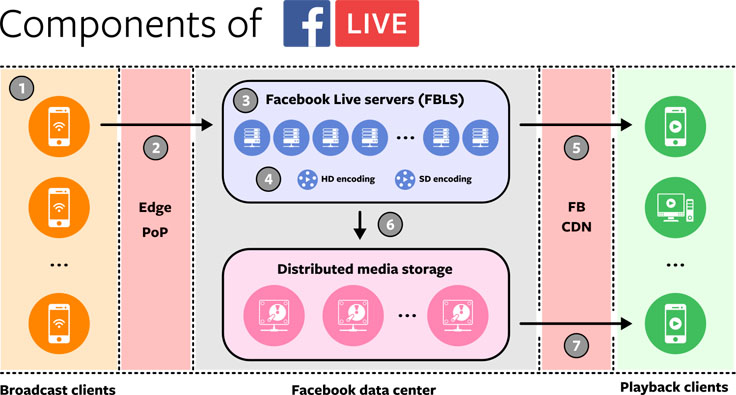
- Client devices running the Facebook app generate live compressed H.264/AAC media streams.
- Streams are sent via an RTMPS TCP stream through an edge point of presence (PoP).
- Streams are routed from a PoP to a data center, where they terminate on a Facebook Live server (FBLS).
- Output encodings are generated in multiple resolutions and bit rates in MPEG-DASH video/audio segments.
- Output encoding segments are delivered through the Facebook Content Delivery Network (FB CDN) for live playback on clients via MPEG-DASH over HTTPS.
- Output encodings are also stored in distributed storage for permanent retention.
- Later, non-live playback of broadcasts happens from distributed storage via the FB CDN to playback clients.
As this infrastructure shows, three types of resource usage are affected by an increased level of Facebook Live broadcasts:
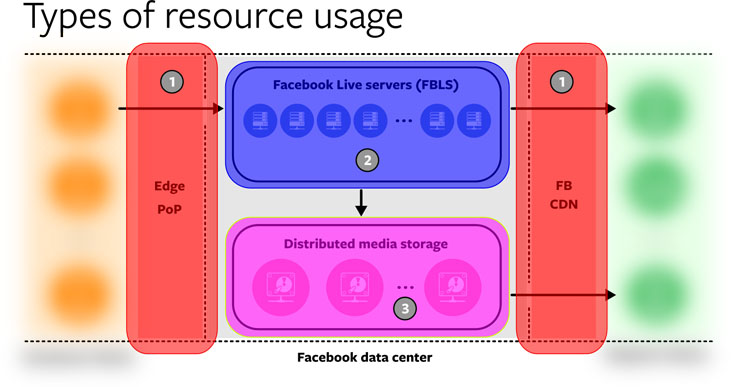
- Network: The traffic of incoming and outgoing streams.
- CPU: The computation resources needed to generate output encodings.
- Storage: The retention of output encodings for future, non-live playback.
This simplified description spans networking, video infrastructure, and storage. As with most large-scale distributed systems, other common dependencies such as log storage, metrics collection, and configuration distribution also can be affected by New Year’s Eve traffic, so they are included in the scope of the planning.
Metrics for Facebook Live load
We consider three load metrics as part of our New Year’s Eve planning:
- The total number of Facebook Live broadcasts over the entire day of Dec. 31. This is important for areas such as the total amount of storage capacity required to retain the streams.
- The peak number of concurrent broadcasts at any time on Dec. 31. This matters for aspects such as the peak number of write operations to the storage system, as well as the amount of CPU needed to generate the output encodings for streams in the system at any time.
- The load generated on other systems as a result of scaling the infrastructure for Facebook Live.
Of these three load types, the peak number of concurrent broadcasts is the hardest to accommodate. Due to the basic nature of live streaming, it isn’t possible to smooth out the resource consumption by delaying work until off-peak times in the way that would be possible with batch workloads. It’s important to have enough capacity to handle the peaks in real time. Therefore, the peak concurrent number of Facebook Live broadcasts is the main metric we use for New Year’s Eve planning.
The load increase on dependent systems is subtle but important. An example of a real consequence of this kind of load occurred during testing in December 2017: A standard health/status check is run against an open TCP port on a Facebook Live server (FBLS) from the network systems that route the live streams. (This exists so that streams are routed to healthy FBLS hosts and are evenly balanced between them.) The nature of the health check calls meant that there was a many-to-many connection system between the routing hosts and the FBLS hosts.
When the number of FBLS hosts in one of the tiers was substantially expanded to increase capacity, the 1-second health checks caused network traffic of hundreds of megabits per second. This degraded the performance of the routing hosts and affected other services. Although the fix was simple (less frequent health checks and eliminating the many-to-many connections between routers and FBLS), it highlights the kind of unexpected issue that can affect other parts of the system when increasing capacity in one area.
Estimating New Year’s Eve traffic for Facebook Live
As mentioned previously, our primary measure of New Year’s Eve load is the peak number of concurrent Facebook Live broadcasts that are expected to occur on Dec. 31. As such, our planning starts with a collaborative effort across the Production Engineering, capacity planning, and data science teams to establish the peak traffic expected at any point throughout the day.
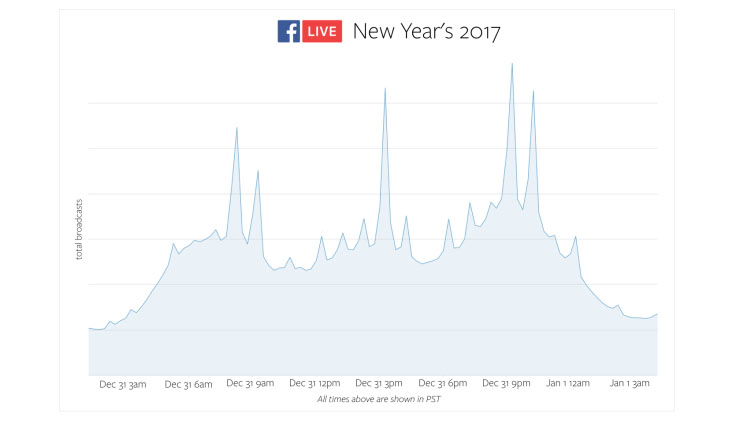
Because Facebook Live has been in production for several years, we have historic regional and global data on concurrent broadcasts from previous New Year’s Eve events, which we can draw on to predict future load. By looking at 24 hours of data from the previous New Year’s Eve, we could estimate the times of day when spikes in broadcasts would be likely, as well as the expected relative increase of those sudden spikes and the sustained periods of increased traffic over the day. The spikes themselves happen as various time zones hit midnight, and they are brief but sizable. To estimate the actual absolute peak numbers, we looked at more recent data on daily usage patterns that factored in organic product growth and changes in usage patterns over the past year.
Scaling Facebook Live for New Year’s Eve
Once the estimated peak concurrent stream load had been established for New Year’s Eve, we worked to ensure that the system could scale to that level. As expected, additional hardware resources were necessary (particularly CPU for video encoding, but also for network routing, storage, and so on). Alongside the additional hardware allocations, we worked to improve the efficiency of the system. For example, one of the capacity bottlenecks was expected to be the number of simultaneous write operations happening to the distributed storage system (for the permanent copy of the live stream data). Before the New Year’s Eve planning, the segments written to storage were 10 seconds long (with a bit rate of around 1 Mb/s and approximately 1.25 MB per segment).
We reduced these operations by consolidating the media segments into 20-second units, which decreased the IOPS to the storage system without negatively impacting its reliability or performance.
Load testing
One of the lengthiest parts of the preparations for New Year’s Eve — and the main reason that planning starts in October — is the testing required to ensure that the necessary changes to the system work as expected.
We used the following three methods to load-test various aspects of Facebook Live and the networking and storage dependencies.
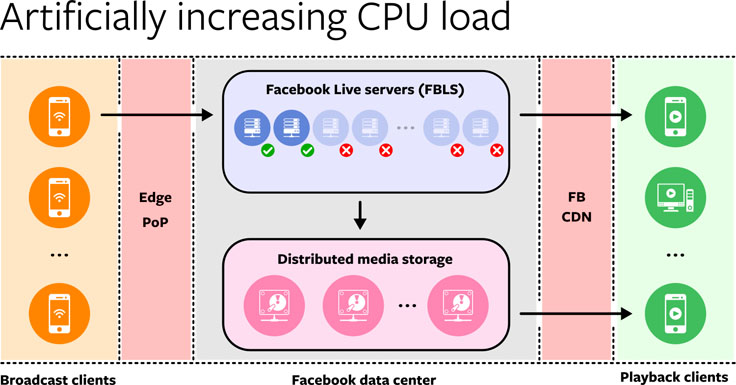
Artificially increasing the load on particular tiers. The Facebook Live infrastructure consists of multiple physical clusters of FBLS hosts across different regions. Usually, incoming traffic is balanced evenly between them automatically. However, in order to test the maximum capacity per host or cluster and measure the impact of encoding efficiency changes, we intentionally redirect more traffic to individual clusters or hosts, measure the resource usage on those hosts, and find the boundaries of the service.
This method of testing is particularly useful for establishing the CPU needed to support the peak number of concurrent Facebook Live broadcasts. The broadcasts themselves are independent, and the encoding system is horizontally scalable. The overall limit of the system itself is determined by ascertaining the maximum number of streams that can be encoded per host in parallel, and multiplying this by the total hosts.
However, artificially “squeezing” individual hosts and clusters in this way does not allow for testing the network and storage dependencies of the system, because the total traffic sent to the dependent systems is unchanged.
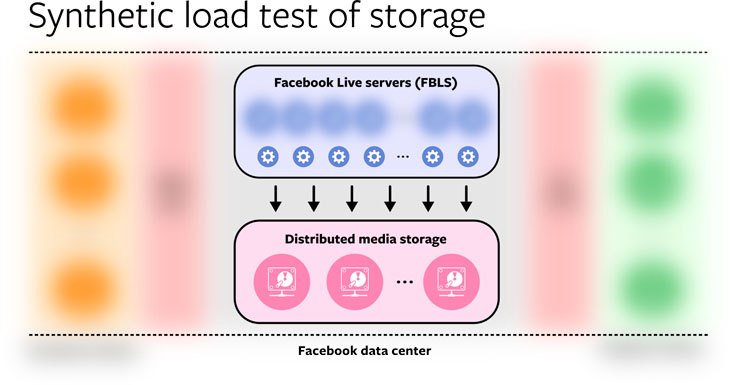
Synthetic load tests of dependencies. This method was especially useful for testing the capabilities of the storage system. By running a dedicated load test client on the FBLS hosts — which simply writes a high volume of synthetic data (with a segment size distribution identical to that of the actual data) into the distributed storage system — we were easily able to validate that we would be able to sustain the peak write load necessary on New Year’s Eve.
This load test is very specific to the particular dependency being tested and requires a client utility to generate the load as well as a data set that is representative of production. Nevertheless, it was an important validation tool in our planning.
Shadow traffic. This method of testing allowed us to replicate incoming production live streams on the FBLS host and multiply them into shadow streams. They then act as an additional input into the system so that an arbitrary amount of additional traffic can be generated on demand. This form of production traffic amplification was our preferred method of load-testing the system for New Year’s Eve planning, because it simultaneously tests all aspects of the Facebook Live system (except for playback) as well as the dependency storage and network services. It produces an accurate load that closely matches production traffic and gives the highest-confidence measurement of the maximum traffic the system can sustain.
One challenge with shadow testing was adding in the necessary hooks to replicate the production traffic safely and ensure that the shadow Facebook Live broadcasts were kept separate and distinct from the non-shadow traffic (so that broadcasts don’t accidentally show up as duplicated in production).
Conclusion
Through carefully estimating the New Year’s Eve load, planning the cross-functional capacity, scaling the system, and validating the changes, we were highly confident that we could accommodate significant extra load. That hard work paid off. Over the course of New Year’s Eve, more than 10 million people went live on Facebook, and shared 47 percent more Facebook Live videos than they did the previous year.
This kind of planning for special events remains an important and ongoing part of Production Engineering at Facebook. Not only is each event different, but the systems themselves also are constantly evolving as new features are developed. We’re continually striving to keep these systems operating smoothly during large events, to ensure that people can express themselves and share meaningful experiences with the people and communities that they care about.
Special thanks to the Video Infra team at Facebook that contributed to these efforts.








