
Audience Insights (AI) is a tool designed to help Page owners learn more about the people on Facebook who matter most to them. This product visualizes anonymous and aggregate demographic, psychographic, geographic, and behavioral data (both Facebook native and third party) about a given set of people.
AI needs to process queries over tens of terabytes of data in a few hundred milliseconds. These queries can include complex analytical computations. For example, you may want to better engage people between 18-21 years old in the US and learn what they are interested in. The AI can analyze all of your audience’s Page likes, as well as the other Pages each of these Pages has liked, in order to come up with a set of Pages that have high affinity with your audience. In this example, the top two Pages that describe the audience are “Above the Influence,” a non-profit to help teens stand up to negative influences, and “I hate when my parents rush me to get ready and then when I am, they’re not.” AI often needs to go through billions of Page likes to compute affinity analytics for your audience.
AI is powered by a query engine with a hybrid integer store that organizes data in memory and on flash disks so that a query can process terabytes of data in real time on a distributed set of machines. AI query engine is a fan-out distributed system with an aggregation tier and a leaf (data) tier. The aggregator sends a query request to all data nodes, which then execute the query and send back the local results to be aggregated.
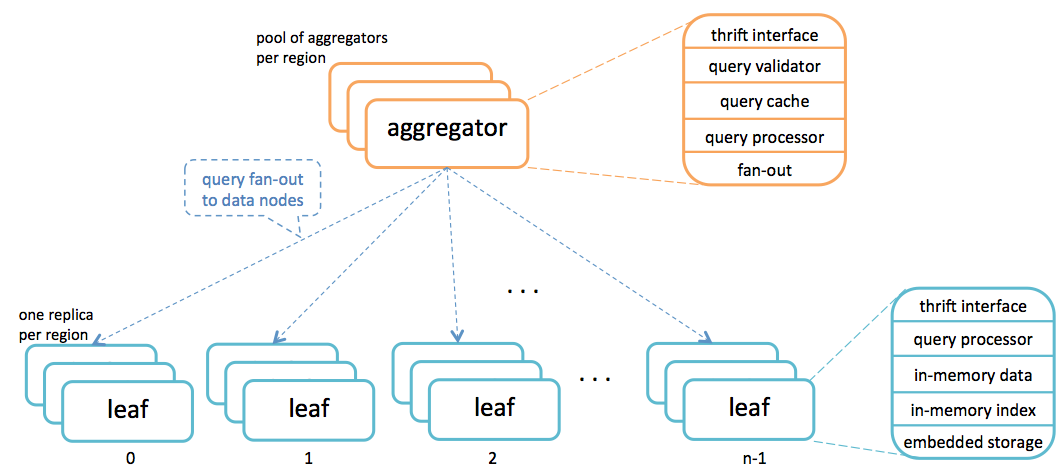
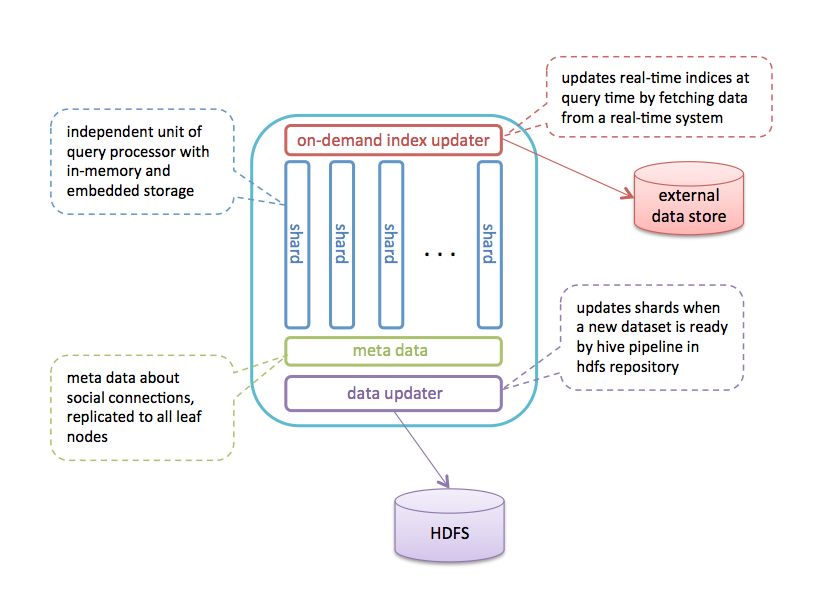
AI has two types of data: (1) attributes for people such as age, gender, country, etc., and (2) social connections such as Page likes, Custom Audiences, and interest clusters. These data sets are made up of anonymized integers. No real user IDs are kept in the system. Data is sharded by user, and there are total of 1024 shards distributed to 168 data nodes in one production cluster. For each shard, 35GB of raw data is copied to a data node to build the shard, which takes 8GB in memory and 4GB in embedded storage on flash disk. The total amount of data copied to one cluster is more than 35 terabytes, whose indices take a total of 8TB in memory, and 4TB on embedded storage. A small amount of metadata is replicated to all nodes. The query processor accesses the data in memory much more frequently than the data on embedded storage.
Data is updated in two ways: a batch update of all datasets, and a query-time update of certain indices. Batch updates happen daily once a new dataset is ready in the HDFS repository by a daily Hive pipeline. A background thread in each leaf node copies the data from HDFS storage and rebuilds the shards one by one. However, some indices require real-time updates. Query processors in leaf nodes initiate fetch operations at the query time to read data from an external data store and update the indices in the shards. Neither batch nor query-time updates are coordinated across shards, thus, the cluster is loosely consistent, and converges to a consistent state over time.
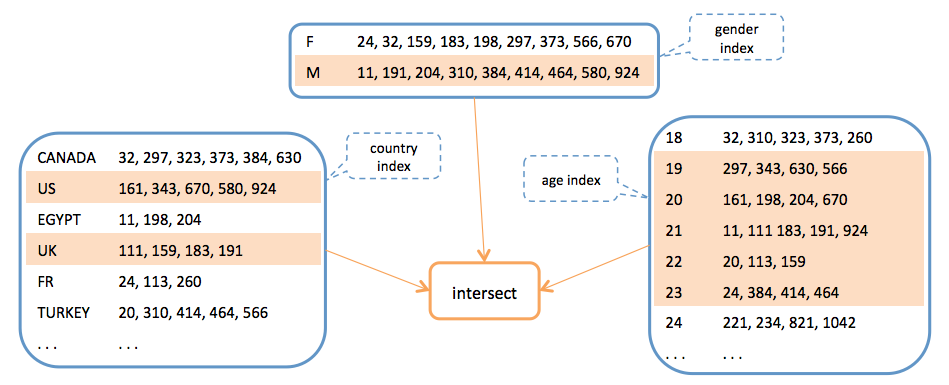
All attributes are indexed as inverted indices. At first we indexed them using traditional indexing, which maps the values to lists of user IDs as illustrated below. This indexing scheme required intersection operations to run multiple filters, which turned out to be computationally intensive on large datasets.
To eliminate intersection operations, we have replaced the user IDs with bitsets, where one bit per person indicates whether that person is indexed for a specific value of an attribute. Bitwise AND operation is now much faster than in intersection operations.
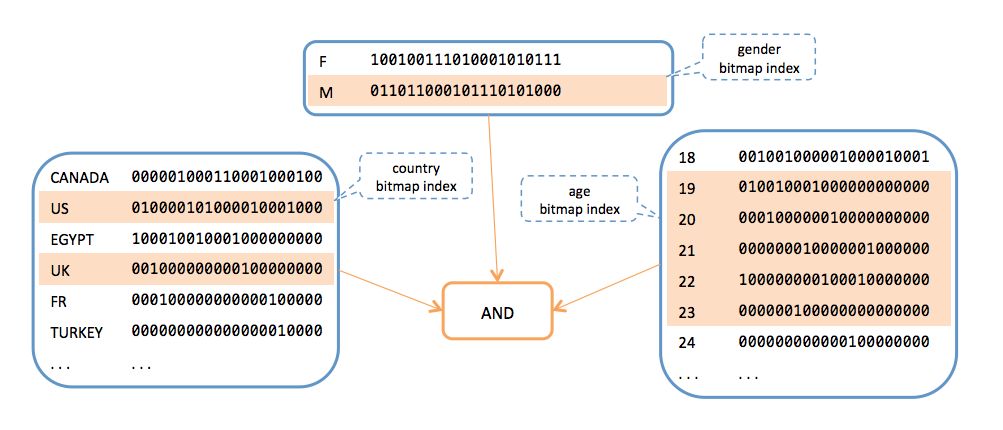
Furthermore, bitmap indices are cumulative to support fast range filters using XOR, reducing the number of OR operations needed for queries with range filters. For example, a filter for ages between 25 and 44 requires only one XOR operation between bitsets of 44 and 24 rather than 20 OR operations that would be needed if the indices were not cumulative. Note that each filter requires exactly one XOR operation no matter whether it is for a range of values or a single value.
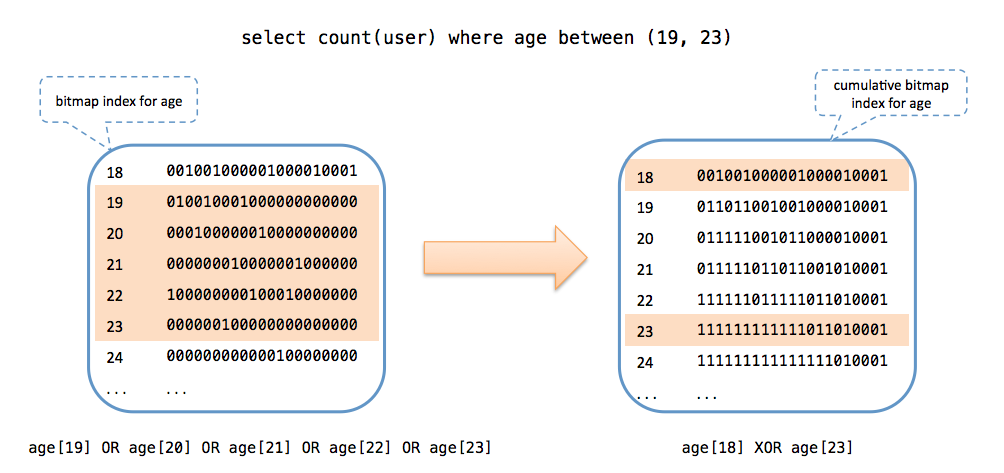
Memory requirement for bitmap indexing is proportional to the number of different keys that an attribute may have. The size of the bitset allocated for each key is fixed, and does not depend on the number of keys. To keep memory requirement under control, AI has a hybrid indexing system that indexes dense attributes as bitmaps and sparse attributes as traditional indexing. For example, the “age” attribute has a little more than a hundred keys, thus, bitmap indexing for it has a very small memory footprint; whereas the “city” attribute has close to a million different keys, requiring too much memory as bitmaps. The indices of sparse attributes are converted to bitmaps at the query execution time. Although this requires an additional step of conversion every time a filter is run for a sparse attribute, the conversion operation is very fast since each key leads to a sparse bitmap. On average, bitmap indexing has reduced our filter time from around 50ms to less than 5ms.
Besides complex statistical operators, the most time-consuming part of query execution is generally the group-by operation. Going over hundreds of millions of records and grouping them by the values means a lot of hash lookups with integers. Where possible, we use bitset-based filtering techniques inspired by bloom filters to reduce the number of hash lookups during group-by. We convert 64-bit integer entity IDs to a 32-bit vector index in each shard. This conversion gives us continuous integers, letting us eliminate hashing for counting operations in some statistical operators.
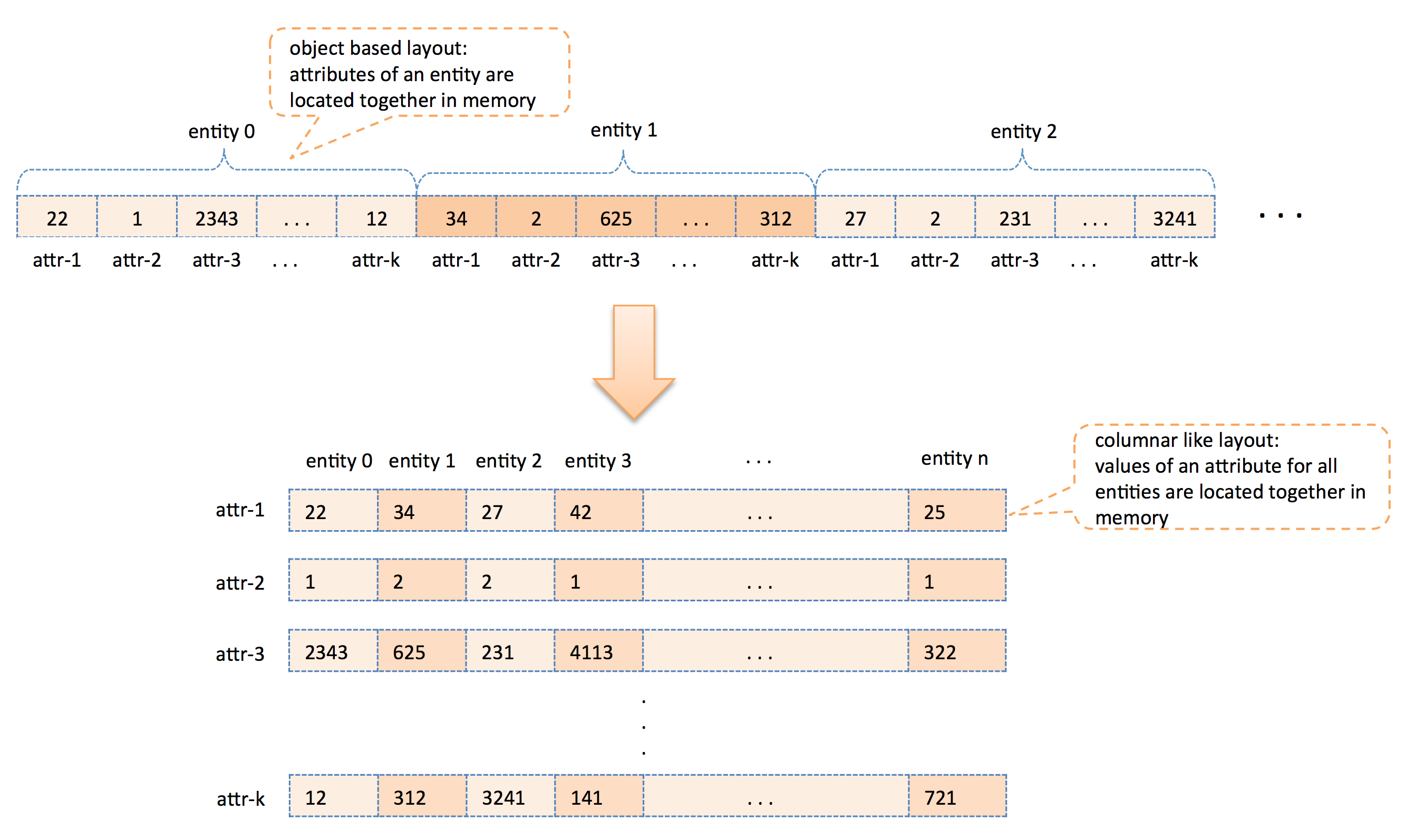
User attributes are organized in a columnar-like structure in memory. We first organized using objects in a collection, which led to the attributes of each user being located close to each other in memory. Since there are tens of attributes, this approach causes cache inefficiencies while iterating over a specific attribute of millions of entities because of long jumps. To increase cache efficiency, we have changed it to a columnar-like organization in which values for each attribute are in the same vector, resulting much smaller jumps during iterations.
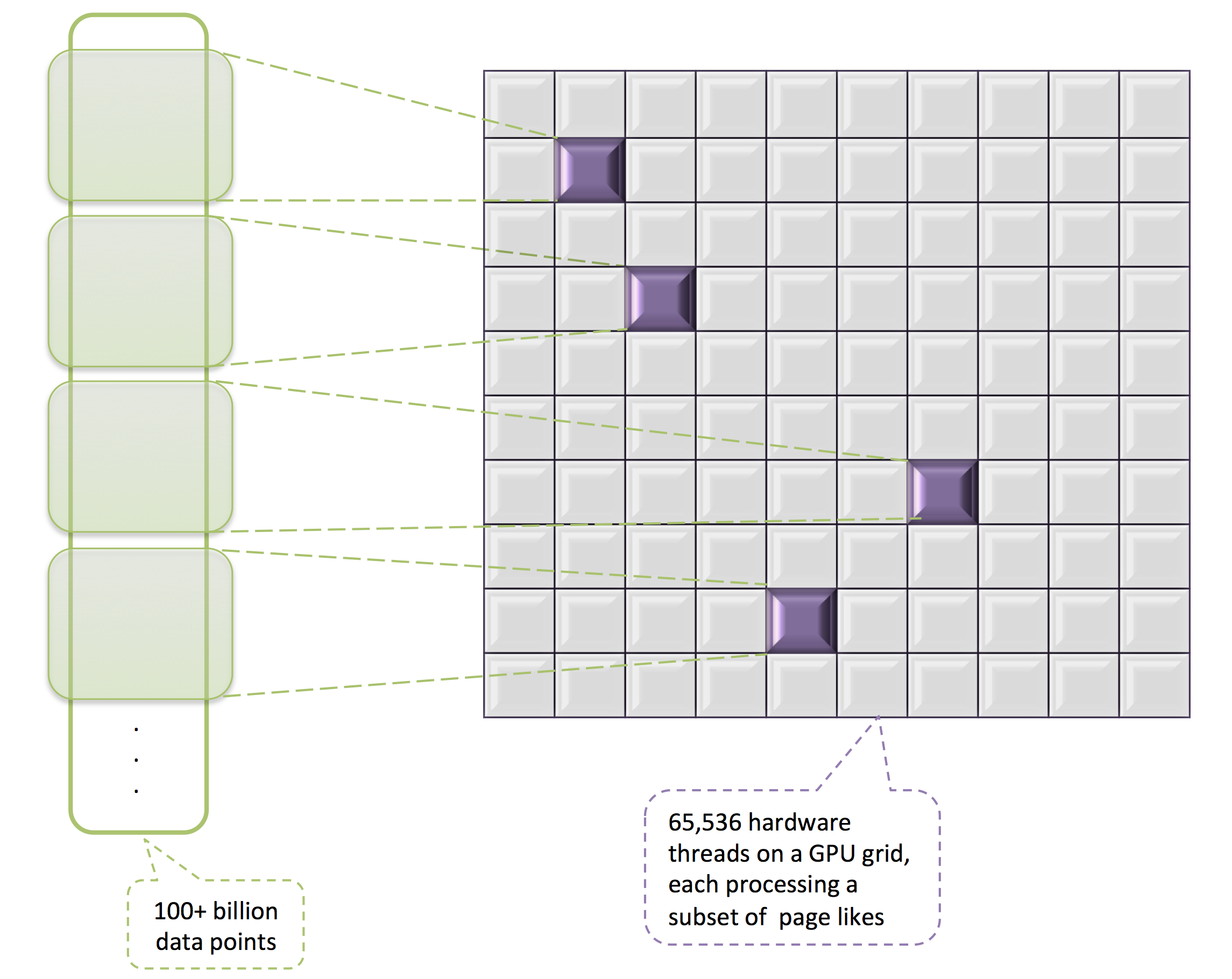
The Audience Insights query engine implements fairly complex statistical analytics to come up with a set of Pages that a defined audience has the highest affinity for. It computes the conditional probability of each Page being liked by the audience, and selects the most likely Pages, discovering the collective interests from Page connections that people form. It requires hundreds of billions of Page likes to be processed. The AI engine scales the affinity computation by locally computing the candidate pages at each shard, and applying a greedy selection over the candidates.
The AI engine can utilize GPU hardware when it exists to offload computationally complex operations like affinity computation, which takes up to 2500ms to compute for the whole Facebook audience. With GPU acceleration, it can compute affinity in less than 500ms, of which more than 300ms is on GPU, resulting in 90% save on CPU time.
The AI query engine is scalable. There are no dependencies between data nodes (leaves), and the data movement is in one direction only—from leaves to aggregators. There are currently 168 data nodes in each of three regions, amounting to 504 data nodes total. All regions are identical, serving the production traffic and at the same time providing redundancy for failover, as there are three copies of the same data. Each region has three aggregator machines receiving the front-end query requests.
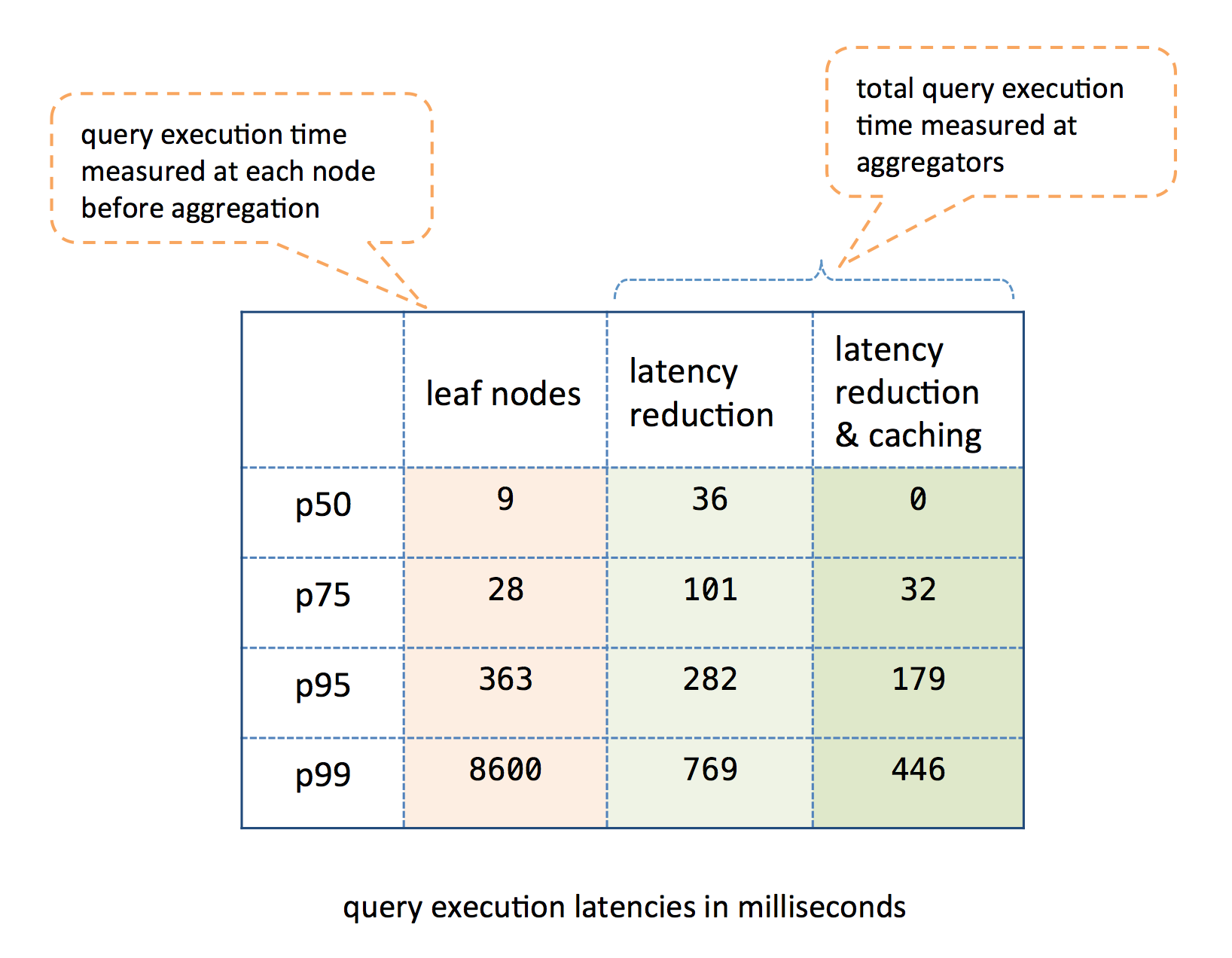
The query engine is CPU bound since it vastly operates on in-memory data, and has intensive statistical computations. Under our current production load, leaf query processing times for p50, p75, p95, and p99 are 9, 28, 363, 8600 milliseconds respectively. The high tail latency happens because of two main factors: (1) Random factors in the cluster such as machine issues and IO operations during a dataset update, making a few nodes take an unusual amount of time, and (2) High standard deviation among query times for different queries–especially queries with complex computations.
We have implemented tail latency reduction techniques to deal with (1). After fanning out the query to all leaf nodes, the aggregator tracks the execution times, and detects the high latency nodes relative to the ones that have responded. It cuts the execution for those nodes given a sufficient number of leaf nodes have already finished execution. It results in less than 100% data being processed. Since AI queries can tolerate a few percentage of missing data nodes, this technique works fine and cuts our tail latency. Thus, the query processing times reported at aggregators, without caching, for p50, p75, p95, p99 are 36, 101, 282, 769 milliseconds respectively –more than 90% reduction in p99 latency. With caching, those numbers are 0, 32, 179, 446 milliseconds. Note that p50 is zero because the cache, incurring sub-millisecond processing time, serves more than half of the query requests.
The AI query engine is implemented with C++ and uses Facebook’s internal frameworks and libraries. Looking forward, the next step for our query engine is to support time-series datasets, and organize data in a way that it could run real-time queries on an order-of-magnitude larger datasets. We hope to increase the ratio of data on embedded storage to keep the total memory requirement under control as it grows to petabyte-scale datasets.
Thanks also to Reid Gershbein, Wenrui Zhao, Maxim Sokolov, Scott Straw, and Ajoy Frank for their work designing and implementing the Audience Insights query engine.








