
- One of the primary goals of efficient data center infrastructure is to extract the maximum amount of compute capacity while expending the least power.
- At Facebook, our web servers must process an increasingly large number of requests simultaneously while responding to each individual request as quickly as possible. To keep up with this growing performance demand, we have used processors with progressively more power over the past 10 years.
- Given a finite power capacity, this trend was no longer scalable, and we needed a different solution. So we redesigned our web servers to pack more than twice the compute capacity in each rack while maintaining our rack power budget. We also worked closely with Intel on a new processor to be built into this design.
- This design provides a significant improvement in performance per watt over the previous generation-over-generation trajectory. With this system implemented, we can achieve the same performance per watt today that would have otherwise required multiple new server generations.
Scaling Facebook’s computing infrastructure to be as efficient and cost-effective as possible has been a consistent focus of our engineering efforts. Over the past several years, we have reimagined nearly every component of our data centers — from custom-designed servers and racks to the software that runs on top of them — and we’ve made our designs open to others in the industry through the Open Compute Project.
One thing that has remained constant in our data centers is the use of two-processor servers with progressively more powerful Intel CPUs. About every two years, Intel provided a new generation of more powerful chips that came with a steady rate of improvement in performance over the previous generation. But the thirst for higher performance across the industry pushed Intel’s CPUs to operate at an increasing power limit, which became a more difficult problem with every generation and ultimately would stop being scalable.
Rather than leave this problem solely in Intel’s hands and accept the fact that our performance improvement trajectory would flatten over time, we approached Intel about working together to come up with a solution. We worked closely with them on the design of a new processor, and in parallel redesigned our server infrastructure to create a system that would meet our needs and be widely adoptable by the rest of the industry. The result was a one-processor server with lower-power CPUs, which worked better than the two-processor server for our web workload and is better suited overall to data center workloads. With this new system, not only were we able to avoid the flattening performance trajectory, but we could leapfrog the performance cadence we had been on for the past five server generations, as well. The system also operates within the same rack power budget, making our data centers more efficient than ever before.
Defining the problem: Increasing web-server workload
In Facebook’s cluster architecture, each cluster consists of more than 10,000 servers. Most of our user traffic comes through the front-end clusters, and web servers represent a major portion of the front-end cluster. These web servers run HHVM, an open-source virtual machine designed for executing programs written in Hack and PHP. HHVM uses a just-in-time compilation approach to achieve superior performance while maintaining the development flexibility that PHP provides.
At a high level, this workload is simultaneously latency-sensitive and throughput-bound. Each web server needs to respond to a given user request quickly as well as serve requests from multiple users in parallel. In CPU terms, we require good single-thread performance and excellent throughput with a large number of concurrent threads. We have architected this workload so that we can parallelize the requests using PHP’s stateless execution model. There isn’t much interaction between requests on a given web server, allowing us to efficiently scale out across a large number of machines.
However, because we have a large code base and because each request accesses a large amount of data, the workload tends to be memory-bandwidth-bound and not memory-capacity-bound. The code footprint is large enough that we see pressure on the front end of the CPU (fetching and decoding instructions). This necessitates careful attention to the design of the caches in the processor. Frequent instruction misses in the l-cache result in front-end stalls, which affect latency and instructions executed per second.
We have been using traditional two-socket servers for more than five server generations now at Facebook. Because our web servers are heavily compute-bound and don’t require much memory capacity, the two-socket servers we had in production had several limitations. The server has a QPI link that connects the processors, which created a NUMA problem. It also requires an accompanying chipset that required more power. We kept pushing the performance (and hence power) envelope. Intel provided us with 95W, then 115W, and now 120W-130W CPUs to hit our performance targets. Given an 11kW rack level power budget, pushing the limits of CPU power was not scalable, and we were not seeing performance keep up with increased power.
Our current Haswell CPUs are produced based on Intel’s 14 nm process, with the next process generation being 10 nm. Over a number of decades, Intel’s performance improvements have steadily kept in line with Moore’s Law — but more recently their “tick-tock” cycle encompassing a new architecture and process transition has slowed.
Making a server-class CPU is difficult and something that we take for granted. Process transitions are also challenging, especially at such minuscule dimensions. We knew that Intel was solving a hard problem, but since our software was evolving at a rapid pace in parallel, we wanted to take this problem on as well and look at our system design through a new lens.
Building windmills, not walls
“When the winds of change blow, some people build walls and others choose to build windmills.” —Chinese proverb
Since web servers represent a major portion of the front-end cluster, we decided to focus our optimization efforts on this component of our fleet. Three years ago we started working with Intel to define the details of a new processor called Broadwell-D, part of Intel’s Xeon line of processors, that was better suited to data center workloads rather than enterprise. We minimized the CPU to exactly what we required. We took out the QPI links, which reduced costs for Intel and removed the NUMA problem for us, given that all servers would be one-socket-based. We designed for it to be a system-on-a-chip (SOC), which integrates the chipset, thus creating a simpler design. This single-socket CPU also has a lower thermal design power (TDP).
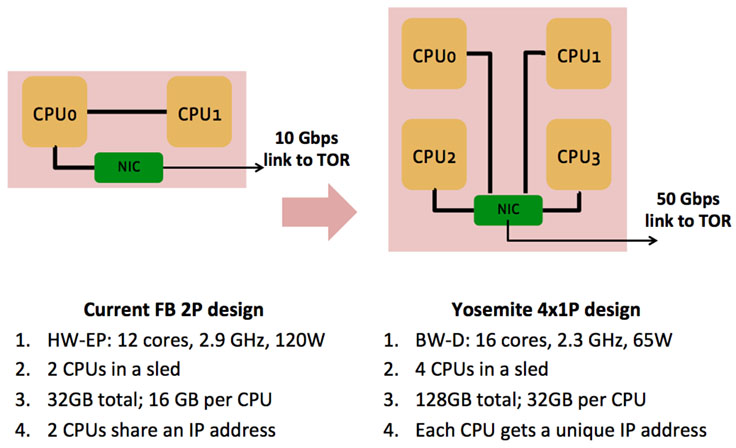
At the same time, we redesigned our server infrastructure to accommodate double the number of CPUs per rack within the same power infrastructure. Together, we designed a 4 CPU/sled server and 65W CPU that would land squarely in the sweet spot from a performance and power perspective. Facebook is limited by an 11kW rack power budget. We have 30 servers in a rack. At 120W per CPU, this allowed for 60 CPUs, while 65W would allow for 120 CPUs per rack within the same power infrastructure. While the math might look straightforward, it required a significant redesign of Intel’s roadmap to develop this new part.
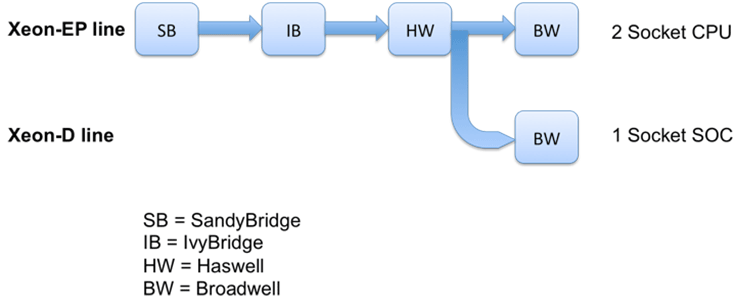
Modifying their roadmap is not an easy process given the complexity behind designing and manufacturing a processor. Intel calls this new line of products the Xeon-D line, and has made this line of parts plan of record for broader market adoption. We use Xeon-D and Broadwell-D (BW-D) interchangeably here.
Mono Lake
We wanted to build an infrastructure that consisted of a number of simple, modular building blocks, which would allow us to incorporate other compute logic (FPGAs or GPUs) in the future. Mono Lake is the server embodiment of Xeon-D and the building block for our SOC-based server designs. It is a highly simplified board that allows for the SOC to be placed with its associated memory and storage for boot and log. It currently has 32GB RAM and 128GB of storage (boot and log) associated with one Xeon-D CPU. Future designs can have increased memory and storage if required.

Yosemite
Process migrations and memory allocations hamper system performance. This becomes increasingly difficult and inefficient as servers send out requests for data to downstream services. After years of trying to fix this in software, we decided to fix it in the hardware and simplify the design in the process.
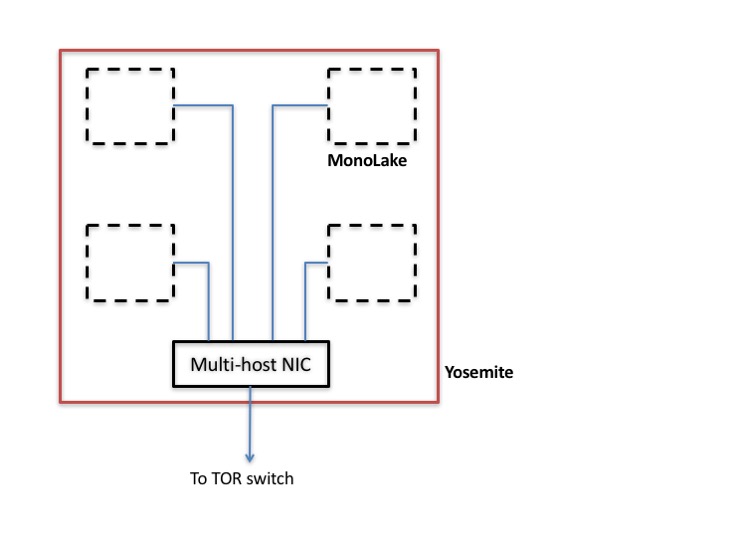
Yosemite is the sled that incorporates four Mono Lake boards and the associated NIC, where the CPUs are connected to the NIC via PCIe lanes and each server has an independent IP address. This design required the use of a multi-host NIC to aggregate the bandwidth from the four servers. The output of the NIC is currently designed to be 2×25 Gbps, which is dynamically shared across the four CPUs. Aggregating ports at the sled level makes for more efficient usage of the top-of-rack (TOR) ports.
Given that there is no direct link between the servers, the NUMA issue is eliminated by design. CPUs on a given sled can communicate with each other via a simple switch in the NIC rather than going through the TOR switch.

Performance summary
Xeon-D provides a significant improvement in performance per watt. It allows us to break away from the trajectory we have been on and shows the benefit of working in the sweet spot rather than just pushing the boundaries of single-CPU power performance. The performance of a single 65W processor is reduced compared with a 120W processor, but not significantly, given that the CPU is working at an efficient point in the process. The gains from doubling the number of CPUs in the rack far outweighed the performance loss of a single processor. Dropping the TDP below 65W dropped the performance per CPU to unacceptable levels. This is one of the reasons why Atom-class processors have not gained a foothold in large-scale distributed workloads.
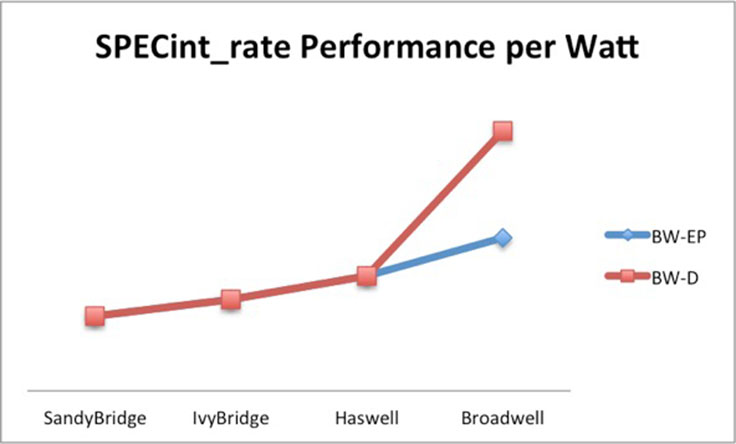
We found that for our web workload, a one-processor system has better performance per watt than a two-processor server. This resulted in a significant performance improvement and got us off the flattening generation-over-generation performance improvement trajectory that we have been on for the past five server generations.
A significant limitation of the current Xeon-D processor is the limited number of memory channels. It currently has two memory channels, which is acceptable for our current generation of web servers. Future SOCs would need to alleviate the memory capacity and bandwidth issues by increasing the number of channels.
LLC cache partitioning is a feature that we have worked closely on with Intel. Given our code size, we plan to create appropriate partitions for hot instructions and frequently accessed data, thus relieving memory bandwidth while improving performance. This is still being implemented in our infrastructure, and we are very excited about the potential benefits of this feature.
All of this was possible due to the close collaboration and tireless work of engineers at Facebook and our industry partners, but our journey is only 1 percent done. Exciting times are ahead!








