
Two billion photos are shared daily on Facebook services. Many of these photos are important memories for the people on Facebook and it's our challenge to ensure we can preserve those memories as long as people want us to in a way that's as sustainable and efficient as possible. As the number of photos continued to grow each month, we saw an opportunity to achieve significant efficiencies in how we store and serve this content and decided to run with it. The goal was to make sure your #tbt photos from years past were just as accessible as the latest popular cat meme but took up less storage space and used less power. The older, and thus less popular, photos could be stored with a lower replication factor but only if we were able to keep an additional, highly durable copy somewhere else.
Instead of trying to utilize an existing solution — like massive tape libraries — to fit our use case, we challenged ourselves to revisit the entire stack top to bottom. We're lucky at Facebook — we're empowered to rethink existing systems and create new solutions to technological problems. With the freedom to build an end-to-end system entirely optimized for us, we decided to reimagine the conventional data center building itself, as well as the hardware and software within it. The result was a new storage-based data center built literally from the ground up, with servers that power on as needed, managed by intelligent software that constantly verifies and rebalances data to optimize durability. Two of these cold storage facilities have opened within the past year, as part of our data centers in Prineville, Oregon, and Forest City, North Carolina.
The full-stack approach to efficiency
Reducing operating power was a goal from the beginning. So, we built a new facility that used a relatively low amount of power but had lots of floor space. The data centers are equipped with less than one-sixth of the power available to our traditional data centers, and, when fully loaded, can support up to one exabyte (1,000 PB) per data hall. Since storage density generally increases as technology advances, this was the baseline from which we started. In other words, there's plenty of room to grow.
Since these facilities would not be serving live production data, we also removed all redundant electrical systems — including all uninterruptible power supplies (DCUPS) and power generators, increasing the efficiency even further.


To get the most data into this footprint, we needed high density, but we also needed to remain media-agnostic and low-frills. Using the theme that “less is more,” we started with the Open Vault OCP specification and made changes from there. The biggest change was allowing only one drive per tray to be powered on at a time. In fact, to ensure that a software bug doesn’t power all drives on by mistake and blow fuses in a data center, we updated the firmware in the drive controller to enforce this constraint. The machines could power up with no drives receiving any power whatsoever, leaving our software to then control their duty cycle.
Not having to power all those drives at the same time gave us even more room to increase efficiency. We reduced the number of fans per storage node from six to four, reduced the number of power shelves from three to one, and even reduced the number of power supplies in the shelf from seven to five. These server changes then meant that we could reduce the number of Open Rack bus bars from three to one.
After modifying Open Rack to support these power-related hardware tweaks, we were able to build racks with 2 PB storage (using 4 TB drives) and operate them at one-quarter the power usage of conventional storage servers.
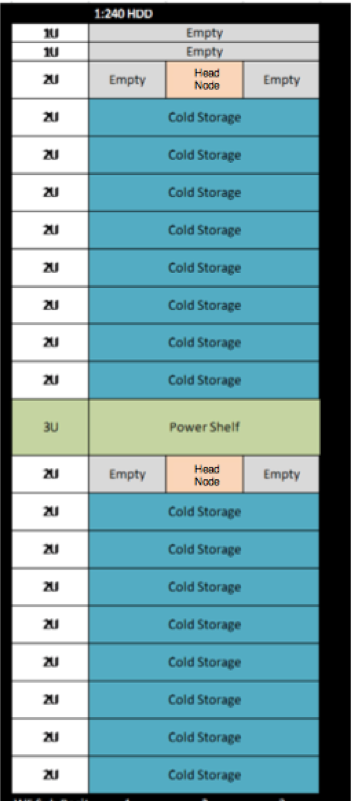
We knew that building a completely new system from top to bottom would bring challenges. But some of them were extremely nontechnical and simply a side effect of our scale. For example, one of our test production runs hit a complete standstill when we realized that the data center personnel simply could not move the racks. Since these racks were a modification of the OpenVault system, we used the same rack castors that allowed us to easily roll the racks into place. But the inclusion of 480 4 TB drives drove the weight to over 1,100 kg, effectively crushing the rubber wheels. This was the first time we'd ever deployed a rack that heavy, and it wasn't something we'd originally baked into the development plan!

Making it work
With our efficiency measures in place, we turned our attention to designing the software to be flexible enough to support our cold storage needs. For example, the software needed to handle even the smallest power disruptions at any time, without the help of redundant generators or battery backups, while still retaining the integrity and durability of the data on disk.
We approached the design process with a couple of principles in mind. First, durability was a main concern, so we built it into every system layer. We wanted to eliminate single points of failure and provide an ability to recover the entire system with as few pieces as possible. In fact, the separate system that managed the metadata would be considered a “nice to have” service for data recovery in case of catastrophic failure. In other words, let the data self-describe itself enough to be able to assist in recovery. After all, cold storage was intended to be the last point of recovery in case of data loss in other systems.
Second, the hardware constraints required careful command batching and trading latency for efficiency. We were working with the assumption that power could go away at any time, and access to the physical disks themselves would be limited based on the on/off duty cycle derived from the drive’s mean time before failure.
This last part was especially relevant since we were using low-end commodity storage that was by no means enterprise-quality.
We also needed to build for the future. Too often, we’ve all seen systems begin to get bogged down as they grow and become more utilized. So, right from the beginning, we vowed to make a system that not only didn’t degrade with size but also would get better as it grew.
Erasure coding and preventing “bit rot”
With the major system hardware and software decisions made, we still had several big unknowns to tackle: most notably, actual disk failure rates and reliability, and data center power stability, since cold storage would not include any battery backup. The easiest way to protect against hardware failure is to keep multiple copies of the data in different hardware failure domains. While that does work, it is fairly resource-intensive, and we knew we could do better. We wondered, “Can we store fewer than two copies of the same data and still protect against loss?”
Fortunately, with a technique called erasure coding, we can. Reed-Solomon error correction codes are a popular and highly effective method of breaking up data into small pieces and being able to easily detect and correct errors. As an example, if we take a 1 GB file and break it up into 10 chunks of 100 MB each, through Reed-Solomon coding, we can generate an additional set of blocks, say four, that function similar to parity bits. As a result, you can reconstruct the original file using any 10 of those final 14 blocks. So, as long as you store those 14 chunks on different failure domains, you have a statistically high chance of recovering your original data if one of those domains fails.
Picking the right number of initial and parity blocks took some investigation and modeling based on the specific drive’s failure characteristics. However, while we were confident our initial Reed-Solomon parameter selections matched current drive reliability, we knew this was a setting that had to be flexible. So we created a re-encoding service that could reoptimize the data to support the next generation of cheap storage media, whether it was more reliable or less so.
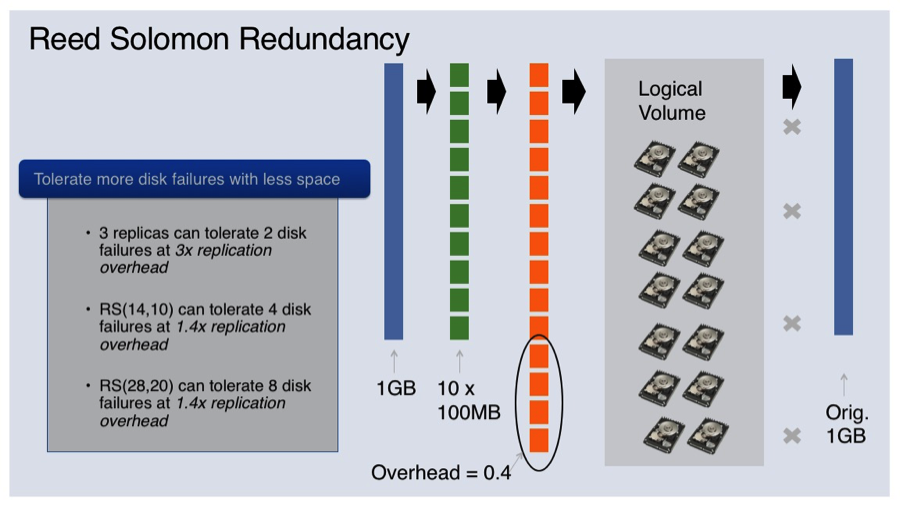
As a result, we can now store the backups for 1 GB of data in 1.4 GB of space — in previous models, those backups would take up larger amounts of data, housed across multiple disks. This process creates data efficiency while greatly increasing the durability of what's being stored. However, this is not enough. Knowing that there is always a high chance that data will get corrupted, we create, maintain, and recheck checksums constantly to validate integrity. We keep one copy of the checksums next to the data itself, so we can quickly verify the data and replicate it as fast as possible somewhere else if an error is detected.
We've learned a lot running large storage systems over the years. So we were particularly concerned about what’s affectionately known as “bit rot,” where data becomes corrupted while completely idle and untouched. To tackle this, we built a background “anti-entropy” process that detects data aberrations by periodically scanning all data on all the drives and reporting any detected corruptions. Given the inexpensive drives we would be using, we calculated that we should complete a full scan of all drives every 30 days or so to ensure we would be able to re-create any lost data successfully.
Once an error was found and reported, another process would take over to read enough data to reconstruct the missing pieces and write them to new drives elsewhere. This separates the detection and root-cause analysis of the failure from reconstructing and protecting the data at hand. As a result of doing repairs in this distributed fashion, we were able to reduce reconstruction from hours to minutes.
Bigger is better
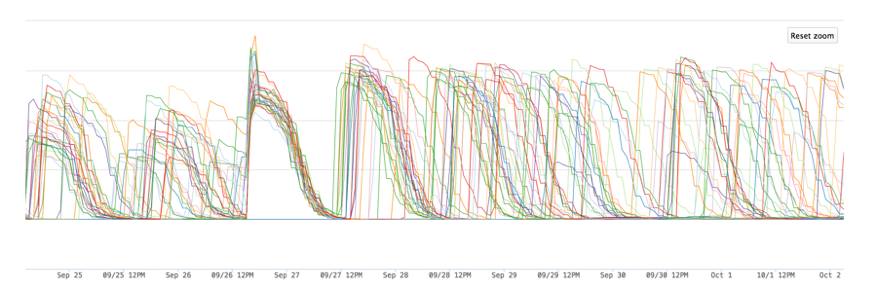
We wanted the system to get better as it got bigger, so we decided to treat new capacity as if it were always there. That is, as we add new capacity, the software will rebalance all existing data by moving it to new hardware and freeing up previously used space. This non-real-time process has the nice side effect of inherently supporting migrations from day one and treating all data with the same level of importance since even old data may get to live on new hardware for some time. The image below shows the rebalancer service running while respecting the drive power on/off cycles.
What’s next
By separating the storage of low-traffic content from that of high-traffic content, we’ve been able to save energy and other resources while still serving data when requested. Our two cold storage data centers are currently protecting hundreds of petabytes of data, an amount that's increasing every day. This is an incredible start, but as we like to say at Facebook, we’re only 1 percent finished.
We still want to dig into the wide range of storage mediums, such as low-endurance flash and Blu-ray discs, while also looking at new ways to spread files across multiple data centers to further improve durability.
One recent change that came to light only after we launched production was the fact that most modern file systems were not built to handle many frequent mounts and unmounts in fairly short times. We quickly began to see errors that were hard to debug since they were far below our software layer. As a result, we migrated all drives to a “raw disk” configuration that didn't use a file system at all. Now, we had deep visibility into the full data flow and storage throughout the system, which allowed us to feel even more confident about our durability guarantees.
A large number of people in multiple disciplines throughout the entire Infrastructure team worked on the cold storage project, and thus contributed to this blog post in their own unique way. Some joined the project as part of their regular jobs, while others did it as a dedicated initiative. Together, their joint contributions demonstrated a true entrepreneurial spirit spread across four offices in two countries and two data centers.
Special thanks to David Du, Katie Krilanovich, Mohamed Fawzy, and Pradeep Mani for their input on this blog post.








