
People have uploaded more than 70 million 360 photos to Facebook since we launched the feature last year. Facebook enables multiple methods for capturing 360 photos and videos, which allow people to share immersive experiences with their communities. If you own a dedicated 360 camera, like the Ricoh Theta S or the Giroptic iO, you can post from the camera directly to Facebook. And now most high-end Android and iOS smartphones have cameras with a panorama mode that can be used for 360 photo capture.
Facebook has developed and deployed several technologies in the past year to optimize the way people create and share 360 content, including 360 capture, 360 video stabilization, and reengineering how we store high-resolution media. Most recently, we’ve been exploring using deep neural nets for automatically reorienting 360 photos, which aims to bring more realistic immersive experiences directly to people’s phones.
Creating high-resolution 360 photos
We recently announced a new capability directly in the Facebook app that allows people to capture a full 360 scene with a novel, unconstrained sweeping UI. The video below shows the Facebook 360 capture in action.
360 photos tend to be much larger files than traditional photos, so one of our challenges was to allow people to scroll quickly through their News Feed when it included a 360 photo, while also making the full-resolution version of the photo available if they stopped to explore it by tilting, panning, or zooming. Delivering the full-resolution photo immediately could stall new content from populating as people scroll, as well as use large amounts of memory to process the photo.
Faced with these challenges, we reengineered Facebook’s photo infrastructure to allow for “tiled” storage and serving of photo content.
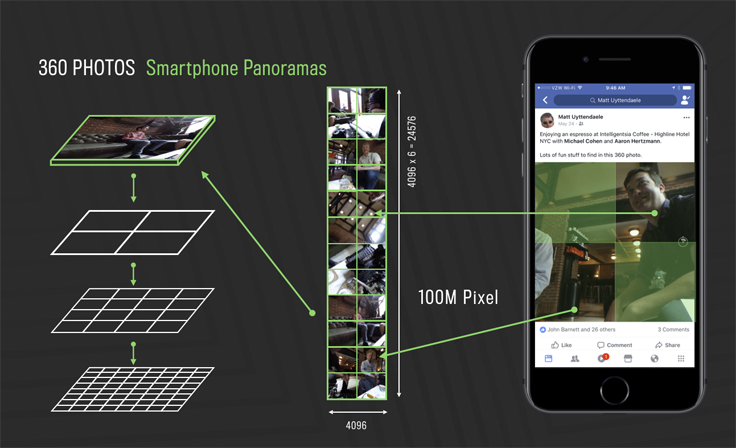
Each 360 photo is converted to a cube map, similar to an early approach we used for 360 videos. These cube maps in turn are stored at multiple resolutions, and each of these resolutions is split into small, individual 512×512 images. When a 360 photo comes into view, we calculate which resolution and which tiles are necessary to render the current window. If the current resolution is not available, we temporarily render a lower-resolution representation while waiting for the network to deliver the high-res content. We continually redo this calculation as the person pans and zooms inside the 360 photo. These changes allow us to display photos with hundreds of megapixels with no perceived change in performance.
Deep neural nets for 360 photos
The tens of millions of public 360 photos uploaded to Facebook provide a powerful new data set to help improve our products. The 360 data itself can be used in conjunction with machine learning approaches to create better experiences for people.
One of the most basic features of a 360 photo that breaks realism is when it is captured while the camera is not level and the resulting image rotation is not corrected. You can see an example of this below, where the camera was not held perfectly straight when taking the photo. This resulted in a tilted horizon, which completely breaks the sense of realism.

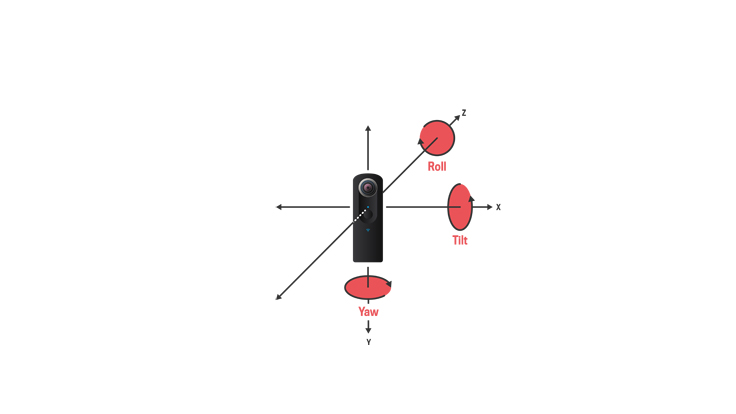
Fixing this kind of rotation with editing software is straightforward for traditional photos, but the same types of tools are not widely available for 360 photos, and correcting rotation on a sphere is much less intuitive. The rotation in a 360 photo is captured by two parameters — tilt and roll — shown in the diagram below. The third axis, yaw, affects the photo by changing the initial viewing heading, but it does not by itself induce a rotated scene. We wanted to develop a technique that automatically fixes the rotation caused by these movements.
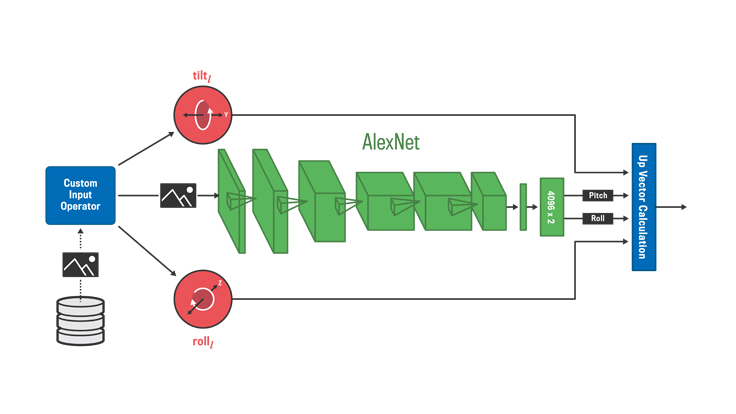
We tackled the problem by using a well-known deep neural net (DNN) architecture, AlexNet, and applying several modifications. An example image that represents our training data, shown above, contains a full spherical environment (360×180 degrees) and uses an equirectangular projection. We assume that the geometric nature of the problem does not require color information, so our training data consists of monochrome images with a resolution of 256×128. AlexNet was designed to solve classification problems of more than 1,000 classes. Thus, the final fully connected layer had 4,096 inputs and 1,000 outputs. We instead cast ours as a regression problem, so our final layer has 4,096 inputs and two continuous value outputs of tilt and roll.
We trained the DNN on rotated images labeled with tilt and roll values. Our training data set contained 500,000 equirectangular images that we assumed were, on average, not rotated; in other words, their tilt and roll was 0. During training, we artificially rotate each training sample via a randomly generated tilt and roll value. The loss function, shown in the equation below, measures the distance between these randomly generated label values and the result values that the DNN estimates.

To test the results of training, we synthetically rotate each photo in our data set through a known set of tilt and roll values. We then run the trained DNN on each of these rotations and record the resulting values. Any difference between the known applied values and the computed results can be attributed to two factors: (1) the DNN doesn’t exactly solve the rotation problem, and (2) the data set photo was not exactly upright to begin with. The second factor comes about because we assumed that the data sets were on average upright, but any particular sample may have some inherent rotation.
For each photo, we sweep through all combinations of tilt and roll values in the set [–4deg, –2deg, 0deg, 2deg, 4deg]. That is 25 different runs of the DNN per photo. From the tilt and roll values for each run, we compute the applied rotation. The most efficient way to represent this rotation is to use a tool often used in 3D graphics — the quaternion. We next compute another quaternion that represents the rotation computed by the network. If the network and the data had neither of the two issues listed above, then these quaternions would be identical. In practice they are not, so for each run we compute the difference between the two by dividing them. Finally the average of these differences is computed using the technique shown here.
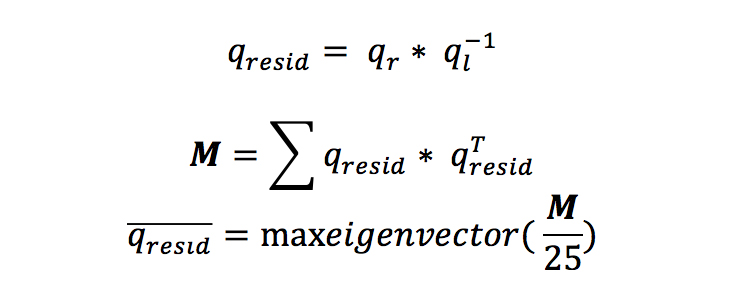
The math above used quaternions because they are a useful way to compute differences and averages of 3D rotations. But, we now need to label each photo with new tilt and roll values, due to the data set photo having not been exactly upright to begin with. This average difference is a good estimate of the true orientation of each training image. So, we use a simple conversion technique between quaternions and yaw, tilt, and roll to go from the average to updated labels.
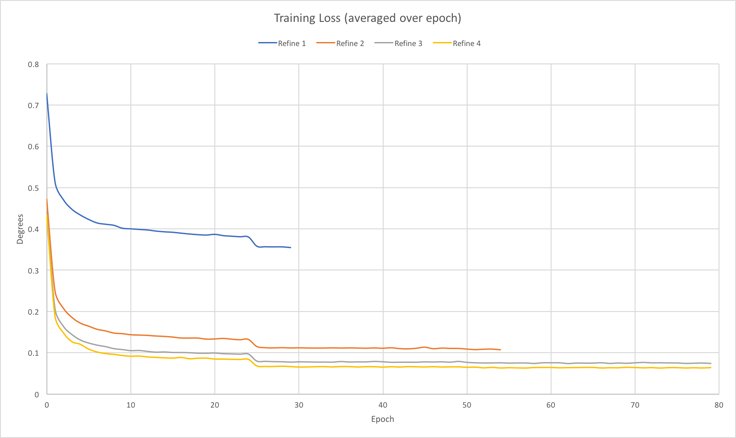
Once the data sets are relabeled, we do a new round of training. We iterate through four rounds of training and refinement. By the end of the refinement process, our DNN can compute a 360 rotation to within 0.1 degrees on average, as shown in the chart below. Each training phase starts from an uninitialized model, and we see that each phase converges to a smaller loss. A holdout test set also shows very similar convergence and error values. This convergence behavior leads us to conclude that the train-refine loop is learning the rotation function that we intended it to.
Below are some results of rotated 360 photos. These were not part of the training set. For each pair, the first image is the original, and the second is the result as corrected by the DNN. Notice that the DNN performs well across different content categories — photos that have human-made structures like buildings, as well as natural scenes.
Conclusion
We have now deployed 360 media across Facebook’s photos, video, and live streaming products. As we do this, challenges arise that are unique to immersive content. This post touches on just a few of those challenges that we’ve addressed this past year. As we see uploads of immersive media to Facebook accelerate, we’re excited about the promise of our research and how these techniques can help people experience places and events in new ways.








