
By Sriram Sankar, Soren Lassen, and Mike Curtiss, who are building Graph Search’s infrastructure.
In the early days, Facebook was as much about meeting new people as keeping in touch with people you already knew at your college. Over time, Facebook became more about maintaining connections. Graph Search takes us back to our roots and helps people make new connections–this time with people, places, and interests.
With this history comes several old search systems that we had to unify in order to build Graph Search. At first, the old search on Facebook (called PPS) was keyword based–the searcher entered keywords and the search engine produced a results page that was personalized and could be filtered to focus on specific kinds of entities such as people, pages, places, groups, etc.
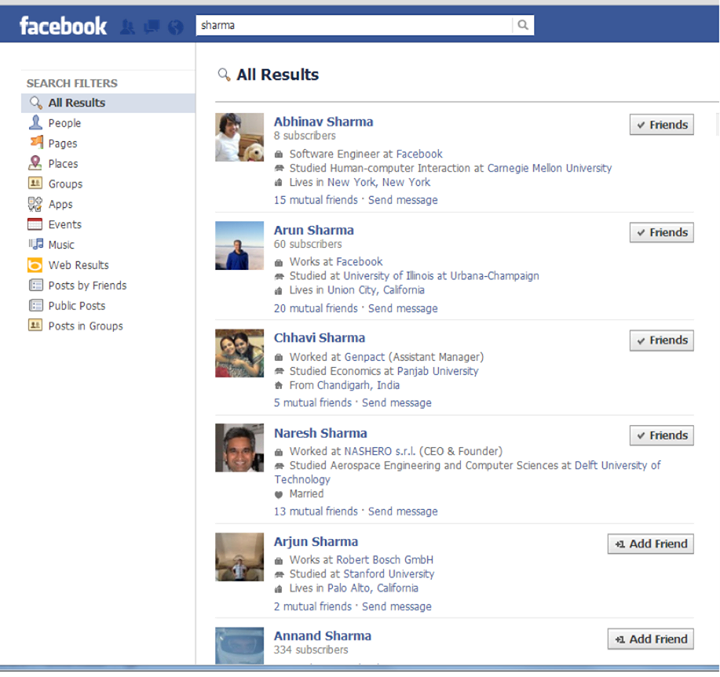
In 2009, Facebook started work on a new search product (called Typeahead) that would deliver search results as the searcher typed, or “prefix matching.” This product required a complete reimplementation of the backend and frontend for prefix matching and high performance. We launched this overhaul in 2010.
Many algorithms went into the design of Typeahead, but in order to achieve its performance goals and deliver results in an acceptable amount of time, the index capacity remained limited. To maintain recall, Typeahead passed searchers to PPS when they asked to see more results.
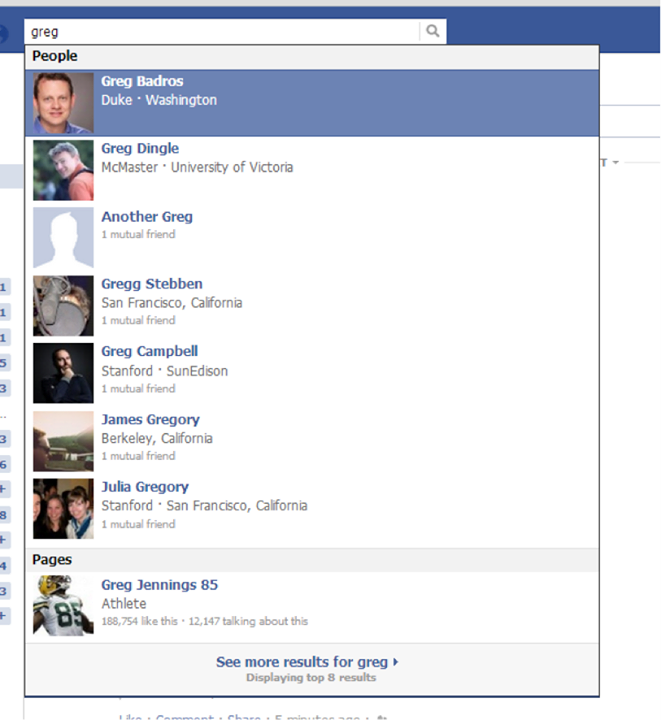
In addition to PPS and Typeahead, there are other products that feature search, like Nearby, tagging within posts, and location tagging of posts and photos – some of which had their own backends. In order to make Graph Search work, and return high-quality results, we needed to create an index that would support all of these systems and allow for the richer queries of Graph Search.
A Crash-Course in Graph Structure
The Facebook graph is the collection of entities and their relationships on Facebook. The entities are the nodes and the relationships are the edges. One way to think of this is if the graph were represented by language, the nodes would be the nouns and the edges would be the verbs. Every user, page, place, photo, post, etc. are nodes in this graph. Edges between nodes represent friendships, check-ins, tags, relationships, ownership, attributes, etc.
Both nodes and edges have metadata associated with them. For example, the node corresponding to me will have my name, my birthday, etc. and the node corresponding to the Page Breville will have its title and description as metadata. Nodes in the graph are identified by a unique number called the fbid.
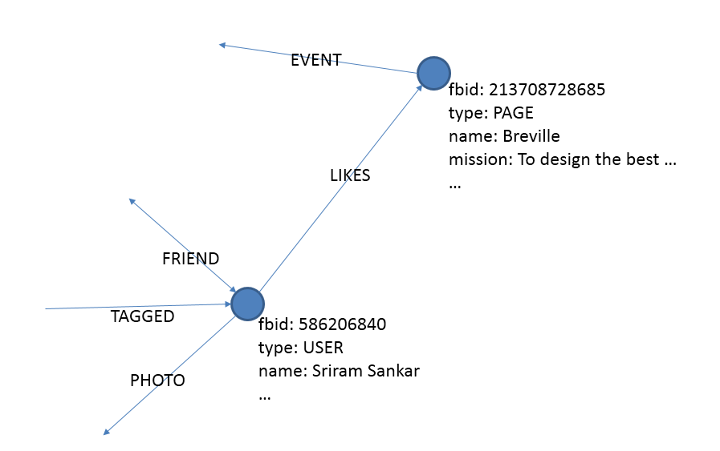
The Facebook graph contains social information, such as friendships and likes, in addition to information relevant for everybody–e.g., the relationship between Queen Elizabeth and George VI and the history of Star Wars. This blend of general information and social context in a single graph makes Facebook a rich source of content, and a unique data set.
Designing a System for Graph Search
PPS and Typeahead search Facebook entities based on their metadata–primarily using their name (title). The kinds of entities searched are users, pages, places, groups, applications, and events. The goal of Graph Search was to extend this capability to also search based on the relationship between entities–meaning we are also searching over the edges between the corresponding nodes. We chose to use natural language as the input for the queries, as natural language is able to precisely express the graph relationships being searched over. For example:
- Restaurants liked by Facebook employees
- People who went to Gunn High School and went to Stanford University
- Restaurants in San Francisco liked by people who graduated from the Culinary Institute of America
Decision to use Unicorn
As we’ve mentioned in previous posts, we realized that Graph Search would require the building of a very large index. For example, we would have to index every single “check-in” (since queries can ask about this), whereas previously we could aggregate check-in information since it was only used as a ranking signal. So we needed a search infrastructure that would scale. We were also getting overwhelmed by supporting multiple search backends–so we saw this as an opportunity to move to a single search backend–in order to make the development and maintenance process more efficient.
There was an effort within Facebook to build an inverted-index system called Unicorn since 2009. By late 2010, Unicorn had been used for many projects at Facebook as an in-memory “database” to lookup entities given combinations of attributes. In 2011, we decided to extend Unicorn to be a search engine and migrate all our existing search backends to Unicorn as the first step towards building Graph Search.
The main components of Unicorn are:
- The index — a many-to-many mapping from attributes (strings) to entities (fbids)
- A framework to build the index from other persistent data and incremental updates
- A framework to retrieve entities from the index based on various constraints on attributes
Suppose David’s friend has fbid 1234 and lives in New York and likes Downton Abbey. The index corresponding to my friend will include the mappings:
friend:10003 → 1234
lives-in:111 → 1234
like:222 → 1234
Here, we assume David’s fbid is 10003, and the fbid’s of New York and Downtown Abbey are 111 and 222 respectively. In addition, friend:10003, lives-in:111, and like:222 may map to other users that share these attributes.
Unicorn makes it easy to find nodes that are connected to another node by searching for an edge-type combined with an input node. E.g.:
- David’s friends: friend:10003
- People who live in new york: lives-in:111
- People who like downtown abbey: like:222
This is analogous to the way that keyword search systems work, except that here the keywords describe graph relationships instead of text contained within a document. Think about search systems on the web: most people intuitively know that if you search for “tennyson frost”, you will get all the pages that contain “tennyson” and “frost”. We call this an intersection or “AND” operator. Some power users know that most systems also support “OR” operator, so that “tennyson OR frost” returns pages that contain either tennyson or frost. Because unicorn is implemented in a similar way, it also supports queries like this.
Many queries like this require just one “hop” to get to the set of results, or to traverse one edge to find the nodes that form the search results. The output node is always one edge away from the node that seeded the query. But often there are interesting queries that require doing more than one consecutive hop. Unicorn is unique in that it supports these “multi-hop” queries for finding interesting results in the social graph, and thus makes it possible to connect with new nodes in the graph.
If we take “employers of my friends who live in New York” as an example query, in the first step, our search system fetches the list of nodes that are connected by a specified edge-type to the input nodes. ME –[friend-edge]–> my friends (who live in NY). In the second step, it takes the set of result nodes from the first step and fetches the list of nodes that are connected to those nodes by another specified edge type. [MY FRIENDS FROM NY]–[works-at-edge]–> employers. We call this the “apply” operator, because it takes the first set of results and “applies” a query to these results.
Building an Index for Facebook
To query these entities, we need to have a robust index framework. Unicorn is not only the software that holds our index, but the system that builds the index and the system that retrieves from the index. Unicorn (like all inverted indices) optimizes retrieval performance by spending time during indexing to build optimal retrieval data structures in memory.
Suppose we wish to index the following five users: Mark Zuckerberg (fbid: 4), Randi Zuckerberg (fbid: 13755), Mark David Johnson (fbid: 1001), Randi Johnson (fbid: 5542), and David Johnson (fbid: 10003). The mappings we use are:
mark → 4
zuck → 4
randi → 13755
zuck → 13755
mark → 1001
david → 1001
johnson → 1001
randi → 5542
johnson →5542
david → 10003
johnson → 10003
The following diagram shows this mapping in more detail:

The vertical lines in this diagram are called posting lists – a list of all fbids corresponding to a particular attribute. So the posting list for “mark” contains 4 and 1001. The horizontal lines in this diagram describe entities – so the entity with fbid 4 is indexed by “mark” and “zuck” (fbid 4 has 2 attributes). Posting lists can have as few as one entry and as many as millions of entries, and entities may be indexed with as few as ten attributes and as many as thousands of attributes.
Unicorn supports a query language that allows retrieval of matching entities. Here are some examples of queries:
(term mark):
Matches all entities in the posting list for “mark” – i.e., 4 and 1001.
(and david johnson):
Matches all entities that are in both the posting list for “david” and the posting list for “johnson” – i.e., 1001 and 10003.
(or zuck randi):
Matches all entities that are either in the posting list for “zuck” or in the posting list for “randi” – i.e., 4, 13755, and 5542.
To perform operations (such as “and”) efficiently, the order of entities in each posting list must be the same. For example, they can be ordered by fbid, time of creation of the entity, etc. We prefer to order them by importance (from most important to least important). We use query-independent signals to come up with a numeric value for importance and then order entities by the value. This value is called the static rank of the entity.
Unicorn retrieval expressions may be matched by a large number of entities. Typically, we are not interested in all the entities, but only the most important ones. So along with the retrieval expression, we can also specify a limit on the number of entities to be retrieved. In combination with the static rank, this means we retrieve only the most important entities that match the expression.
Indexing (or the process of building the index) is performed as a combination of map-reduce scripts that collect data from Hive tables, process them, and convert them into the inverted index data structures.
Facebook is a unique data set in that it is constantly changing. There are over 2.5 billion new pieces of content added every day, and more than 2.7 billion likes added every day. This means that in addition to indexing the relatively static data, we need to include the updates in our unicorn index. All changes being made constantly by Facebook users are streamed into the index via a separate live update pipeline to keep the index current to within seconds of these changes.
With the development of Unicorn and launch of Graph Search, we have a unified system supporting the index of the entire Graph. For more detail on how Unicorn works, check out the video of a recent talk by Soren Lassen and Mike Curtiss.








