
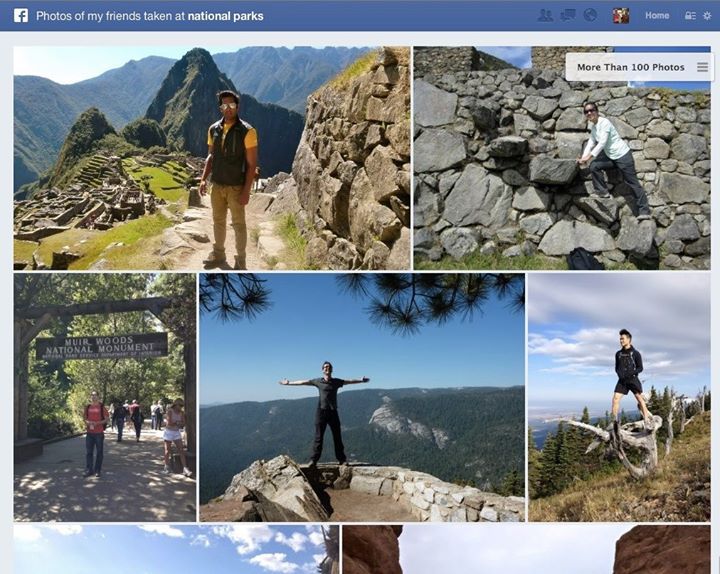
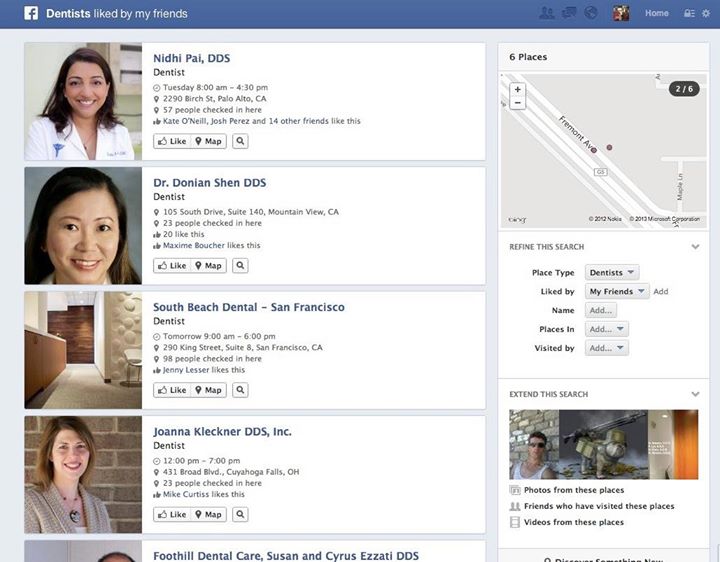
This morning we announced the beta of Graph Search, a new product that lets you explore the content your friends and others have shared with you on Facebook in entirely new ways. With Graph Search, you simply enter phrases such as “My friends who live in San Francisco,” “Photos of my family taken in Copenhagen,” or “Dentists my friends like,” and Facebook quickly displays a page of the content you’ve requested.
Graph Search has been the main focus of Facebook’s search team for more than a year now, but the project’s origin goes back much further than that. In Facebook’s early days, people could search for basic things like friends, groups, and events, but the systems that powered these searches weren’t comprehensive, nor were they able to scale with the site’s growth. As people shared more and more content, we saw that we needed to give them better ways to explore and enjoy those stories and memories. And we knew it was going to get harder and harder the longer we waited.
The challenge
In 2011, Zuck asked the search team to design and build a new system that would recreate the ability to search the entire social graph. This was an interesting challenge because–compared to large document collections like the Web–the data in our databases have significantly more explicit structure than free-flowing text. Therefore, a traditional keyword-based search product might not be the answer.
We debated whether to start by building smaller products targeted at specific use cases like recruitment search or local search. Such products are fairly well understood and could help educate us on the way to more ambitious projects. But in the true spirit of the Hacker Way, we decided to go for bust: could we build a single, structured search mechanism that would allow people to search everything we knew about the social graph at the time, and scale with Facebook’s incredible growth? We had to find out.
The prototype
This project presented two parallel challenges: what would such a product look like, and what infrastructure would we need to build to support it?
For the product part, we discussed and debated, and built several simple prototypes of graphical UIs that allowed users–click-by-click–to build up structured, database-like queries. But they all seemed too complex and not quite up for the full scope of Zuck’s challenge to us.
Then an idea emerged around the title of each page on Facebook. We wanted people to be able to construct their own views of the particular Facebook content they were interested in. If a person simply entered the title of the content they were looking for, could we then build a system that would understand the searcher’s input and find the content for them?
We thought it was particularly beneficial that such a system could be integrated nicely with the site’s existing main search feature: the search field atop each page. People already knew this was the place to search on Facebook, and although search was extremely limited before Graph Search, we still received hundreds of millions of queries every day.
In about a week, a few of us threw together a simple proof-of-concept: a naive, exponential-time ‘parser’ written in Javascript that could mimic the experience we were looking for as long as the searcher input no more than a few tokens. I remember the day we showed Zuck the idea during the summer of 2011. He said, “You will never make that work, but if you can it’ll be awesome.” (Zuck knows how to inspire…)
We of course wanted to take on the challenge, but none of us had built anything remotely like this before. So we hit the books. We combined various parsing techniques to build a substring parser: suppose a user inputs, say, “friends New York” and that we have defined a comprehensive set of all the potential page titles our system can handle. Our parser could then generate exactly the Graph Search titles that contain the user’s input, including things like “friends who live in New York” and “friends who have visited New York.” If we could find a way to appropriately rank those suggested titles for the Graph Search typeahead, we would have a good start.
Another month or so of coding later, we had a prototype that gave us the confidence that we could in fact build the system that we put into beta this morning.
The Infrastructure
In parallel to all this, the search team’s systems engineers went to work on building the necessary infrastructure. Challenge number one: scale. More than 1 billion people use Facebook each month, they have shared more than 240 billion photos on the site, and formed more that 1 trillion connections of thousands of different types. Every day, people share billions of pieces of new content, and Graph Search needs those indexed within seconds of their creation.
Secondly, we owned too much code running too many services already. At Facebook, we move as fast as we can, often building infrastructure targeted at very specific use cases. I believe strongly that the company’s considerable success has depended on this. But it comes at a cost: by the time we started the Graph Search project, the search team was responsible for maintaining three separate search systems backing various search features on the site that we had built over the years. The maintenance burden already had taken up considerable amounts of our limited engineering time, and it seemed ill-advised to add a fourth system to that mix. We desperately needed to consolidate.
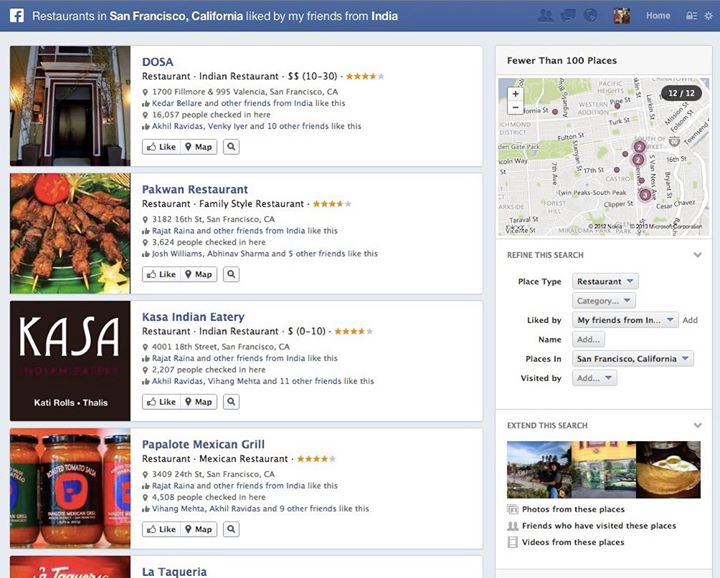
And then of course there was the question of actually answering Graph Search queries. Using traditional information-retrieval systems to mix keyword and structured queries is fairly well understood. But we needed the system also to find answers more than a single connection away, such as “restaurants liked by my friends from India.” Here we were in luck: one of our three existing systems, Unicorn, was designed exactly with this in mind.
The search infra team decided on a two-stage approach: first build out Unicorn to manage all the existing search experiences on the site and then, build out Unicorn further to meet all the requirements of Graph Search. Today, we are far enough along now to launch Graph Search as a beta, but we’re still missing is the ability to index all of the posts and comments people have shared on Facebook–they make up by far the biggest dataset we have for Graph Search and Unicorn. The team will be writing more about this challenge on the engineering blog soon.
Privacy
When you share something on Facebook, you get to decide exactly who can see that content. This, of course, is why Graph Search is such a powerful experience: a lot of what you will find is content that is not public, but content that someone has shared with a limited audience that happens to include you. It is also part of what makes Graph Search an interesting technical challenge for us. The system has to do an extraordinary amount of privacy checking in real time to deliver the experience we want.
One challenge in particular is worth calling out. Consider the relatively simple Graph Search query, “Photos of Facebook employees.” For starters, we make sure that only photos that the owner has shared with the person conducting the search can be seen on the photo results page. But we have also to make sure that each photo features at least one person who has shared with the searcher that they work at Facebook! Otherwise we would implicitly be revealing content that the searcher does not have access to. The more complex the Graph Search query, the more work we need to do to ensure the system returns only content the searcher already has access to.
Launching beta
Toward the end of summer 2012, Graph Search was starting to take shape. By then we had added designers to the team and the product started both looking and feeling quite real. Little by little, colleagues from outside the search team started actually finding real uses for the product, and we began planning when and how to release it to the public.
Personally, I enjoy looking at photos of my girlfriend and me almost every day, which is so easy using Graph Search. And couple of months ago, I used it to find a dentist in town by looking through the ones my friends like. Didn’t hurt at all!
The future
Today’s Graph Search beta is just the beginning. We’re starting with a focus on people, photos, places and interests, but are looking forward to incorporating posts and Open Graph actions, as well as making Graph Search available on mobile and in every language. We’re excited to be able to keep making search more useful, fun and central to how you explore existing connections and make new ones on Facebook.
Over the coming weeks, different search team members will be writing in more depth on the challenges they faced while building their particular components of Graph Search. If you’d like to try out Graph Search during the beta phase that begins today, visit facebook.com/graphsearch and request to be on the wait list.
Lars Rasmussen is the head of engineering for Graph Search.








