
Every day, more than a billion people turn to Facebook to connect with one another. This is especially true during times of crisis, when communication is critical both for those in the affected area and for those far away who are anxious for news from their loved ones.
After years of seeing people in crisis situations turn to Facebook to let friends know they're safe, we launched Safety Check in 2014 as a tool to help people stay in touch when major disasters strike. Safety Check helps you share your status with friends and family, check on others in the affected area, and mark your friends as safe.
Since our first activation in December 2014 for Typhoon Ruby, more than a billion people have received the news of a friend being marked safe in a crisis. We started with natural disasters and then expanded to include non-natural incidents, launching with an increased frequency to mirror this broadened scope. Between January and May 2016, we've activated Safety Check 17 times, compared with 11 times in 2014 and 2015 combined.
As our efforts ramped up, the team began solving the technical challenges associated with more consistent and frequent activations. To create a system that we can launch anywhere at a moment's notice, we scaled our infrastructure to handle larger events more efficiently and automated many of the manual steps previously required for activation.
The algorithm behind activation
One of Safety Check's strengths is its ability to identify people who are likely in an affected area, collect their safety status, and quickly send that information out to friends and family. We want to reach people and spread the good news as quickly as possible.
This goal immediately presented new challenges. Most products at Facebook are “pull” models, meaning we present some kind of experience when you open the Facebook app. Safety Check is a “push” model, meaning we proactively send everyone in the affected area a notification asking if they are safe.
The push model presents a difficult problem when launching Safety Check: How do we quickly find all the people likely to be in the affected area? Previous activations have ranged from a small city in Canada with only 60,000 residents to more than 20 million people in Ecuador after an earthquake. We needed an approach that could handle this range of population sizes with both accuracy and speed, but also remain stable and ready to launch at a moment's notice.
To solve this challenge, we considered a few approaches:
First, we considered having a reverse index for every person who encoded his or her current location. We could then leverage this reverse index during launch to look up the people who were in a given city, region, or country. The issue with a reverse index is that it requires a large amount of storage and computing power to maintain, which isn't practical for a product that we'd seldom launch. There is also a natural tradeoff between accuracy and maintaining such a large reverse index; the more often we update the index, the more accurate the product would be, but also the more resources the index would require.
The second approach was to perform a massively distributed async job on every Facebook profile: The job would check if someone was in the area and, if so, send him or her a notification for the crisis, then continue on to the next person. Although this seems attractive when considering large areas of activation, in which any given person has a high chance of being invited, it's less efficient for small activations, where that chance is much lower or approaches zero.
Instead, we ended up leveraging the social graph. The fabric of friendships on Facebook aids our ability to roll out Safety Check quickly and effectively. The high-level overview of the process is as follows:
- When a crisis is activated, we instantly run a small piece of code, or “hook,” that executes after every News Feed load.
- Once someone in the affected area of the crisis (Person A) loads his or her News Feed, we immediately invite that person to mark himself or herself safe with a feed prompt and a notification.
- Now that we have prompted Person A, we know it's fairly likely that he or she is friends with others in the affected area (because friendships are often geographically based). We want to find these people and invite them, but doing that all in the context of a single web request would be too resource intensive. Instead, we schedule a job in our generalized worker pool of machines, called the “async tier,” to asynchronously iterate through all of Person A's friends.
- When we find a friend in the area during this check (Person B), we send Person B a push notification that invites him or her to Safety Check. We then recursively schedule the same job on Person B to check on Person B's friends. This gives us a parallel and distributed version of breadth-first search across the social graph, where we continue iterating as long as the current person being examined is in the affected area.
- Since we remember which people have been invited, we don't perform recursive searches if we revisit those profiles. In practice we can exhaust a small graph of ~100,000 people in just minutes, with larger areas of millions of people taking only 10 to 15 minutes at full capacity.
Obeying a digital speed limit
While the above process is quite effective in practice, it could quickly schedule an enormous number of jobs, depending on the size of the affected area and the density of the social graph. If we were to assume that each person on Facebook has 500 friends, we could be scheduling more than 125 million jobs after just three levels of graph traversal. To our automated systems, this would look like the job was growing out of control.
Our async tier has automatic schedule throttling built in, so this upper bound would not be reached in practice. However, triggering this throttling fires a number of alerts that require manual responses from engineers. As we scaled the product to activate more frequently, we prevented these alerts by leveraging a new internal rate-limiting service that provides high-throughput, low-latency counting infrastructure. When the count of incoming requests exceeds a specified limit, additional requests are rejected probabilistically. This essentially gives us a great way to obey a “speed limit” across all of our jobs in all of our data centers. We specify a given QPS (queries per second) at which we want to operate, and the rate-limiter service provides the “stop or go” response we need.
Here we see this speed limit at work during a real activation. Our async job quickly ramps to the desired QPS and then holds that approximate value consistently during rollout.
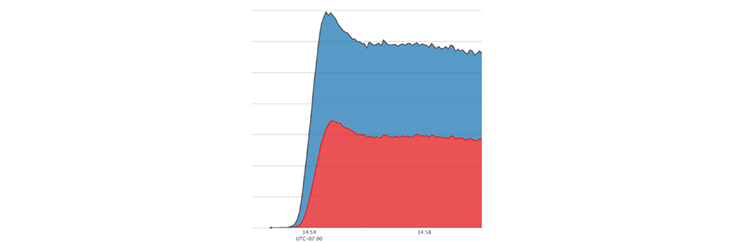
The last challenge was dealing with the initial propagation delay, or the time when counters are not yet synchronized across data center regions. Even though this propagation delay is only a few seconds, the “hook” in News Feed that kicks off our algorithm executes on almost every web request instantly when we launch. Since all the counters appear to be at 0 during this small window, we could inadvertently over-schedule jobs during the initial propagation delay window. Our solution was simple: For the first few seconds of a launch, we simply bump the counters without scheduling the job. This ensures that after about 5 seconds, our counters are at reasonable levels, and we can confidently begin scheduling at or below our desired QPS.
24/7 testing and preparedness
Most products on Facebook are used around the clock globally. Engineers who test changes in infrastructure can be fairly confident that every code path has been executed within just 48 to 72 hours of a deployment. By contrast, Safety Check launches are fairly infrequent, large in volume, and concentrated in time. This makes for usage patterns that are hard to continually test in production, since we are not deploying every minute of every day.
To ensure that Safety Check would work correctly at a moment's notice, we created a proactive testing system to perform “shadow launches” every 12 hours for a wide range of geographic areas. These tests also include other variables, such as locations, device classes, network conditions, and usage patterns, to ensure that we get a broad sampling of people and scenarios. A shadow launch executes the above invite algorithm, but logs to a database instead of sending notifications. After a few hours, we collect the number of people found, compare that against historical expected bounds, and report the results to the team. With this testing in place, we can be confident that Safety Check is ready to launch at any moment, despite continual changes and deployments in underlying infrastructure.
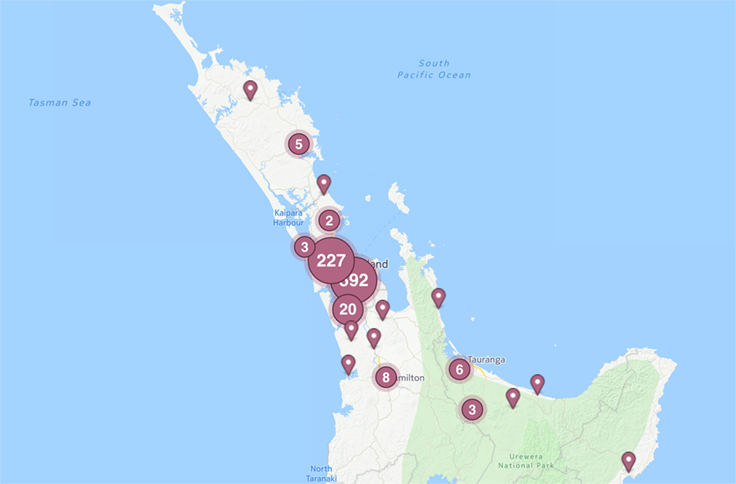
You can see an example of this logging for a shadow launch in Auckland, New Zealand. Our rollout algorithm identified a sample of people on Facebook either in Auckland or with Auckland listed as their current city; as a result, most of the sample population was found in the specified city with a sprinkling of people traveling across the country.
Automating deployment
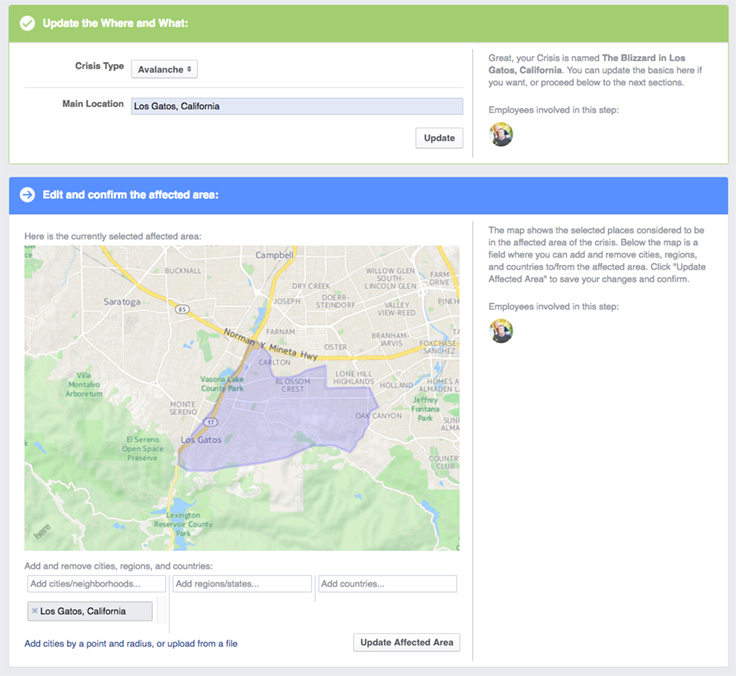
Once our infrastructure was solid, we wanted to scale and automate as much of the process around activating Safety Check as possible. Previously, an engineer was required to manually input data and perform SQL queries to launch, which meant we depended on a few number of employees all located in one time zone.
Unfortunately, disasters can strike at any moment and with little notice, so we built a new internal tool that enables trained teams across time zones to activate Safety Check any time of day for any event in the world, without having to depend on an engineer to do so.
Crisis Bot born on Messenger
After scaling the launch process, we then needed to address the post-launch procedure. We monitor every launch to ensure quality, but pulling these data reports used to be a manual and time-consuming process.
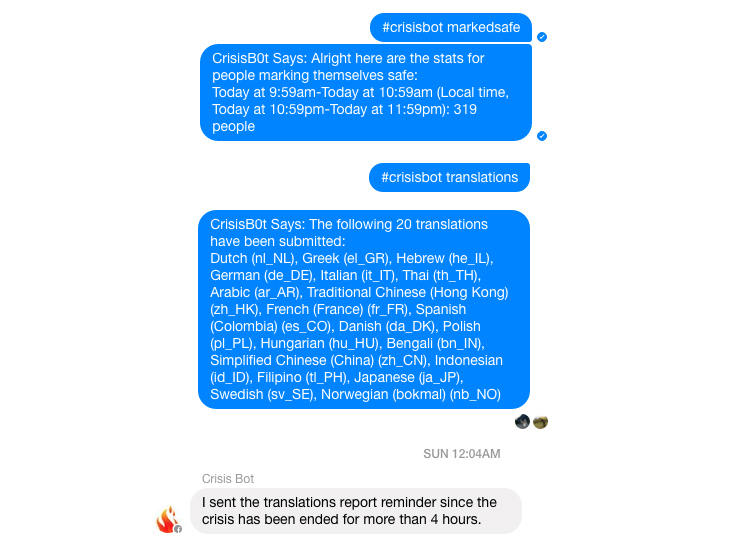
To automate this task, we built an internal bot for Messenger to both continuously monitor new launches and provide on-demand data reports. This allowed us to migrate our entire launch monitoring process to mobile and colocate it where the discussions are happening — in Messenger itself.
What's next
Now that we can create, deploy, and measure Safety Check activations programmatically, we're looking into new product possibilities. We're excited to continue working on Facebook's role in crisis response over the coming year, as well as to test new ways for the community to initiate and spread Safety Check in the coming weeks.








