
Hardware RAID often comes with transparency, management, and support challenges. For example, if there is a failure in the array, it may not be immediately apparent which hard disk drive has the issue; even when a failed disk is identified, physical access to the server might be required to fix it. One workaround is to replace hardware RAID with software RAID. However, software RAID — particularly software RAID 5 and 6 — also has some drawbacks, which can be problematic at Facebook’s scale. Using a write-ahead log can address some of these issues and improve reliability of the array.
RAID 5 overview
Because RAID 5 and 6 are very similar, we’ll refer to these systems collectively as “RAID 5” to cover the challenges associated with both. RAID 5 is a RAID configuration that uses disk striping with a distributed parity. If one disk fails, data on the failed disk can be rebuilt from the distributed data and parity on other disks. The data from a stripe stored on one disk is called a chunk. This configuration introduces some interesting challenges.
The problems
- Write hole. If a power failure occurs during a write, the data and parity of the written stripe are only partially written to disks and don’t match, leaving the stripe in an inconsistent state. If there is a subsequent disk failure, rebuilding with inconsistent data and parity will generate an incorrect stripe, resulting in a rebuild that overwrites existing data with the corrupt data, even if the existing data was unaffected by the power failure.
- Rebuild performance. RAID 5 rebuilds after a power failure to make all stripes consistent. This process involves a whole disk read and possible write to all RAID disks, which can last from several hours to days. Software RAID 5 introduces a bitmap mechanism to speed up the rebuild, but the bitmap involves an extra disk write with a large disk cache flush, increasing normal I/O overhead.
- Write performance. If a write isn’t a full stripe write, the RAID 5 algorithm must do a read-modify-write, which has a penalty for both I/O throughput and latency. This doesn’t occur just with a random write; a sequential write with an fsync() syscall can expose this issue as well.
The solution
Despite the drawbacks of using software RAID, we’ve come up with a way to address these issues: a write-ahead log. All data and parity are first written to a log, then once in persistent media (i.e., not in disk cache), they are written to RAID disks. The log itself can use a checksum mechanism for consistency detection. In this way, the write-ahead log can solve some of the problems we mentioned:
- Write hole. The write-ahead algorithm guarantees a data and parity hit to RAID disks only after they are recorded in the log. After a power failure, the rebuild can discard the inconsistent part of the log, then use the consistent part to recover RAID disks. That way, the RAID array is guaranteed to be in a consistent state regardless of whether there is disk failure.
- Rebuild performance. When a write-ahead log is implemented, the RAID array is created in a consistent state and the log will have consistent data and parity. If the rebuild writes consistent data and parity from the log to RAID disks, the RAID array should be in a consistent state too. The rebuild set size with the log-based rebuild is then limited to the log data size, which is significantly smaller than RAID disk size (several GB versus several TB).
- Write performance. When we write data to the log first, we can delay the write to RAID disks, giving us the opportunity to aggregate several writes to a single full stripe write and avoid the read-modify-write penalty. This is particularly helpful for the sequential write with fsync() workload.
The implementation and status
We’re currently using an SSD as the write-ahead log. This implementation allows us to use a typical log structure, which starts with a metadata block followed by RAID 5 data/parity blocks. Several of these metadata and data/parity block pairs make up the log. There is a super block pointing to the first valid metadata. The metadata mainly records data/parity position in RAID disks and checksum for consistency consideration. Its main fields are:
- A magic number
- Metadata size
- Metadata checksum
- Sequence number
- RAID 5 data/parity position in RAID disks
- RAID 5 data/parity checksum
The magic number, sequence number, and metadata checksum guarantee metadata consistency. The sequence number also helps identify log head and tail. The data/parity checksum is an important performance optimization, as it allows metadata and data/parity write to log the disk as out of order. Otherwise, the writes would have to be strictly ordered and an expensive disk cache flush must be added to guarantee consistency.
Like other log structures, proper reclaim is required when the log size is big. Since RAID 5 data/parity that is already persistent in RAID disks can be discarded from the log, reclaim can simply flush data/parity from log disk to RAID disks.
The main advantage of a write-ahead log is improved reliability. That means the array should work in extreme scenarios — for example, I/O errors, disk loss, crash recovery with disk loss, and so on. Existing Linux RAID 5 implementation can handle these scenarios for RAID disks, and we add corresponding support for the log disk. Our current practice is to prevent further data corruption if an error like this happens. If the log disk is lost, for example, the RAID 5 array will forcibly enter a read-only mode.
Our use of the write-ahead log fixes the write hole and rebuild performance issues. In the future, we’ll also be focusing on write performance improvement, as we can alternatively use flashcache/bcache to address this currently. The code is merged to Linux 4.4 kernel.
Performance
Testing can be conducted using typical hard disks, and the log disk is a M.2 SSD (versus a higher-end option). The SSD performs at about 450 MB/s peak write. The raid array tested is created with 256 K chunk size.
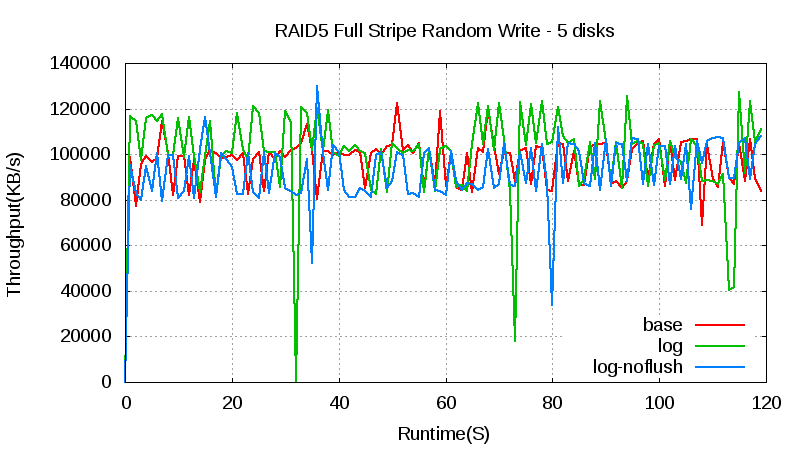
In a RAID 5 array with five hard disks, the throughput with or without the log doesn’t change. The throughput with the log has some jitters, however, which is caused by the SSD write jitter and SSD disk cache flush.
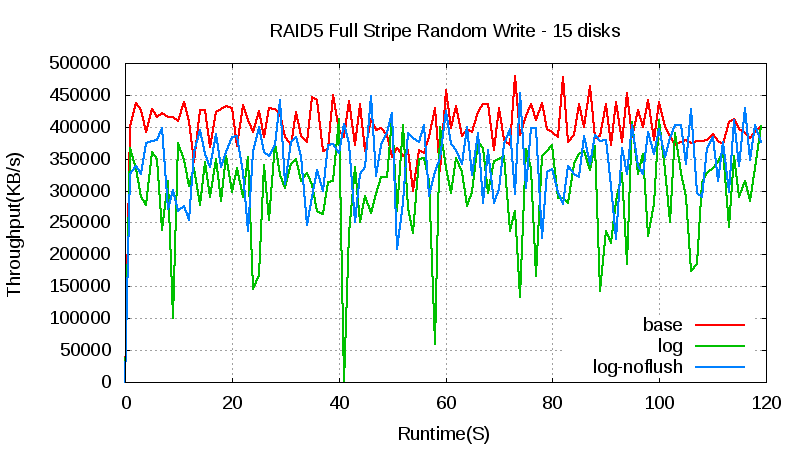
In a RAID 5 array with 15 hard disks, the throughput with the log drops around 25 percent compared with the throughput without the log. We attribute this drop to the SSD’s slow disk cache flush (it’s a SATA SSD). In SATA, cache flush command isn’t an NCQ command, so it has sizable overhead. If we delete the flush (the log-noflush line in the chart above), the throughput is around 10 percent less than that without log. We expect that the throughput loss isn’t a big problem with a high-end SSD or NVRAM/NVDIMM because it doesn’t have the flush problem and is faster. There are more jitters with log, similar to the five-disk array, but because throughput is higher, the jitter happens more frequently.
Future work
- Testing and bug fixes. Reliability is our main goal, so we’re working to make sure our RAID array with log works well in destructive tests.
- Performance. Currently the target usage is to improve reliability for hard-disk-based array, so performance isn’t a big concern. We’re always looking for new opportunities for fast storage. For example, each RAID 5 stripe enters stripe handling state machine two more times with log, which could be a problem with fast storage.
- NVRAM/NVDIMM support. NVRAM/NVDIMM can act as a normal block device, so current code can largely be reused, but proper optimization is required.
- Write performance improvement. The on-disk format of the log structure should work for the full stripe optimization.
Thanks to Song Liu for writing the code to support log in software RAID utility. Thanks to Neil Brown and Christoph Hellwig from the community for helping review and contribute patches.








