
From the moment we wake up, our days are filled with a constant flow of negotiations. These scenarios range from discussing what TV channel to watch to convincing your kids to eat their vegetables or trying to get a better price on something. What these all have in common is that they require complex communication and reasoning skills, which are attributes not inherently found in computers.
To date, existing work on chatbots has led to systems that can hold short conversations and perform simple tasks such as booking a restaurant. But building machines that can hold meaningful conversations with people is challenging because it requires a bot to combine its understanding of the conversation with its knowledge of the world, and then produce a new sentence that helps it achieve its goals.
Today, researchers at Facebook Artificial Intelligence Research (FAIR) have open-sourced code and published research introducing dialog agents with a new capability — the ability to negotiate.
Similar to how people have differing goals, run into conflicts, and then negotiate to come to an agreed-upon compromise, the researchers have shown that it’s possible for dialog agents with differing goals (implemented as end-to-end-trained neural networks) to engage in start-to-finish negotiations with other bots or people while arriving at common decisions or outcomes.
Task: Multi-issue bargaining
The FAIR researchers studied negotiation on a multi-issue bargaining task. Two agents are both shown the same collection of items (say two books, one hat, three balls) and are instructed to divide them between themselves by negotiating a split of the items.
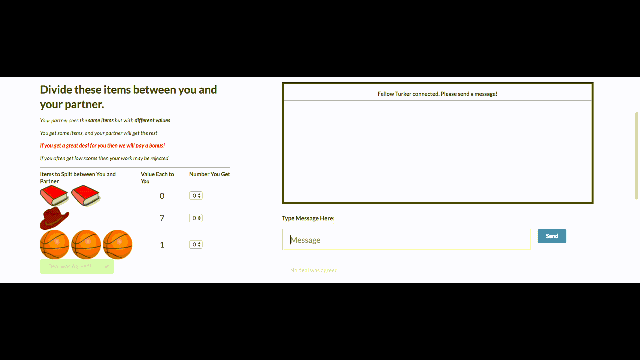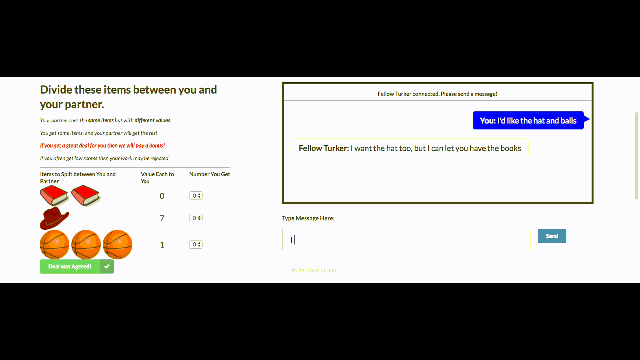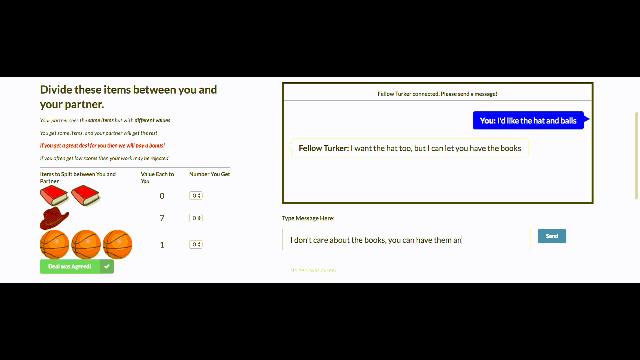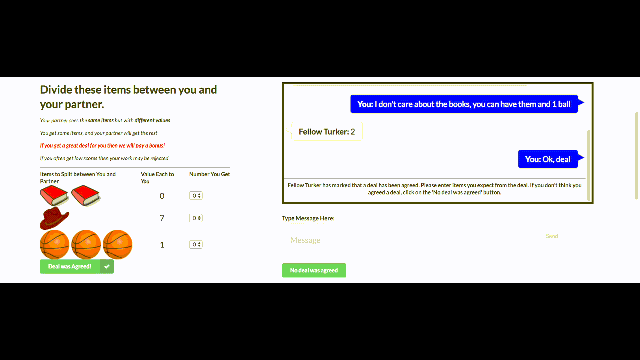
Each agent is provided its own value function, which represents how much it cares about each type of item (say each ball is worth 3 points to agent 1). As in life, neither agent knows the other agent’s value function and must infer it from the dialog (you say you want the ball, so you must value it highly).
FAIR researchers created many such negotiation scenarios, always ensuring that it is impossible for both agents to get the best deal simultaneously. Furthermore, walking away from the negotiation (or not agreeing on a deal after 10 rounds of dialog) resulted in 0 points for both agents. Simply put, negotiation is essential, and good negotiation results in better performance.
Dialog rollouts
Negotiation is simultaneously a linguistic and a reasoning problem, in which an intent must be formulated and then verbally realized. Such dialogs contain both cooperative and adversarial elements, requiring agents to understand and formulate long-term plans and generate utterances to achieve their goals.
The FAIR researchers’ key technical innovation in building such long-term planning dialog agents is an idea called dialog rollouts.
When chatbots can build mental models of their interlocutors and “think ahead” or anticipate directions a conversation is going to take in the future, they can choose to steer away from uninformative, confusing, or frustrating exchanges toward successful ones.
Specifically, FAIR has developed dialog rollouts as a novel technique where an agent simulates a future conversation by rolling out a dialog model to the end of the conversation, so that an utterance with the maximum expected future reward can be chosen.
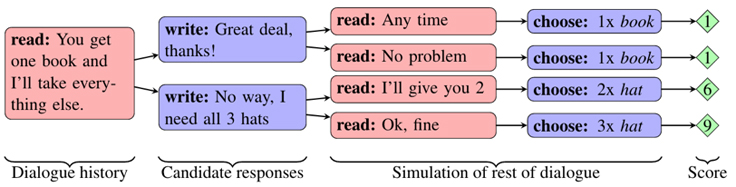
Similar ideas have been used for planning in game environments but have never been applied to language because the number of possible actions is much higher. To improve efficiency, the researchers first generated a smaller set of candidate utterances to say, and then for each of these, they repeatedly simulated the complete future of the dialog in order to estimate how successful they were. The prediction accuracy of this model is high enough that the technique dramatically improved negotiation tactics in the following areas:
Negotiating harder: The new agents held longer conversations with humans, in turn accepting deals less quickly. While people can sometimes walk away with no deal, the model in this experiment negotiates until it achieves a successful outcome.
Intelligent maneuvers: There were cases where agents initially feigned interest in a valueless item, only to later “compromise” by conceding it — an effective negotiating tactic that people use regularly. This behavior was not programmed by the researchers but was discovered by the bot as a method for trying to achieve its goals.
Producing novel sentences: Although neural models are prone to repeating sentences from training data, this work showed the models are capable of generalizing when necessary.
Building and evaluating a negotiation data set
In order to train negotiation agents and conduct large-scale quantitative evaluations, the FAIR team crowdsourced a collection of negotiations between pairs of people. The individuals were shown a collection of objects and a value for each, and asked to agree how to divide the objects between them. The researchers then trained a recurrent neural network to negotiate by teaching it to imitate people’s actions. At any point in a dialog, the model tries to guess what a human would say in that situation.
Unlike previous work on goal-orientated dialog, the models were trained “end to end” purely from the language and decisions that humans made, meaning that the approach can easily be adapted to other tasks.
To go beyond simply trying to imitate people, the FAIR researchers instead allowed the model to achieve the goals of the negotiation. To train the model to achieve its goals, the researchers had the model practice thousands of negotiations against itself, and used reinforcement learning to reward the model when it achieved a good outcome. To prevent the algorithm from developing its own language, it was simultaneously trained to produce humanlike language.
To evaluate the negotiation agents, FAIR tested them online in conversations with people. Most previous work has avoided dialogs with real people or worked in less challenging domains, because of the difficulties of learning models that can respond to the variety of language that people can say.
Interestingly, in the FAIR experiments, most people did not realize they were talking to a bot rather than another person — showing that the bots had learned to hold fluent conversations in English in this domain. The performance of FAIR’s best negotiation agent, which makes use of reinforcement learning and dialog rollouts, matched that of human negotiators. It achieved better deals about as often as worse deals, demonstrating that FAIR’s bots not only can speak English but also think intelligently about what to say.
Reinforcement learning for dialog agents
Supervised learning aims to imitate the actions of human users, but it does not explicitly attempt to achieve an agent’s goals. Taking a different approach, the FAIR team explored pre-training with supervised learning, and then fine-tuned the model against the evaluation metric using reinforcement learning. In effect, they used supervised learning to learn how to map between language and meaning, but used reinforcement learning to help determine which utterance to say.
During reinforcement learning, the agent attempts to improve its parameters from conversations with another agent. While the other agent could be a human, FAIR used a fixed supervised model that was trained to imitate humans. The second model is fixed, because the researchers found that updating the parameters of both agents led to divergence from human language as the agents developed their own language for negotiating. At the end of every dialog, the agent is given a reward based on the deal it agreed on. This reward was then back-propagated through every word that the agent output, using policy gradients, to increase the probability of actions that lead to high rewards.
What’s next
This work represents an important step for the research community and bot developers toward creating chatbots that can reason, converse, and negotiate, all key steps in building a personalized digital assistant. Working with the community gives us an opportunity to share our work and the challenges we’re aiming to solve, and encourages talented people to contribute their ideas and efforts to move the field forward.








